 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
Mar 18, 2024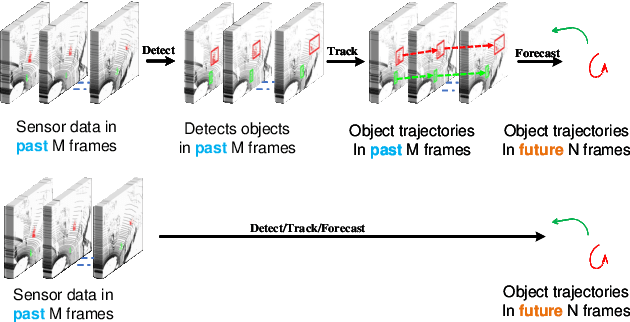
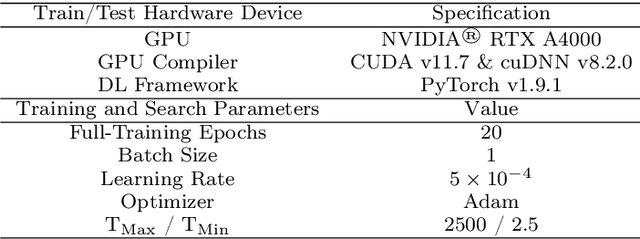
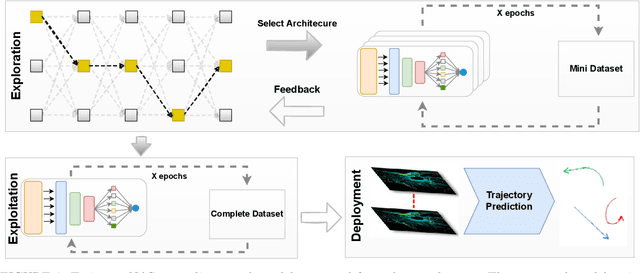

Autonomous driving systems are a rapidly evolving technology that enables driverless car production. Trajectory prediction is a critical component of autonomous driving systems, enabling cars to anticipate the movements of surrounding objects for safe navigation. Trajectory prediction using Lidar point-cloud data performs better than 2D images due to providing 3D information. However, processing point-cloud data is more complicated and time-consuming than 2D images. Hence, state-of-the-art 3D trajectory predictions using point-cloud data suffer from slow and erroneous predictions. This paper introduces TrajectoryNAS, a pioneering method that focuses on utilizing point cloud data for trajectory prediction. By leveraging Neural Architecture Search (NAS), TrajectoryNAS automates the design of trajectory prediction models, encompassing object detection, tracking, and forecasting in a cohesive manner. This approach not only addresses the complex interdependencies among these tasks but also emphasizes the importance of accuracy and efficiency in trajectory modeling. Through empirical studies, TrajectoryNAS demonstrates its effectiveness in enhancing the performance of autonomous driving systems, marking a significant advancement in the field.Experimental results reveal that TrajcetoryNAS yield a minimum of 4.8 higger accuracy and 1.1* lower latency over competing methods on the NuScenes dataset.
Contrastive Learning for Lane Detection via Cross-Similarity
Sep 01, 2023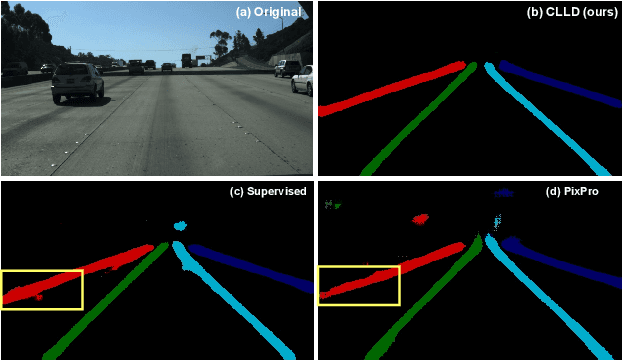
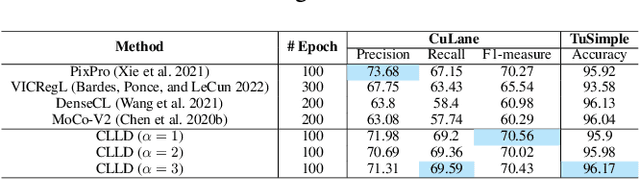
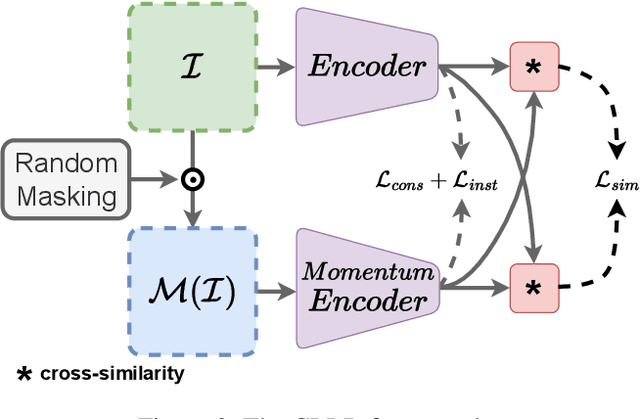
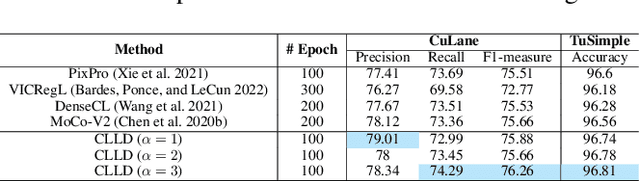
Detecting road lanes is challenging due to intricate markings vulnerable to unfavorable conditions. Lane markings have strong shape priors, but their visibility is easily compromised. Factors like lighting, weather, vehicles, pedestrians, and aging colors challenge the detection. A large amount of data is required to train a lane detection approach that can withstand natural variations caused by low visibility. This is because there are numerous lane shapes and natural variations that exist. Our solution, Contrastive Learning for Lane Detection via cross-similarity (CLLD), is a self-supervised learning method that tackles this challenge by enhancing lane detection models resilience to real-world conditions that cause lane low visibility. CLLD is a novel multitask contrastive learning that trains lane detection approaches to detect lane markings even in low visible situations by integrating local feature contrastive learning (CL) with our new proposed operation cross-similarity. Local feature CL focuses on extracting features for small image parts, which is necessary to localize lane segments, while cross-similarity captures global features to detect obscured lane segments using their surrounding. We enhance cross-similarity by randomly masking parts of input images for augmentation. Evaluated on benchmark datasets, CLLD outperforms state-of-the-art contrastive learning, especially in visibility-impairing conditions like shadows. Compared to supervised learning, CLLD excels in scenarios like shadows and crowded scenes.