 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emotion-Memory Link: Do Memorability Annotations Matter for Intelligent Systems?
Jul 18, 2025Humans have a selective memory, remembering relevant episodes and forgetting the less relevant information. Possessing awareness of event memorability for a user could help intelligent systems in more accurate user modelling, especially for such applications as meeting support systems, memory augmentation, and meeting summarisation. Emotion recognition has been widely studied, since emotions are thought to signal moments of high personal relevance to users. The emotional experience of situations and their memorability have traditionally been considered to be closely tied to one another: moments that are experienced as highly emotional are considered to also be highly memorable. This relationship suggests that emotional annotations could serve as proxies for memorability. However, existing emotion recognition systems rely heavily on third-party annotations, which may not accurately represent the first-person experience of emotional relevance and memorability. This is why, in this study, we empirically examine the relationship between perceived group emotions (Pleasure-Arousal) and group memorability in the context of conversational interactions. Our investigation involves continuous time-based annotations of both emotions and memorability in dynamic, unstructured group settings, approximating conditions of real-world conversational AI applications such as online meeting support systems. Our results show that the observed relationship between affect and memorability annotations cannot be reliably distinguished from what might be expected under random chance. We discuss the implications of this surprising finding for the development and applications of Affective Computing technology. In addition, we contextualise our findings in broader discourses in the Affective Computing and point out important targets for future research efforts.
Indeterminacy in Affective Computing: Considering Meaning and Context in Data Collection Practices
Feb 13, 2025
Automatic Affect Prediction (AAP) uses computational analysis of input data such as text, speech, images, and physiological signals to predict various affective phenomena (e.g., emotions or moods). These models are typically constructed using supervised machine-learning algorithms, which rely heavily on labeled training datasets. In this position paper, we posit that all AAP training data are derived from human Affective Interpretation Processes, resulting in a form of Affective Meaning. Research on human affect indicates a form of complexity that is fundamental to such meaning: it can possess what we refer to here broadly as Qualities of Indeterminacy (QIs) - encompassing Subjectivity (meaning depends on who is interpreting), Uncertainty (lack of confidence regarding meanings' correctness), Ambiguity (meaning contains mutually exclusive concepts) and Vagueness (meaning is situated at different levels in a nested hierarchy). Failing to appropriately consider QIs leads to results incapable of meaningful and reliable predictions. Based on this premise, we argue that a crucial step in adequately addressing indeterminacy in AAP is the development of data collection practices for modeling corpora that involve the systematic consideration of 1) a relevant set of QIs and 2) context for the associated interpretation processes. To this end, we are 1) outlining a conceptual model of AIPs and the QIs associated with the meaning these produce and a conceptual structure of relevant context, supporting understanding of its role. Finally, we use our framework for 2) discussing examples of context-sensitivity-related challenges for addressing QIs in data collection setups. We believe our efforts can stimulate a structured discussion of both the role of aspects of indeterminacy and context in research on AAP, informing the development of better practices for data collection and analysis.
A Valid Self-Report is Never Late, Nor is it Early: On Considering the "Right" Temporal Distance for Assessing Emotional Experience
Jan 27, 2023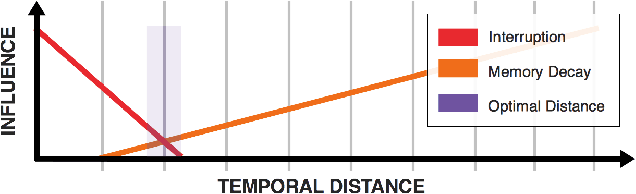
Developing computational models for automatic affect prediction requires valid self-reports about individuals' emotional interpretations of stimuli. In this article, we highlight the important influence of the temporal distance between a stimulus event and the moment when its experience is reported on the provided information's validity. This influence stems from the time-dependent and time-demanding nature of the involved cognitive processes. As such, reports can be collected too late: forgetting is a widely acknowledged challenge for accurate descriptions of past experience. For this reason, methods striving for assessment as early as possible have become increasingly popular. However, here we argue that collection may also occur too early: descriptions about very recent stimuli might be collected before emotional processing has fully converged. Based on these notions, we champion the existence of a temporal distance for each type of stimulus that maximizes the validity of self-reports -- a "right" time. Consequently, we recommend future research to (1) consciously consider the potential influence of temporal distance on affective self-reports when planning data collection, (2) document the temporal distance of affective self-reports wherever possible as part of corpora for computational modelling, and finally (3) and explore the effect of temporal distance on self-reports across different types of stimuli.
A Blast From the Past: Personalizing Predictions of Video-Induced Emotions using Personal Memories as Context
Aug 27, 2020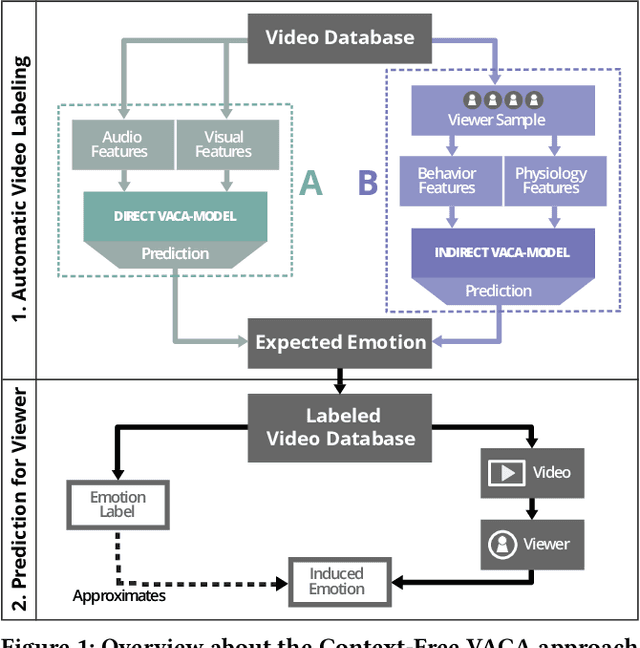
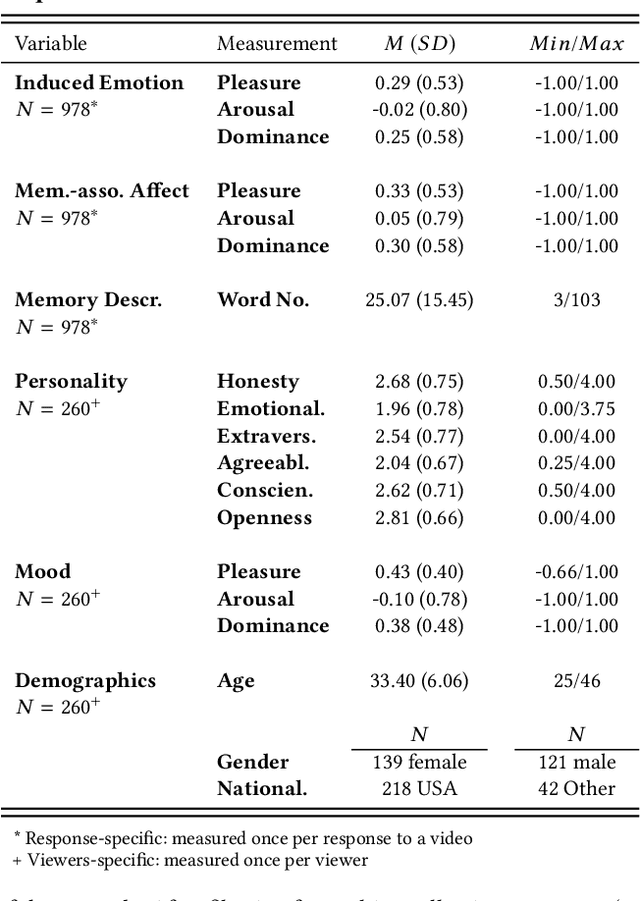
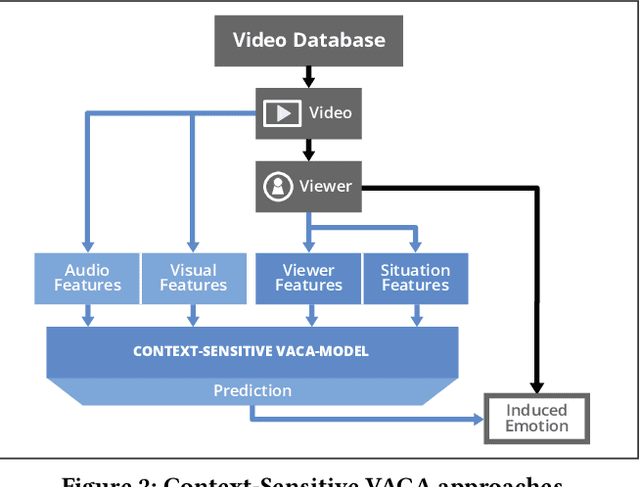

A key challenge in the accurate prediction of viewers' emotional responses to video stimuli in real-world applications is accounting for person- and situation-specific variation. An important contextual influence shaping individuals' subjective experience of a video is the personal memories that it triggers in them. Prior research has found that this memory influence explains more variation in video-induced emotions than other contextual variables commonly used for personalizing predictions, such as viewers' demographics or personality. In this article, we show that (1) automatic analysis of text describing their video-triggered memories can account for variation in viewers' emotional responses, and (2) that combining such an analysis with that of a video's audiovisual content enhances the accuracy of automatic predictions. We discuss the relevance of these findings for improving on state of the art approaches to automated affective video analysis in personalized contexts.