 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEMO: Can Multimodal LLMs Identify Attribute-Modified Objects?
Nov 26, 2024Multimodal Large Language Models (MLLMs) have made notable advances in visual understanding, yet their abilities to recognize objects modified by specific attributes remain an open question. To address this, we explore MLLMs' reasoning capabilities in object recognition, ranging from commonsense to beyond-commonsense scenarios. We introduce a novel benchmark, NEMO, which comprises 900 images of origiNal fruits and their corresponding attributE-MOdified ones; along with a set of 2,700 questions including open-, multiple-choice-, unsolvable types. We assess 26 recent open-sourced and commercial models using our benchmark. The findings highlight pronounced performance gaps in recognizing objects in NEMO and reveal distinct answer preferences across different models. Although stronger vision encoders improve performance, MLLMs still lag behind standalone vision encoders. Interestingly, scaling up the model size does not consistently yield better outcomes, as deeper analysis reveals that larger LLMs can weaken vision encoders during fine-tuning. These insights shed light on critical limitations in current MLLMs and suggest potential pathways toward developing more versatile and resilient multimodal models.
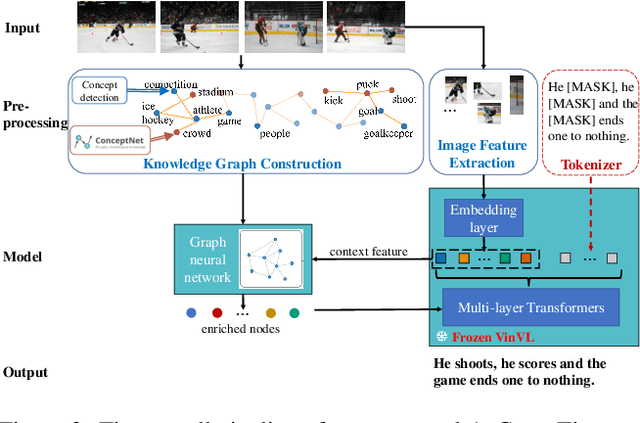
EVCap: Retrieval-Augmented Image Captioning with External Visual-Name Memory for Open-World Comprehension
Nov 27, 2023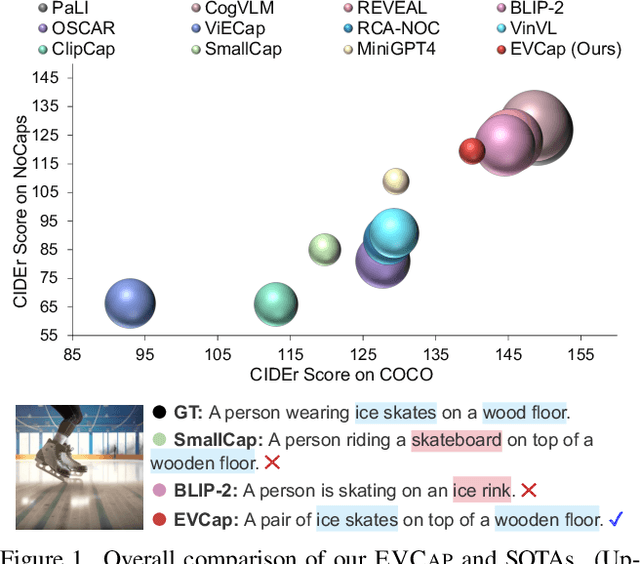



Large language models (LLMs)-based image captioning has the capability of describing objects not explicitly observed in training data; yet novel objects occur frequently, necessitating the requirement of sustaining up-to-date object knowledge for open-world comprehension. Instead of relying on large amounts of data and scaling up network parameters, we introduce a highly effective retrieval-augmented image captioning method that prompts LLMs with object names retrieved from External Visual--name memory (EVCap). We build ever-changing object knowledge memory using objects' visuals and names, enabling us to (i) update the memory at a minimal cost and (ii) effortlessly augment LLMs with retrieved object names utilizing a lightweight and fast-to-train model. Our model, which was trained only on the COCO dataset, can be adapted to out-domain data without additional fine-tuning or retraining. Our comprehensive experiments conducted on various benchmarks and synthetic commonsense-violating data demonstrate that EVCap, comprising solely 3.97M trainable parameters, exhibits superior performance compared to other methods of equivalent model size scale. Notably, it achieves competitive performance against specialist SOTAs with an enormous number of parameters. Our code is available at https://jiaxuan-li.github.io/EVCap.
A-CAP: Anticipation Captioning with Commonsense Knowledge
Apr 13, 2023
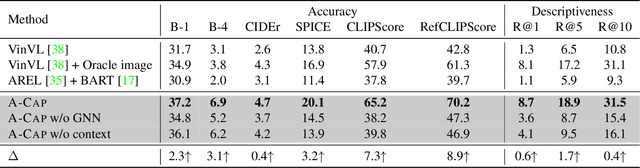

Humans possess the capacity to reason about the future based on a sparse collection of visual cues acquired over time. In order to emulate this ability, we introduce a novel task called Anticipation Captioning, which generates a caption for an unseen oracle image using a sparsely temporally-ordered set of images. To tackle this new task, we propose a model called A-CAP, which incorporates commonsense knowledge into a pre-trained vision-language model, allowing it to anticipate the caption. Through both qualitative and quantitative evaluations on a customized visual storytelling dataset, A-CAP outperforms other image captioning methods and establishes a strong baseline for anticipation captioning. We also address the challenges inherent in this task.
TextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
SketchANIMAR: Sketch-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching, and creating more diverse datasets to evaluate retrieval performance.
NOC-REK: Novel Object Captioning with Retrieved Vocabulary from External Knowledge
Mar 28, 2022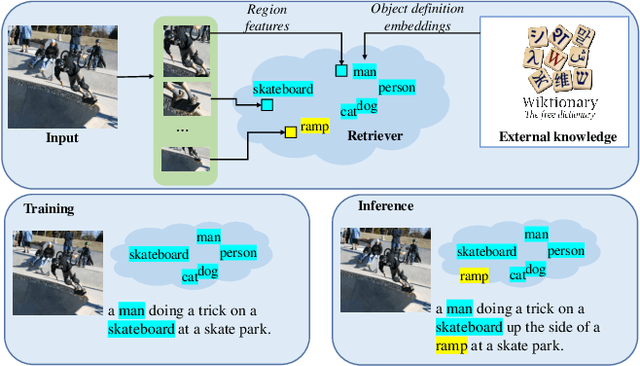
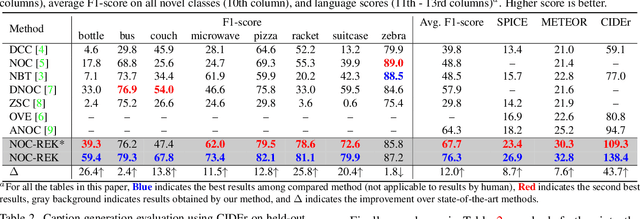
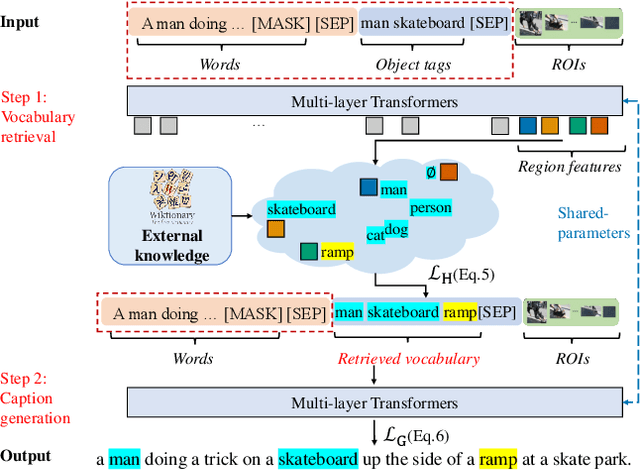

Novel object captioning aims at describing objects absent from training data, with the key ingredient being the provision of object vocabulary to the model. Although existing methods heavily rely on an object detection model, we view the detection step as vocabulary retrieval from an external knowledge in the form of embeddings for any object's definition from Wiktionary, where we use in the retrieval image region features learned from a transformers model. We propose an end-to-end Novel Object Captioning with Retrieved vocabulary from External Knowledge method (NOC-REK), which simultaneously learns vocabulary retrieval and caption generation, successfully describing novel objects outside of the training dataset. Furthermore, our model eliminates the requirement for model retraining by simply updating the external knowledge whenever a novel object appears. Our comprehensive experiments on held-out COCO and Nocaps datasets show that our NOC-REK is considerably effective against SOTAs.
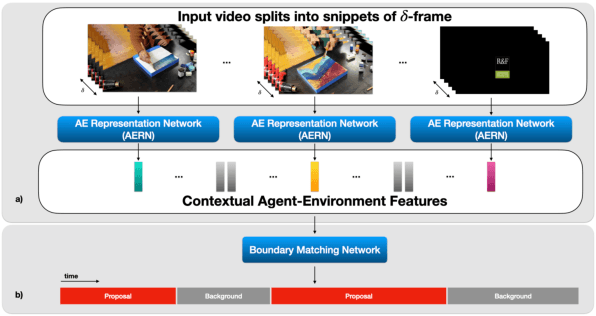
ABN: Agent-Aware Boundary Networks for Temporal Action Proposal Generation
Mar 16, 2022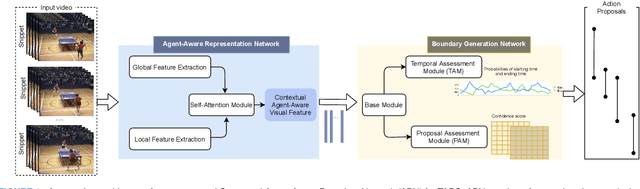
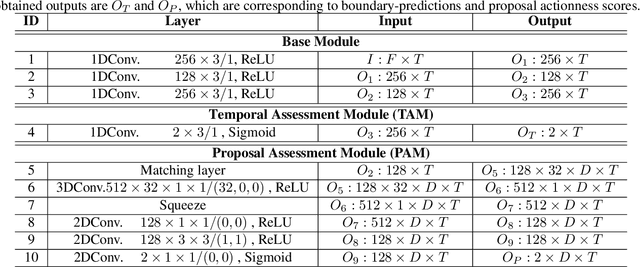
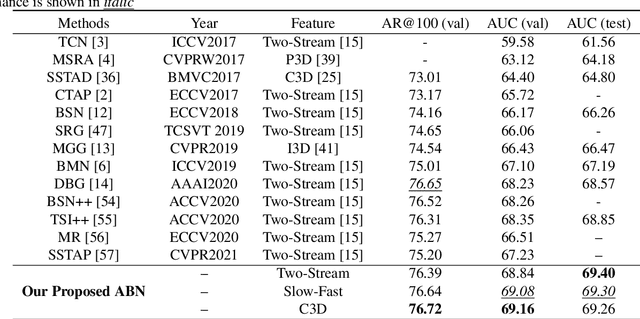
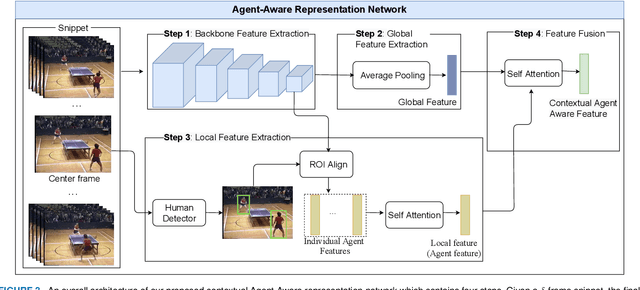
Temporal action proposal generation (TAPG) aims to estimate temporal intervals of actions in untrimmed videos, which is a challenging yet plays an important role in many tasks of video analysis and understanding. Despite the great achievement in TAPG, most existing works ignore the human perception of interaction between agents and the surrounding environment by applying a deep learning model as a black-box to the untrimmed videos to extract video visual representation. Therefore, it is beneficial and potentially improve the performance of TAPG if we can capture these interactions between agents and the environment. In this paper, we propose a novel framework named Agent-Aware Boundary Network (ABN), which consists of two sub-networks (i) an Agent-Aware Representation Network to obtain both agent-agent and agents-environment relationships in the video representation, and (ii) a Boundary Generation Network to estimate the confidence score of temporal intervals. In the Agent-Aware Representation Network, the interactions between agents are expressed through local pathway, which operates at a local level to focus on the motions of agents whereas the overall perception of the surroundings are expressed through global pathway, which operates at a global level to perceive the effects of agents-environment. Comprehensive evaluations on 20-action THUMOS-14 and 200-action ActivityNet-1.3 datasets with different backbone networks (i.e C3D, SlowFast and Two-Stream) show that our proposed ABN robustly outperforms state-of-the-art methods regardless of the employed backbone network on TAPG. We further examine the proposal quality by leveraging proposals generated by our method onto temporal action detection (TAD) frameworks and evaluate their detection performances. The source code can be found in this URL https://github.com/vhvkhoa/TAPG-AgentEnvNetwork.git.
PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression
Mar 16, 2022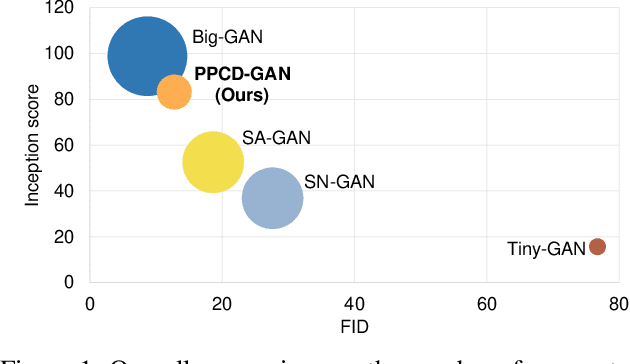
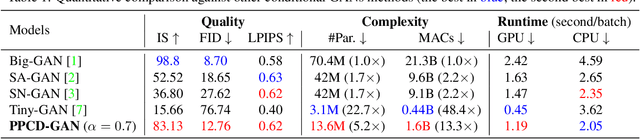
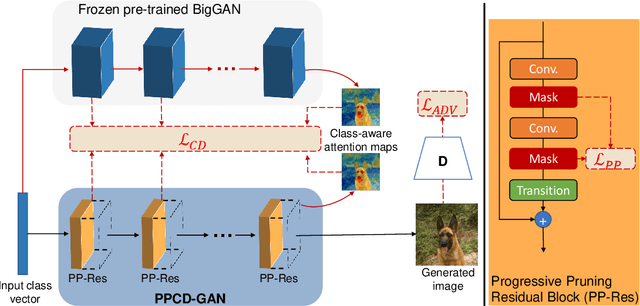
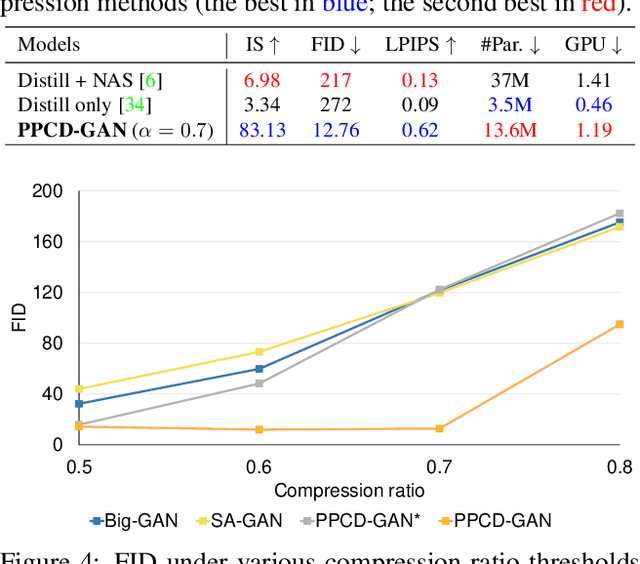
We push forward neural network compression research by exploiting a novel challenging task of large-scale conditional generative adversarial networks (GANs) compression. To this end, we propose a gradually shrinking GAN (PPCD-GAN) by introducing progressive pruning residual block (PP-Res) and class-aware distillation. The PP-Res is an extension of the conventional residual block where each convolutional layer is followed by a learnable mask layer to progressively prune network parameters as training proceeds. The class-aware distillation, on the other hand, enhances the stability of training by transferring immense knowledge from a well-trained teacher model through instructive attention maps. We train the pruning and distillation processes simultaneously on a well-known GAN architecture in an end-to-end manner. After training, all redundant parameters as well as the mask layers are discarded, yielding a lighter network while retaining the performance. We comprehensively illustrate, on ImageNet 128x128 dataset, PPCD-GAN reduces up to 5.2x (81%) parameters against state-of-the-arts while keeping better performance.
Agent-Environment Network for Temporal Action Proposal Generation
Jul 17, 2021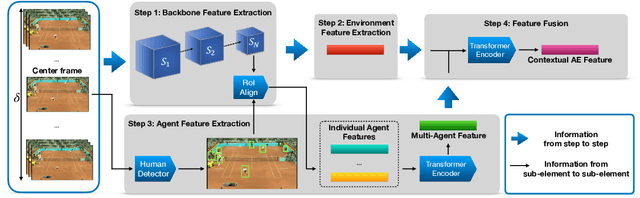

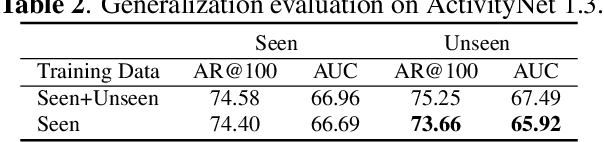
Temporal action proposal generation is an essential and challenging task that aims at localizing temporal intervals containing human actions in untrimmed videos. Most of existing approaches are unable to follow the human cognitive process of understanding the video context due to lack of attention mechanism to express the concept of an action or an agent who performs the action or the interaction between the agent and the environment. Based on the action definition that a human, known as an agent, interacts with the environment and performs an action that affects the environment, we propose a contextual Agent-Environment Network. Our proposed contextual AEN involves (i) agent pathway, operating at a local level to tell about which humans/agents are acting and (ii) environment pathway operating at a global level to tell about how the agents interact with the environment. Comprehensive evaluations on 20-action THUMOS-14 and 200-action ActivityNet-1.3 datasets with different backbone networks, i.e C3D and SlowFast, show that our method robustly exhibits outperformance against state-of-the-art methods regardless of the employed backbone network.
Anabranch Network for Camouflaged Object Segmentation
May 20, 2021
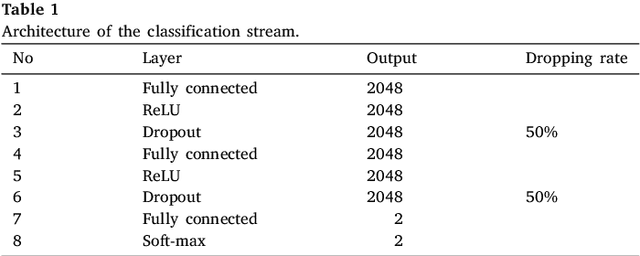

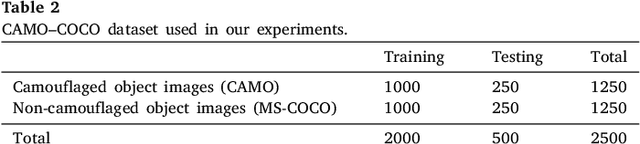
Camouflaged objects attempt to conceal their texture into the background and discriminating them from the background is hard even for human beings. The main objective of this paper is to explore the camouflaged object segmentation problem, namely, segmenting the camouflaged object(s) for a given image. This problem has not been well studied in spite of a wide range of potential applications including the preservation of wild animals and the discovery of new species, surveillance systems, search-and-rescue missions in the event of natural disasters such as earthquakes, floods or hurricanes. This paper addresses a new challenging problem of camouflaged object segmentation. To address this problem, we provide a new image dataset of camouflaged objects for benchmarking purposes. In addition, we propose a general end-to-end network, called the Anabranch Network, that leverages both classification and segmentation tasks. Different from existing networks for segmentation, our proposed network possesses the second branch for classification to predict the probability of containing camouflaged object(s) in an image, which is then fused into the main branch for segmentation to boost up the segmentation accuracy. Extensive experiments conducted on the newly built dataset demonstrate the effectiveness of our network using various fully convolutional networks. \url{https://sites.google.com/view/ltnghia/research/camo}
* Published in CVIU 2019. Project page: https://sites.google.com/view/ltnghia/research/camo