 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR.I.P.: A Simple Black-box Attack on Continual Test-time Adaptation
Dec 02, 2024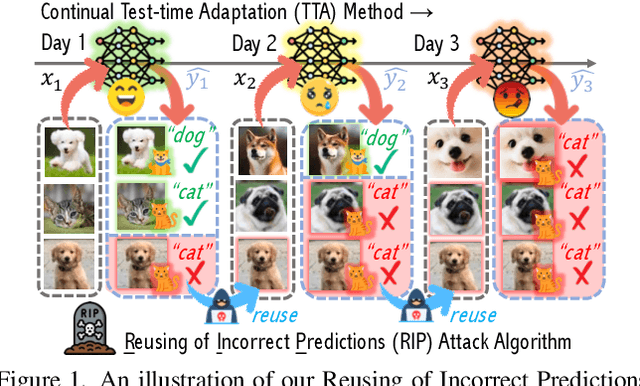

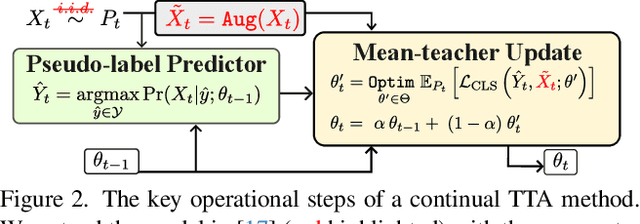

Test-time adaptation (TTA) has emerged as a promising solution to tackle the continual domain shift in machine learning by allowing model parameters to change at test time, via self-supervised learning on unlabeled testing data. At the same time, it unfortunately opens the door to unforeseen vulnerabilities for degradation over time. Through a simple theoretical continual TTA model, we successfully identify a risk in the sampling process of testing data that could easily degrade the performance of a continual TTA model. We name this risk as Reusing of Incorrect Prediction (RIP) that TTA attackers can employ or as a result of the unintended query from general TTA users. The risk posed by RIP is also highly realistic, as it does not require prior knowledge of model parameters or modification of testing samples. This simple requirement makes RIP as the first black-box TTA attack algorithm that stands out from existing white-box attempts. We extensively benchmark the performance of the most recent continual TTA approaches when facing the RIP attack, providing insights on its success, and laying out potential roadmaps that could enhance the resilience of future continual TTA systems.
Persistent Test-time Adaptation in Episodic Testing Scenarios
Nov 30, 2023Current test-time adaptation (TTA) approaches aim to adapt to environments that change continuously. Yet, when the environments not only change but also recur in a correlated manner over time, such as in the case of day-night surveillance cameras, it is unclear whether the adaptability of these methods is sustained after a long run. This study aims to examine the error accumulation of TTA models when they are repeatedly exposed to previous testing environments, proposing a novel testing setting called episodic TTA. To study this phenomenon, we design a simulation of TTA process on a simple yet representative $\epsilon$-perturbed Gaussian Mixture Model Classifier and derive the theoretical findings revealing the dataset- and algorithm-dependent factors that contribute to the gradual degeneration of TTA methods through time. Our investigation has led us to propose a method, named persistent TTA (PeTTA). PeTTA senses the model divergence towards a collapsing and adjusts the adaptation strategy of TTA, striking a balance between two primary objectives: adaptation and preventing model collapse. The stability of PeTTA in the face of episodic TTA scenarios has been demonstrated through a set of comprehensive experiments on various benchmarks.
EVCap: Retrieval-Augmented Image Captioning with External Visual-Name Memory for Open-World Comprehension
Nov 27, 2023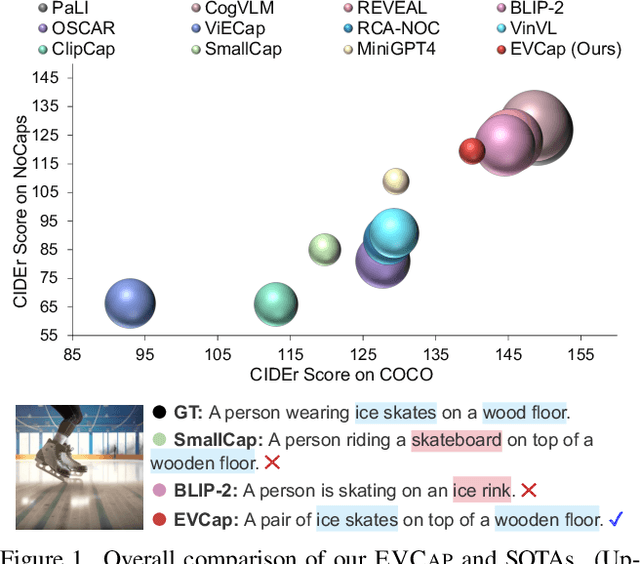



Large language models (LLMs)-based image captioning has the capability of describing objects not explicitly observed in training data; yet novel objects occur frequently, necessitating the requirement of sustaining up-to-date object knowledge for open-world comprehension. Instead of relying on large amounts of data and scaling up network parameters, we introduce a highly effective retrieval-augmented image captioning method that prompts LLMs with object names retrieved from External Visual--name memory (EVCap). We build ever-changing object knowledge memory using objects' visuals and names, enabling us to (i) update the memory at a minimal cost and (ii) effortlessly augment LLMs with retrieved object names utilizing a lightweight and fast-to-train model. Our model, which was trained only on the COCO dataset, can be adapted to out-domain data without additional fine-tuning or retraining. Our comprehensive experiments conducted on various benchmarks and synthetic commonsense-violating data demonstrate that EVCap, comprising solely 3.97M trainable parameters, exhibits superior performance compared to other methods of equivalent model size scale. Notably, it achieves competitive performance against specialist SOTAs with an enormous number of parameters. Our code is available at https://jiaxuan-li.github.io/EVCap.
Partition-and-Debias: Agnostic Biases Mitigation via A Mixture of Biases-Specific Experts
Aug 19, 2023Bias mitigation in image classification has been widely researched, and existing methods have yielded notable results. However, most of these methods implicitly assume that a given image contains only one type of known or unknown bias, failing to consider the complexities of real-world biases. We introduce a more challenging scenario, agnostic biases mitigation, aiming at bias removal regardless of whether the type of bias or the number of types is unknown in the datasets. To address this difficult task, we present the Partition-and-Debias (PnD) method that uses a mixture of biases-specific experts to implicitly divide the bias space into multiple subspaces and a gating module to find a consensus among experts to achieve debiased classification. Experiments on both public and constructed benchmarks demonstrated the efficacy of the PnD. Code is available at: https://github.com/Jiaxuan-Li/PnD.
Revisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023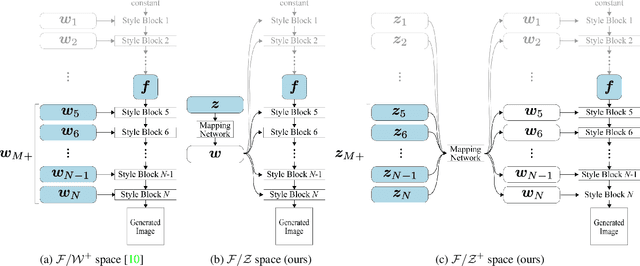


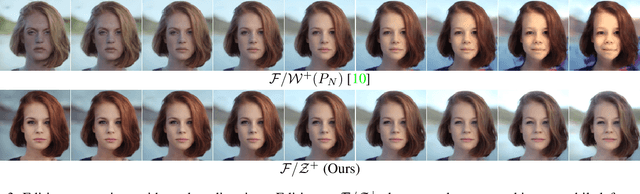
The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
Soft Curriculum for Learning Conditional GANs with Noisy-Labeled and Uncurated Unlabeled Data
Jul 17, 2023Label-noise or curated unlabeled data is used to compensate for the assumption of clean labeled data in training the conditional generative adversarial network; however, satisfying such an extended assumption is occasionally laborious or impractical. As a step towards generative modeling accessible to everyone, we introduce a novel conditional image generation framework that accepts noisy-labeled and uncurated unlabeled data during training: (i) closed-set and open-set label noise in labeled data and (ii) closed-set and open-set unlabeled data. To combat it, we propose soft curriculum learning, which assigns instance-wise weights for adversarial training while assigning new labels for unlabeled data and correcting wrong labels for labeled data. Unlike popular curriculum learning, which uses a threshold to pick the training samples, our soft curriculum controls the effect of each training instance by using the weights predicted by the auxiliary classifier, resulting in the preservation of useful samples while ignoring harmful ones. Our experiments show that our approach outperforms existing semi-supervised and label-noise robust methods in terms of both quantitative and qualitative performance. In particular, the proposed approach is able to match the performance of (semi-) supervised GANs even with less than half the labeled data.
Balancing Reconstruction and Editing Quality of GAN Inversion for Real Image Editing with StyleGAN Prior Latent Space
May 31, 2023The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and $\mathcal{Z}^+$ and integrate them into seminal GAN inversion methods to improve editing quality. Besides faithful reconstruction, our extensions achieve sophisticated editing quality with the aid of the StyleGAN prior. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
A-CAP: Anticipation Captioning with Commonsense Knowledge
Apr 13, 2023
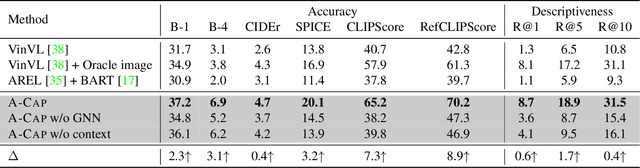
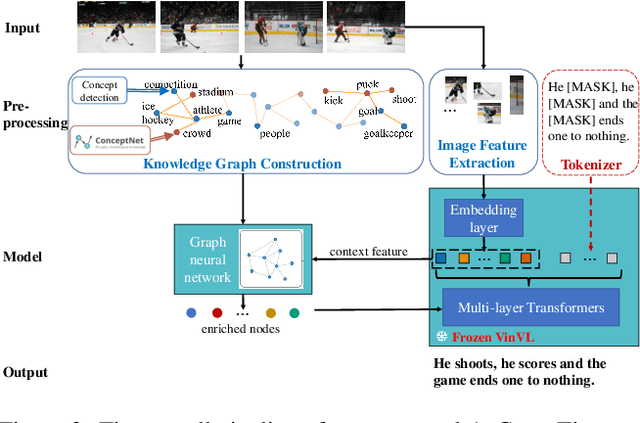

Humans possess the capacity to reason about the future based on a sparse collection of visual cues acquired over time. In order to emulate this ability, we introduce a novel task called Anticipation Captioning, which generates a caption for an unseen oracle image using a sparsely temporally-ordered set of images. To tackle this new task, we propose a model called A-CAP, which incorporates commonsense knowledge into a pre-trained vision-language model, allowing it to anticipate the caption. Through both qualitative and quantitative evaluations on a customized visual storytelling dataset, A-CAP outperforms other image captioning methods and establishes a strong baseline for anticipation captioning. We also address the challenges inherent in this task.
StoryER: Automatic Story Evaluation via Ranking, Rating and Reasoning
Oct 16, 2022
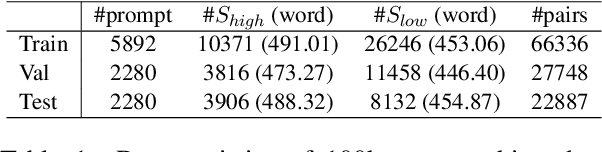
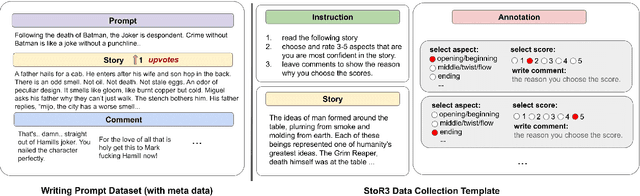
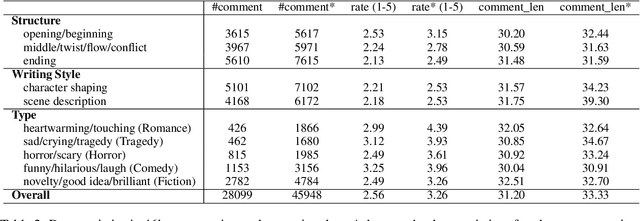
Existing automatic story evaluation methods place a premium on story lexical level coherence, deviating from human preference. We go beyond this limitation by considering a novel \textbf{Story} \textbf{E}valuation method that mimics human preference when judging a story, namely \textbf{StoryER}, which consists of three sub-tasks: \textbf{R}anking, \textbf{R}ating and \textbf{R}easoning. Given either a machine-generated or a human-written story, StoryER requires the machine to output 1) a preference score that corresponds to human preference, 2) specific ratings and their corresponding confidences and 3) comments for various aspects (e.g., opening, character-shaping). To support these tasks, we introduce a well-annotated dataset comprising (i) 100k ranked story pairs; and (ii) a set of 46k ratings and comments on various aspects of the story. We finetune Longformer-Encoder-Decoder (LED) on the collected dataset, with the encoder responsible for preference score and aspect prediction and the decoder for comment generation. Our comprehensive experiments result in a competitive benchmark for each task, showing the high correlation to human preference. In addition, we have witnessed the joint learning of the preference scores, the aspect ratings, and the comments brings gain in each single task. Our dataset and benchmarks are publicly available to advance the research of story evaluation tasks.\footnote{Dataset and pre-trained model demo are available at anonymous website \url{http://storytelling-lab.com/eval} and \url{https://github.com/sairin1202/StoryER}}
OSSGAN: Open-Set Semi-Supervised Image Generation
Apr 29, 2022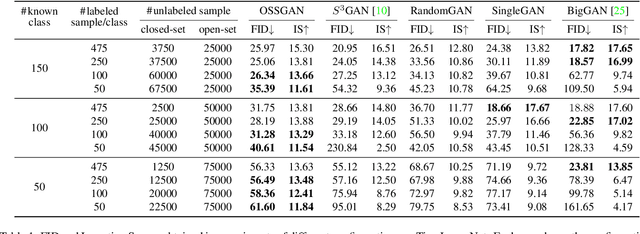
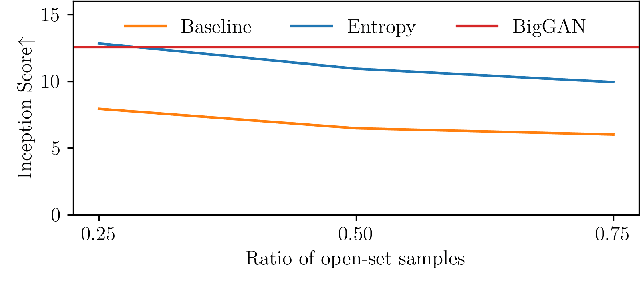

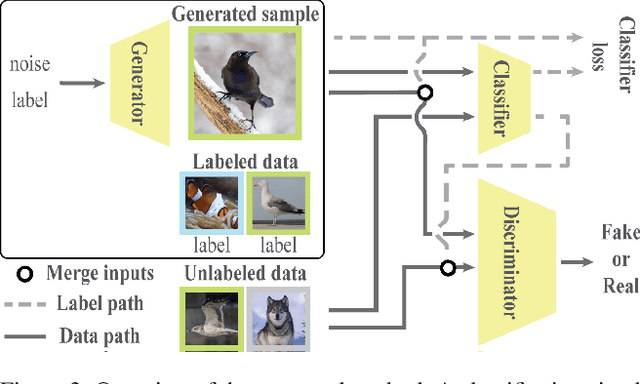
We introduce a challenging training scheme of conditional GANs, called open-set semi-supervised image generation, where the training dataset consists of two parts: (i) labeled data and (ii) unlabeled data with samples belonging to one of the labeled data classes, namely, a closed-set, and samples not belonging to any of the labeled data classes, namely, an open-set. Unlike the existing semi-supervised image generation task, where unlabeled data only contain closed-set samples, our task is more general and lowers the data collection cost in practice by allowing open-set samples to appear. Thanks to entropy regularization, the classifier that is trained on labeled data is able to quantify sample-wise importance to the training of cGAN as confidence, allowing us to use all samples in unlabeled data. We design OSSGAN, which provides decision clues to the discriminator on the basis of whether an unlabeled image belongs to one or none of the classes of interest, smoothly integrating labeled and unlabeled data during training. The results of experiments on Tiny ImageNet and ImageNet show notable improvements over supervised BigGAN and semi-supervised methods. Our code is available at https://github.com/raven38/OSSGAN.