 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Human-like Autonomous Driving: A Survey
Jul 27, 2024



Large Language Models (LLMs), AI models trained on massive text corpora with remarkable language understanding and generation capabilities, are transforming the field of Autonomous Driving (AD). As AD systems evolve from rule-based and optimization-based methods to learning-based techniques like deep reinforcement learning, they are now poised to embrace a third and more advanced category: knowledge-based AD empowered by LLMs. This shift promises to bring AD closer to human-like AD. However, integrating LLMs into AD systems poses challenges in real-time inference, safety assurance, and deployment costs. This survey provides a comprehensive and critical review of recent progress in leveraging LLMs for AD, focusing on their applications in modular AD pipelines and end-to-end AD systems. We highlight key advancements, identify pressing challenges, and propose promising research directions to bridge the gap between LLMs and AD, thereby facilitating the development of more human-like AD systems. The survey first introduces LLMs' key features and common training schemes, then delves into their applications in modular AD pipelines and end-to-end AD, respectively, followed by discussions on open challenges and future directions. Through this in-depth analysis, we aim to provide insights and inspiration for researchers and practitioners working at the intersection of AI and autonomous vehicles, ultimately contributing to safer, smarter, and more human-centric AD technologies.
Revisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023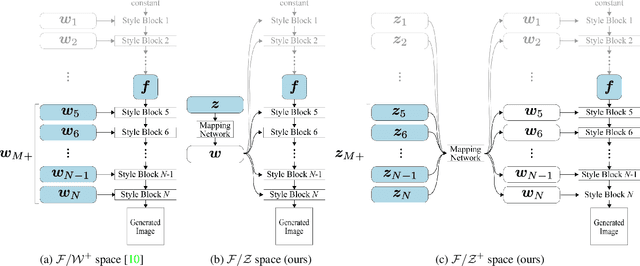


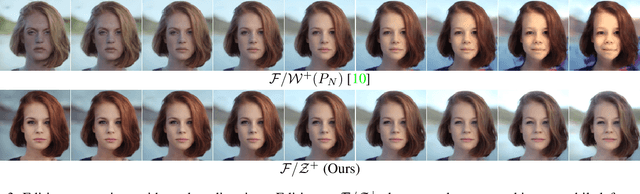
The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
Soft Curriculum for Learning Conditional GANs with Noisy-Labeled and Uncurated Unlabeled Data
Jul 17, 2023Label-noise or curated unlabeled data is used to compensate for the assumption of clean labeled data in training the conditional generative adversarial network; however, satisfying such an extended assumption is occasionally laborious or impractical. As a step towards generative modeling accessible to everyone, we introduce a novel conditional image generation framework that accepts noisy-labeled and uncurated unlabeled data during training: (i) closed-set and open-set label noise in labeled data and (ii) closed-set and open-set unlabeled data. To combat it, we propose soft curriculum learning, which assigns instance-wise weights for adversarial training while assigning new labels for unlabeled data and correcting wrong labels for labeled data. Unlike popular curriculum learning, which uses a threshold to pick the training samples, our soft curriculum controls the effect of each training instance by using the weights predicted by the auxiliary classifier, resulting in the preservation of useful samples while ignoring harmful ones. Our experiments show that our approach outperforms existing semi-supervised and label-noise robust methods in terms of both quantitative and qualitative performance. In particular, the proposed approach is able to match the performance of (semi-) supervised GANs even with less than half the labeled data.
Balancing Reconstruction and Editing Quality of GAN Inversion for Real Image Editing with StyleGAN Prior Latent Space
May 31, 2023The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and $\mathcal{Z}^+$ and integrate them into seminal GAN inversion methods to improve editing quality. Besides faithful reconstruction, our extensions achieve sophisticated editing quality with the aid of the StyleGAN prior. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
OSSGAN: Open-Set Semi-Supervised Image Generation
Apr 29, 2022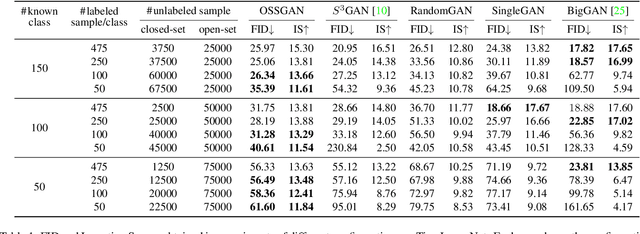
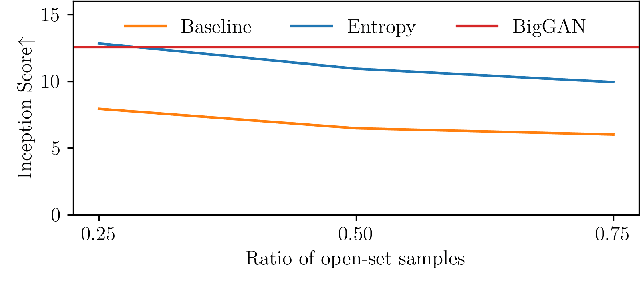

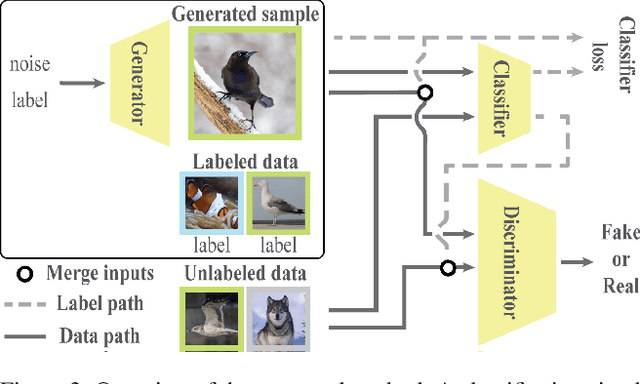
We introduce a challenging training scheme of conditional GANs, called open-set semi-supervised image generation, where the training dataset consists of two parts: (i) labeled data and (ii) unlabeled data with samples belonging to one of the labeled data classes, namely, a closed-set, and samples not belonging to any of the labeled data classes, namely, an open-set. Unlike the existing semi-supervised image generation task, where unlabeled data only contain closed-set samples, our task is more general and lowers the data collection cost in practice by allowing open-set samples to appear. Thanks to entropy regularization, the classifier that is trained on labeled data is able to quantify sample-wise importance to the training of cGAN as confidence, allowing us to use all samples in unlabeled data. We design OSSGAN, which provides decision clues to the discriminator on the basis of whether an unlabeled image belongs to one or none of the classes of interest, smoothly integrating labeled and unlabeled data during training. The results of experiments on Tiny ImageNet and ImageNet show notable improvements over supervised BigGAN and semi-supervised methods. Our code is available at https://github.com/raven38/OSSGAN.