 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DConvCaps: 3DUnet with Convolutional Capsule Encoder for Medical Image Segmentation
May 19, 2022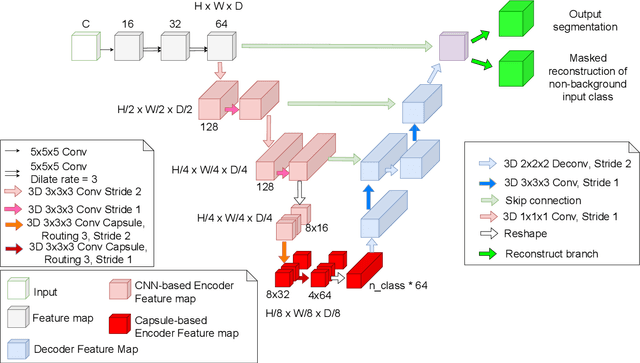

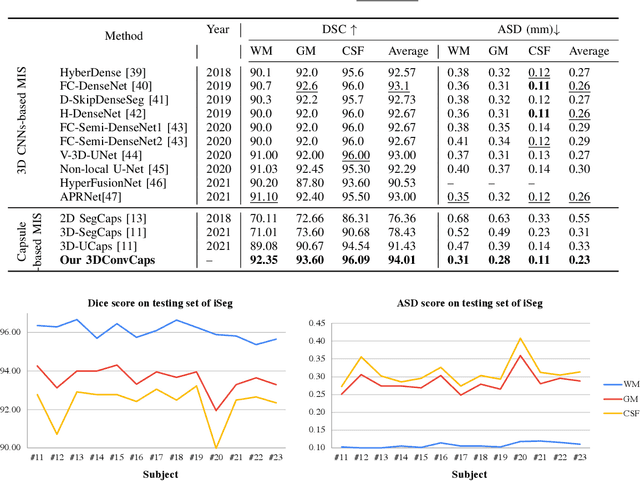

Convolutional Neural Networks (CNNs) have achieved promising results in medical image segmentation. However, CNNs require lots of training data and are incapable of handling pose and deformation of objects. Furthermore, their pooling layers tend to discard important information such as positions as well as CNNs are sensitive to rotation and affine transformation. Capsule network is a recent new architecture that has achieved better robustness in part-whole representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as digit classification and object segmentation. In this paper, we propose a 3D encoder-decoder network with Convolutional Capsule Encoder (called 3DConvCaps) to learn lower-level features (short-range attention) with convolutional layers while modeling the higher-level features (long-range dependence) with capsule layers. Our experiments on multiple datasets including iSeg-2017, Hippocampus, and Cardiac demonstrate that our 3D 3DConvCaps network considerably outperforms previous capsule networks and 3D-UNets. We further conduct ablation studies of network efficiency and segmentation performance under various configurations of convolution layers and capsule layers at both contracting and expanding paths.
Meta-Learning of NAS for Few-shot Learning in Medical Image Applications
Mar 16, 2022



Deep learning methods have been successful in solving tasks in machine learning and have made breakthroughs in many sectors owing to their ability to automatically extract features from unstructured data. However, their performance relies on manual trial-and-error processes for selecting an appropriate network architecture, hyperparameters for training, and pre-/post-procedures. Even though it has been shown that network architecture plays a critical role in learning feature representation feature from data and the final performance, searching for the best network architecture is computationally intensive and heavily relies on researchers' experience. Automated machine learning (AutoML) and its advanced techniques i.e. Neural Architecture Search (NAS) have been promoted to address those limitations. Not only in general computer vision tasks, but NAS has also motivated various applications in multiple areas including medical imaging. In medical imaging, NAS has significant progress in improving the accuracy of image classification, segmentation, reconstruction, and more. However, NAS requires the availability of large annotated data, considerable computation resources, and pre-defined tasks. To address such limitations, meta-learning has been adopted in the scenarios of few-shot learning and multiple tasks. In this book chapter, we first present a brief review of NAS by discussing well-known approaches in search space, search strategy, and evaluation strategy. We then introduce various NAS approaches in medical imaging with different applications such as classification, segmentation, detection, reconstruction, etc. Meta-learning in NAS for few-shot learning and multiple tasks is then explained. Finally, we describe several open problems in NAS.
CapsNet for Medical Image Segmentation
Mar 16, 2022

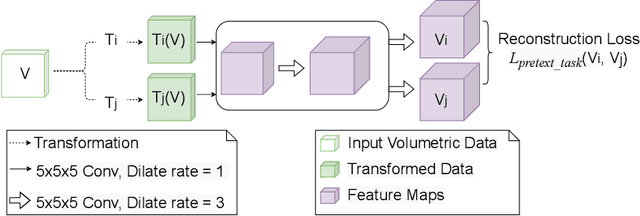
Convolutional Neural Networks (CNNs) have been successful in solving tasks in computer vision including medical image segmentation due to their ability to automatically extract features from unstructured data. However, CNNs are sensitive to rotation and affine transformation and their success relies on huge-scale labeled datasets capturing various input variations. This network paradigm has posed challenges at scale because acquiring annotated data for medical segmentation is expensive, and strict privacy regulations. Furthermore, visual representation learning with CNNs has its own flaws, e.g., it is arguable that the pooling layer in traditional CNNs tends to discard positional information and CNNs tend to fail on input images that differ in orientations and sizes. Capsule network (CapsNet) is a recent new architecture that has achieved better robustness in representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as classification, recognition, segmentation, and natural language processing. Different from CNNs, which result in scalar outputs, CapsNet returns vector outputs, which aim to preserve the part-whole relationships. In this work, we first introduce the limitations of CNNs and fundamentals of CapsNet. We then provide recent developments of CapsNet for the task of medical image segmentation. We finally discuss various effective network architectures to implement a CapsNet for both 2D images and 3D volumetric medical image segmentation.
Agent-Environment Network for Temporal Action Proposal Generation
Jul 17, 2021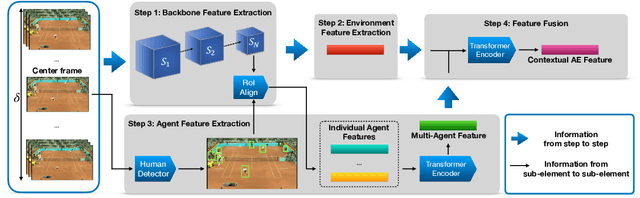

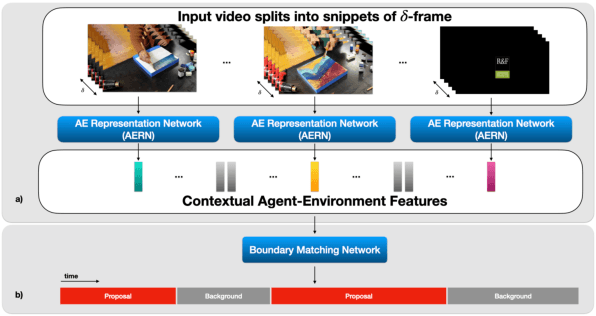
Temporal action proposal generation is an essential and challenging task that aims at localizing temporal intervals containing human actions in untrimmed videos. Most of existing approaches are unable to follow the human cognitive process of understanding the video context due to lack of attention mechanism to express the concept of an action or an agent who performs the action or the interaction between the agent and the environment. Based on the action definition that a human, known as an agent, interacts with the environment and performs an action that affects the environment, we propose a contextual Agent-Environment Network. Our proposed contextual AEN involves (i) agent pathway, operating at a local level to tell about which humans/agents are acting and (ii) environment pathway operating at a global level to tell about how the agents interact with the environment. Comprehensive evaluations on 20-action THUMOS-14 and 200-action ActivityNet-1.3 datasets with different backbone networks, i.e C3D and SlowFast, show that our method robustly exhibits outperformance against state-of-the-art methods regardless of the employed backbone network.