 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DConvCaps: 3DUnet with Convolutional Capsule Encoder for Medical Image Segmentation
Paper and Code
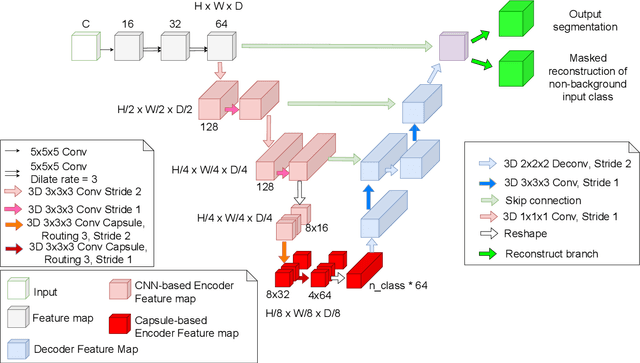

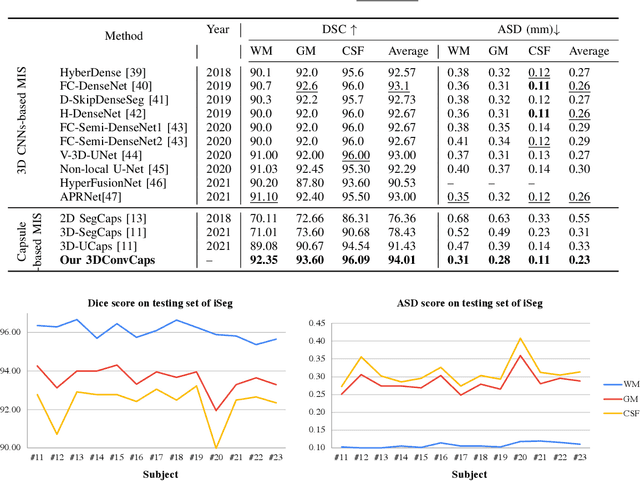

Convolutional Neural Networks (CNNs) have achieved promising results in medical image segmentation. However, CNNs require lots of training data and are incapable of handling pose and deformation of objects. Furthermore, their pooling layers tend to discard important information such as positions as well as CNNs are sensitive to rotation and affine transformation. Capsule network is a recent new architecture that has achieved better robustness in part-whole representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as digit classification and object segmentation. In this paper, we propose a 3D encoder-decoder network with Convolutional Capsule Encoder (called 3DConvCaps) to learn lower-level features (short-range attention) with convolutional layers while modeling the higher-level features (long-range dependence) with capsule layers. Our experiments on multiple datasets including iSeg-2017, Hippocampus, and Cardiac demonstrate that our 3D 3DConvCaps network considerably outperforms previous capsule networks and 3D-UNets. We further conduct ablation studies of network efficiency and segmentation performance under various configurations of convolution layers and capsule layers at both contracting and expanding paths.