 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGraph: A Unified Framework for Scene Graph-Based Image Generation and Editing
Jan 29, 2026Recent advancements in Generative Artificial Intelligence (GenAI) have significantly enhanced the capabilities of both image generation and editing. However, current approaches often treat these tasks separately, leading to inefficiencies and challenges in maintaining spatial consistency and semantic coherence between generated content and edits. Moreover, a major obstacle is the lack of structured control over object relationships and spatial arrangements. Scene graph-based methods, which represent objects and their interrelationships in a structured format, offer a solution by providing greater control over composition and interactions in both image generation and editing. To address this, we introduce SimGraph, a unified framework that integrates scene graph-based image generation and editing, enabling precise control over object interactions, layouts, and spatial coherence. In particular, our framework integrates token-based generation and diffusion-based editing within a single scene graph-driven model, ensuring high-quality and consistent results. Through extensive experiments, we empirically demonstrate that our approach outperforms existing state-of-the-art methods.
VENUS: Visual Editing with Noise Inversion Using Scene Graphs
Jan 12, 2026State-of-the-art text-based image editing models often struggle to balance background preservation with semantic consistency, frequently resulting either in the synthesis of entirely new images or in outputs that fail to realize the intended edits. In contrast, scene graph-based image editing addresses this limitation by providing a structured representation of semantic entities and their relations, thereby offering improved controllability. However, existing scene graph editing methods typically depend on model fine-tuning, which incurs high computational cost and limits scalability. To this end, we introduce VENUS (Visual Editing with Noise inversion Using Scene graphs), a training-free framework for scene graph-guided image editing. Specifically, VENUS employs a split prompt conditioning strategy that disentangles the target object of the edit from its background context, while simultaneously leveraging noise inversion to preserve fidelity in unedited regions. Moreover, our proposed approach integrates scene graphs extracted from multimodal large language models with diffusion backbones, without requiring any additional training. Empirically, VENUS substantially improves both background preservation and semantic alignment on PIE-Bench, increasing PSNR from 22.45 to 24.80, SSIM from 0.79 to 0.84, and reducing LPIPS from 0.100 to 0.070 relative to the state-of-the-art scene graph editing model (SGEdit). In addition, VENUS enhances semantic consistency as measured by CLIP similarity (24.97 vs. 24.19). On EditVal, VENUS achieves the highest fidelity with a 0.87 DINO score and, crucially, reduces per-image runtime from 6-10 minutes to only 20-30 seconds. Beyond scene graph-based editing, VENUS also surpasses strong text-based editing baselines such as LEDIT++ and P2P+DirInv, thereby demonstrating consistent improvements across both paradigms.
SATURN: Autoregressive Image Generation Guided by Scene Graphs
Aug 20, 2025State-of-the-art text-to-image models excel at photorealistic rendering but often struggle to capture the layout and object relationships implied by complex prompts. Scene graphs provide a natural structural prior, yet previous graph-guided approaches have typically relied on heavy GAN or diffusion pipelines, which lag behind modern autoregressive architectures in both speed and fidelity. We introduce SATURN (Structured Arrangement of Triplets for Unified Rendering Networks), a lightweight extension to VAR-CLIP that translates a scene graph into a salience-ordered token sequence, enabling a frozen CLIP-VQ-VAE backbone to interpret graph structure while fine-tuning only the VAR transformer. On the Visual Genome dataset, SATURN reduces FID from 56.45% to 21.62% and increases the Inception Score from 16.03 to 24.78, outperforming prior methods such as SG2IM and SGDiff without requiring extra modules or multi-stage training. Qualitative results further confirm improvements in object count fidelity and spatial relation accuracy, showing that SATURN effectively combines structural awareness with state-of-the-art autoregressive fidelity.
SHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Aug 12, 2025Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a system's ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, ROOMELSA includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. These findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
ACM Multimedia Grand Challenge on ENT Endoscopy Analysis
Aug 06, 2025Automated analysis of endoscopic imagery is a critical yet underdeveloped component of ENT (ear, nose, and throat) care, hindered by variability in devices and operators, subtle and localized findings, and fine-grained distinctions such as laterality and vocal-fold state. In addition to classification, clinicians require reliable retrieval of similar cases, both visually and through concise textual descriptions. These capabilities are rarely supported by existing public benchmarks. To this end, we introduce ENTRep, the ACM Multimedia 2025 Grand Challenge on ENT endoscopy analysis, which integrates fine-grained anatomical classification with image-to-image and text-to-image retrieval under bilingual (Vietnamese and English) clinical supervision. Specifically, the dataset comprises expert-annotated images, labeled for anatomical region and normal or abnormal status, and accompanied by dual-language narrative descriptions. In addition, we define three benchmark tasks, standardize the submission protocol, and evaluate performance on public and private test splits using server-side scoring. Moreover, we report results from the top-performing teams and provide an insight discussion.
HyperGLM: HyperGraph for Video Scene Graph Generation and Anticipation
Nov 27, 2024Multimodal LLMs have advanced vision-language tasks but still struggle with understanding video scenes. To bridge this gap, Video Scene Graph Generation (VidSGG) has emerged to capture multi-object relationships across video frames. However, prior methods rely on pairwise connections, limiting their ability to handle complex multi-object interactions and reasoning. To this end, we propose Multimodal LLMs on a Scene HyperGraph (HyperGLM), promoting reasoning about multi-way interactions and higher-order relationships. Our approach uniquely integrates entity scene graphs, which capture spatial relationships between objects, with a procedural graph that models their causal transitions, forming a unified HyperGraph. Significantly, HyperGLM enables reasoning by injecting this unified HyperGraph into LLMs. Additionally, we introduce a new Video Scene Graph Reasoning (VSGR) dataset featuring 1.9M frames from third-person, egocentric, and drone views and supports five tasks: Scene Graph Generation, Scene Graph Anticipation, Video Question Answering, Video Captioning, and Relation Reasoning. Empirically, HyperGLM consistently outperforms state-of-the-art methods across five tasks, effectively modeling and reasoning complex relationships in diverse video scenes.
CYCLO: Cyclic Graph Transformer Approach to Multi-Object Relationship Modeling in Aerial Videos
Jun 03, 2024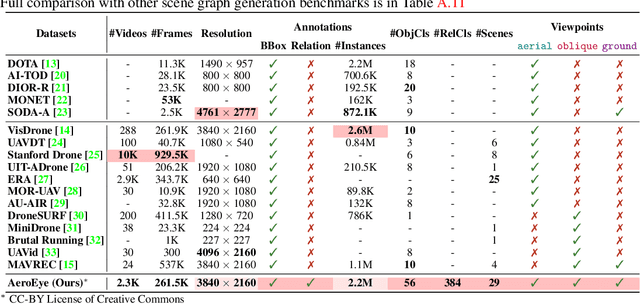
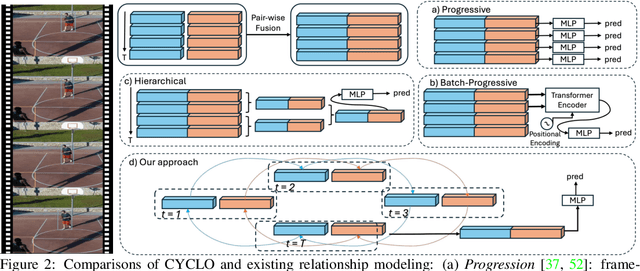
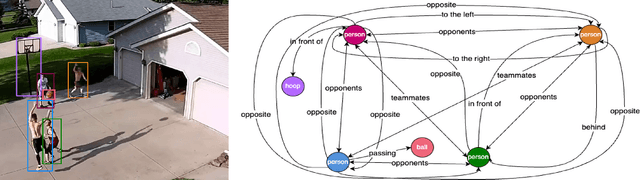

Video scene graph generation (VidSGG) has emerged as a transformative approach to capturing and interpreting the intricate relationships among objects and their temporal dynamics in video sequences. In this paper, we introduce the new AeroEye dataset that focuses on multi-object relationship modeling in aerial videos. Our AeroEye dataset features various drone scenes and includes a visually comprehensive and precise collection of predicates that capture the intricate relationships and spatial arrangements among objects. To this end, we propose the novel Cyclic Graph Transformer (CYCLO) approach that allows the model to capture both direct and long-range temporal dependencies by continuously updating the history of interactions in a circular manner. The proposed approach also allows one to handle sequences with inherent cyclical patterns and process object relationships in the correct sequential order. Therefore, it can effectively capture periodic and overlapping relationships while minimizing information loss. The extensive experiments on the AeroEye dataset demonstrate the effectiveness of the proposed CYCLO model, demonstrating its potential to perform scene understanding on drone videos. Finally, the CYCLO method consistently achieves State-of-the-Art (SOTA) results on two in-the-wild scene graph generation benchmarks, i.e., PVSG and ASPIRe.
HIG: Hierarchical Interlacement Graph Approach to Scene Graph Generation in Video Understanding
Dec 05, 2023Visual interactivity understanding within visual scenes presents a significant challenge in computer vision. Existing methods focus on complex interactivities while leveraging a simple relationship model. These methods, however, struggle with a diversity of appearance, situation, position, interaction, and relation in videos. This limitation hinders the ability to fully comprehend the interplay within the complex visual dynamics of subjects. In this paper, we delve into interactivities understanding within visual content by deriving scene graph representations from dense interactivities among humans and objects. To achieve this goal, we first present a new dataset containing Appearance-Situation-Position-Interaction-Relation predicates, named ASPIRe, offering an extensive collection of videos marked by a wide range of interactivities. Then, we propose a new approach named Hierarchical Interlacement Graph (HIG), which leverages a unified layer and graph within a hierarchical structure to provide deep insights into scene changes across five distinct tasks. Our approach demonstrates superior performance to other methods through extensive experiments conducted in various scenarios.
TextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
SketchANIMAR: Sketch-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching, and creating more diverse datasets to evaluate retrieval performance.