 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISCES: Annotation-free Text-to-Video Post-Training via Optimal Transport-Aligned Rewards
Feb 02, 2026Text-to-video (T2V) generation aims to synthesize videos with high visual quality and temporal consistency that are semantically aligned with input text. Reward-based post-training has emerged as a promising direction to improve the quality and semantic alignment of generated videos. However, recent methods either rely on large-scale human preference annotations or operate on misaligned embeddings from pre-trained vision-language models, leading to limited scalability or suboptimal supervision. We present $\texttt{PISCES}$, an annotation-free post-training algorithm that addresses these limitations via a novel Dual Optimal Transport (OT)-aligned Rewards module. To align reward signals with human judgment, $\texttt{PISCES}$ uses OT to bridge text and video embeddings at both distributional and discrete token levels, enabling reward supervision to fulfill two objectives: (i) a Distributional OT-aligned Quality Reward that captures overall visual quality and temporal coherence; and (ii) a Discrete Token-level OT-aligned Semantic Reward that enforces semantic, spatio-temporal correspondence between text and video tokens. To our knowledge, $\texttt{PISCES}$ is the first to improve annotation-free reward supervision in generative post-training through the lens of OT. Experiments on both short- and long-video generation show that $\texttt{PISCES}$ outperforms both annotation-based and annotation-free methods on VBench across Quality and Semantic scores, with human preference studies further validating its effectiveness. We show that the Dual OT-aligned Rewards module is compatible with multiple optimization paradigms, including direct backpropagation and reinforcement learning fine-tuning.
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Feb 07, 2025



While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird's potential as a robust multimodal context-aligned image generator in complex visual tasks.
$\infty$-Brush: Controllable Large Image Synthesis with Diffusion Models in Infinite Dimensions
Jul 20, 2024



Synthesizing high-resolution images from intricate, domain-specific information remains a significant challenge in generative modeling, particularly for applications in large-image domains such as digital histopathology and remote sensing. Existing methods face critical limitations: conditional diffusion models in pixel or latent space cannot exceed the resolution on which they were trained without losing fidelity, and computational demands increase significantly for larger image sizes. Patch-based methods offer computational efficiency but fail to capture long-range spatial relationships due to their overreliance on local information. In this paper, we introduce a novel conditional diffusion model in infinite dimensions, $\infty$-Brush for controllable large image synthesis. We propose a cross-attention neural operator to enable conditioning in function space. Our model overcomes the constraints of traditional finite-dimensional diffusion models and patch-based methods, offering scalability and superior capability in preserving global image structures while maintaining fine details. To our best knowledge, $\infty$-Brush is the first conditional diffusion model in function space, that can controllably synthesize images at arbitrary resolutions of up to $4096\times4096$ pixels. The code is available at https://github.com/cvlab-stonybrook/infinity-brush.
Learned representation-guided diffusion models for large-image generation
Dec 12, 2023
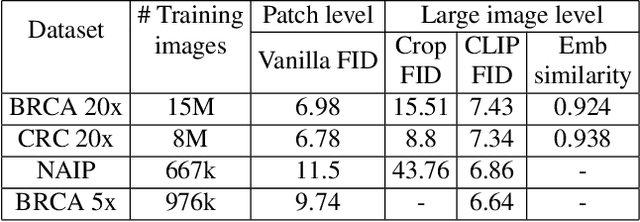


To synthesize high-fidelity samples, diffusion models typically require auxiliary data to guide the generation process. However, it is impractical to procure the painstaking patch-level annotation effort required in specialized domains like histopathology and satellite imagery; it is often performed by domain experts and involves hundreds of millions of patches. Modern-day self-supervised learning (SSL) representations encode rich semantic and visual information. In this paper, we posit that such representations are expressive enough to act as proxies to fine-grained human labels. We introduce a novel approach that trains diffusion models conditioned on embeddings from SSL. Our diffusion models successfully project these features back to high-quality histopathology and remote sensing images. In addition, we construct larger images by assembling spatially consistent patches inferred from SSL embeddings, preserving long-range dependencies. Augmenting real data by generating variations of real images improves downstream classifier accuracy for patch-level and larger, image-scale classification tasks. Our models are effective even on datasets not encountered during training, demonstrating their robustness and generalizability. Generating images from learned embeddings is agnostic to the source of the embeddings. The SSL embeddings used to generate a large image can either be extracted from a reference image, or sampled from an auxiliary model conditioned on any related modality (e.g. class labels, text, genomic data). As proof of concept, we introduce the text-to-large image synthesis paradigm where we successfully synthesize large pathology and satellite images out of text descriptions.
Unveiling Camouflage: A Learnable Fourier-based Augmentation for Camouflaged Object Detection and Instance Segmentation
Aug 29, 2023



Camouflaged object detection (COD) and camouflaged instance segmentation (CIS) aim to recognize and segment objects that are blended into their surroundings, respectively. While several deep neural network models have been proposed to tackle those tasks, augmentation methods for COD and CIS have not been thoroughly explored. Augmentation strategies can help improve the performance of models by increasing the size and diversity of the training data and exposing the model to a wider range of variations in the data. Besides, we aim to automatically learn transformations that help to reveal the underlying structure of camouflaged objects and allow the model to learn to better identify and segment camouflaged objects. To achieve this, we propose a learnable augmentation method in the frequency domain for COD and CIS via Fourier transform approach, dubbed CamoFourier. Our method leverages a conditional generative adversarial network and cross-attention mechanism to generate a reference image and an adaptive hybrid swapping with parameters to mix the low-frequency component of the reference image and the high-frequency component of the input image. This approach aims to make camouflaged objects more visible for detection and segmentation models. Without bells and whistles, our proposed augmentation method boosts the performance of camouflaged object detectors and camouflaged instance segmenters by large margins.
SketchANIMAR: Sketch-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching, and creating more diverse datasets to evaluate retrieval performance.
TextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
MaskDiff: Modeling Mask Distribution with Diffusion Probabilistic Model for Few-Shot Instance Segmentation
Mar 09, 2023
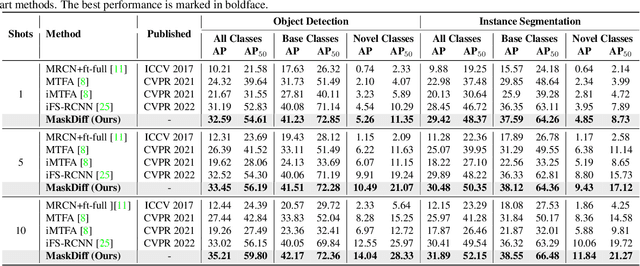

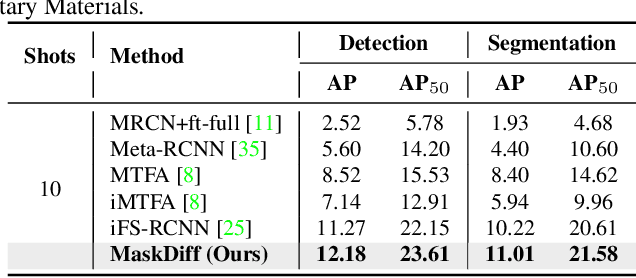
Few-shot instance segmentation extends the few-shot learning paradigm to the instance segmentation task, which tries to segment instance objects from a query image with a few annotated examples of novel categories. Conventional approaches have attempted to address the task via prototype learning, known as point estimation. However, this mechanism is susceptible to noise and suffers from bias due to a significant scarcity of data. To overcome the disadvantages of the point estimation mechanism, we propose a novel approach, dubbed MaskDiff, which models the underlying conditional distribution of a binary mask, which is conditioned on an object region and $K$-shot information. Inspired by augmentation approaches that perturb data with Gaussian noise for populating low data density regions, we model the mask distribution with a diffusion probabilistic model. In addition, we propose to utilize classifier-free guided mask sampling to integrate category information into the binary mask generation process. Without bells and whistles, our proposed method consistently outperforms state-of-the-art methods on both base and novel classes of the COCO dataset while simultaneously being more stable than existing methods.
SHREC 2022 Track on Online Detection of Heterogeneous Gestures
Jul 22, 2022

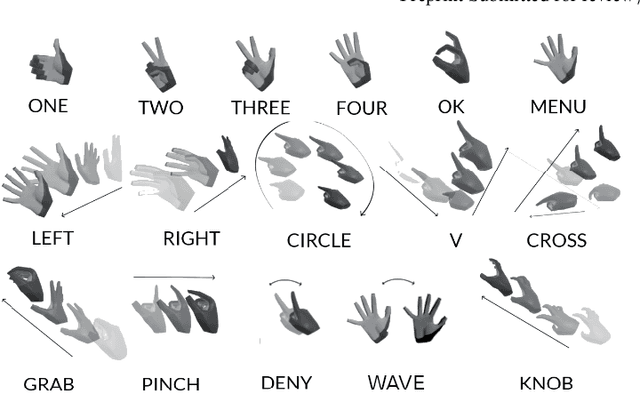
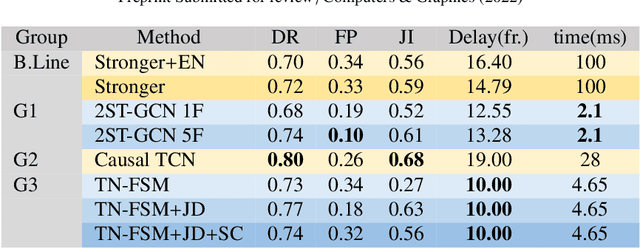
This paper presents the outcomes of a contest organized to evaluate methods for the online recognition of heterogeneous gestures from sequences of 3D hand poses. The task is the detection of gestures belonging to a dictionary of 16 classes characterized by different pose and motion features. The dataset features continuous sequences of hand tracking data where the gestures are interleaved with non-significant motions. The data have been captured using the Hololens 2 finger tracking system in a realistic use-case of mixed reality interaction. The evaluation is based not only on the detection performances but also on the latency and the false positives, making it possible to understand the feasibility of practical interaction tools based on the algorithms proposed. The outcomes of the contest's evaluation demonstrate the necessity of further research to reduce recognition errors, while the computational cost of the algorithms proposed is sufficiently low.
Multimodal-based Scene-Aware Framework for Aquatic Animal Segmentation
Dec 12, 2021
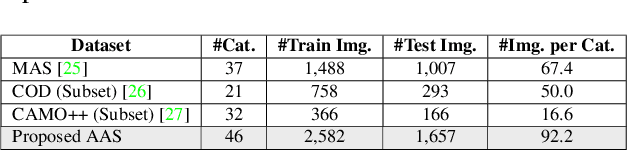
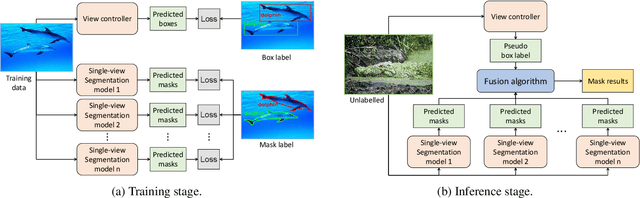
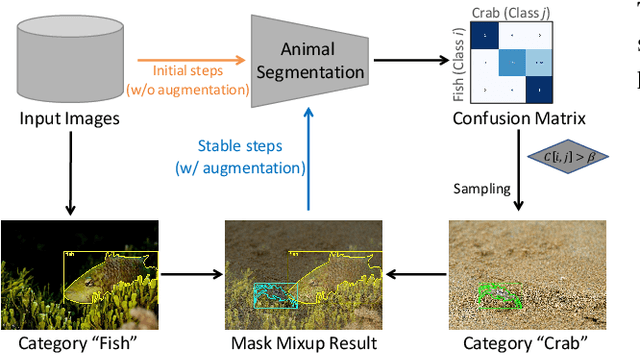
Recent years have witnessed great advances in object segmentation research. In addition to generic objects, aquatic animals have attracted research attention. Deep learning-based methods are widely used for aquatic animal segmentation and have achieved promising performance. However, there is a lack of challenging datasets for benchmarking. Therefore, we have created a new dataset dubbed "Aquatic Animal Species." Furthermore, we devised a novel multimodal-based scene-aware segmentation framework that leverages the advantages of multiple view segmentation models to segment images of aquatic animals effectively. To improve training performance, we developed a guided mixup augmentation method. Extensive experiments comparing the performance of the proposed framework with state-of-the-art instance segmentation methods demonstrated that our method is effective and that it significantly outperforms existing methods.