 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRAJ: Diverse and Efficient Red-Teaming for LLM Agents via Distilled Structured Reasoning
Oct 30, 2025The ability of LLM agents to plan and invoke tools exposes them to new safety risks, making a comprehensive red-teaming system crucial for discovering vulnerabilities and ensuring their safe deployment. We present SIRAJ: a generic red-teaming framework for arbitrary black-box LLM agents. We employ a dynamic two-step process that starts with an agent definition and generates diverse seed test cases that cover various risk outcomes, tool-use trajectories, and risk sources. Then, it iteratively constructs and refines model-based adversarial attacks based on the execution trajectories of former attempts. To optimize the red-teaming cost, we present a model distillation approach that leverages structured forms of a teacher model's reasoning to train smaller models that are equally effective. Across diverse evaluation agent settings, our seed test case generation approach yields 2 -- 2.5x boost to the coverage of risk outcomes and tool-calling trajectories. Our distilled 8B red-teamer model improves attack success rate by 100%, surpassing the 671B Deepseek-R1 model. Our ablations and analyses validate the effectiveness of the iterative framework, structured reasoning, and the generalization of our red-teamer models.
Jailbreak Distillation: Renewable Safety Benchmarking
May 28, 2025Large language models (LLMs) are rapidly deployed in critical applications, raising urgent needs for robust safety benchmarking. We propose Jailbreak Distillation (JBDistill), a novel benchmark construction framework that "distills" jailbreak attacks into high-quality and easily-updatable safety benchmarks. JBDistill utilizes a small set of development models and existing jailbreak attack algorithms to create a candidate prompt pool, then employs prompt selection algorithms to identify an effective subset of prompts as safety benchmarks. JBDistill addresses challenges in existing safety evaluation: the use of consistent evaluation prompts across models ensures fair comparisons and reproducibility. It requires minimal human effort to rerun the JBDistill pipeline and produce updated benchmarks, alleviating concerns on saturation and contamination. Extensive experiments demonstrate our benchmarks generalize robustly to 13 diverse evaluation models held out from benchmark construction, including proprietary, specialized, and newer-generation LLMs, significantly outperforming existing safety benchmarks in effectiveness while maintaining high separability and diversity. Our framework thus provides an effective, sustainable, and adaptable solution for streamlining safety evaluation.
DeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
May 22, 2025Long Video Temporal Grounding (LVTG) aims at identifying specific moments within lengthy videos based on user-provided text queries for effective content retrieval. The approach taken by existing methods of dividing video into clips and processing each clip via a full-scale expert encoder is challenging to scale due to prohibitive computational costs of processing a large number of clips in long videos. To address this issue, we introduce DeCafNet, an approach employing ``delegate-and-conquer'' strategy to achieve computation efficiency without sacrificing grounding performance. DeCafNet introduces a sidekick encoder that performs dense feature extraction over all video clips in a resource-efficient manner, while generating a saliency map to identify the most relevant clips for full processing by the expert encoder. To effectively leverage features from sidekick and expert encoders that exist at different temporal resolutions, we introduce DeCaf-Grounder, which unifies and refines them via query-aware temporal aggregation and multi-scale temporal refinement for accurate grounding. Experiments on two LTVG benchmark datasets demonstrate that DeCafNet reduces computation by up to 47\% while still outperforming existing methods, establishing a new state-of-the-art for LTVG in terms of both efficiency and performance. Our code is available at https://github.com/ZijiaLewisLu/CVPR2025-DeCafNet.
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Feb 07, 2025



While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird's potential as a robust multimodal context-aligned image generator in complex visual tasks.
DDS: Decoupled Dynamic Scene-Graph Generation Network
Jan 18, 2023Scene-graph generation involves creating a structural representation of the relationships between objects in a scene by predicting subject-object-relation triplets from input data. However, existing methods show poor performance in detecting triplets outside of a predefined set, primarily due to their reliance on dependent feature learning. To address this issue we propose DDS -- a decoupled dynamic scene-graph generation network -- that consists of two independent branches that can disentangle extracted features. The key innovation of the current paper is the decoupling of the features representing the relationships from those of the objects, which enables the detection of novel object-relationship combinations. The DDS model is evaluated on three datasets and outperforms previous methods by a significant margin, especially in detecting previously unseen triplets.
Context-Driven Detection of Invertebrate Species in Deep-Sea Video
Jun 01, 2022

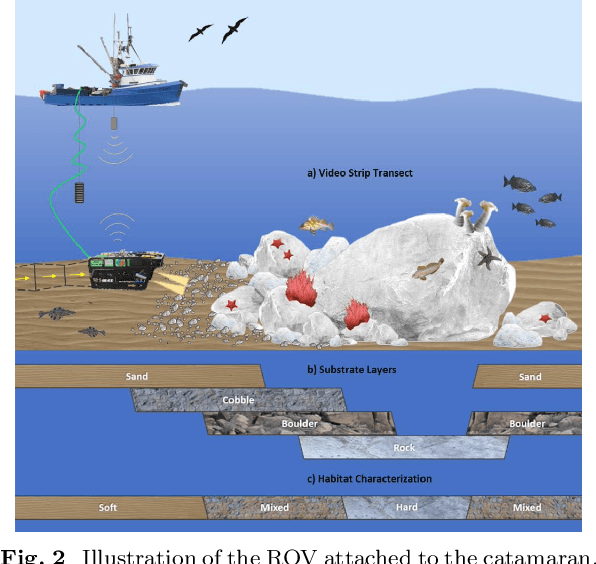
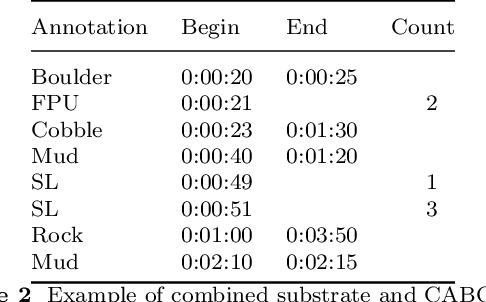
Each year, underwater remotely operated vehicles (ROVs) collect thousands of hours of video of unexplored ocean habitats revealing a plethora of information regarding biodiversity on Earth. However, fully utilizing this information remains a challenge as proper annotations and analysis require trained scientists time, which is both limited and costly. To this end, we present a Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), a benchmark suite and growing large-scale dataset to train, validate, and test methods for temporally localizing four underwater substrates as well as temporally and spatially localizing 59 underwater invertebrate species. DUSIA currently includes over ten hours of footage across 25 videos captured in 1080p at 30 fps by an ROV following pre planned transects across the ocean floor near the Channel Islands of California. Each video includes annotations indicating the start and end times of substrates across the video in addition to counts of species of interest. Some frames are annotated with precise bounding box locations for invertebrate species of interest, as seen in Figure 1. To our knowledge, DUSIA is the first dataset of its kind for deep sea exploration, with video from a moving camera, that includes substrate annotations and invertebrate species that are present at significant depths where sunlight does not penetrate. Additionally, we present the novel context-driven object detector (CDD) where we use explicit substrate classification to influence an object detection network to simultaneously predict a substrate and species class influenced by that substrate. We also present a method for improving training on partially annotated bounding box frames. Finally, we offer a baseline method for automating the counting of invertebrate species of interest.
What to look at and where: Semantic and Spatial Refined Transformer for detecting human-object interactions
Apr 02, 2022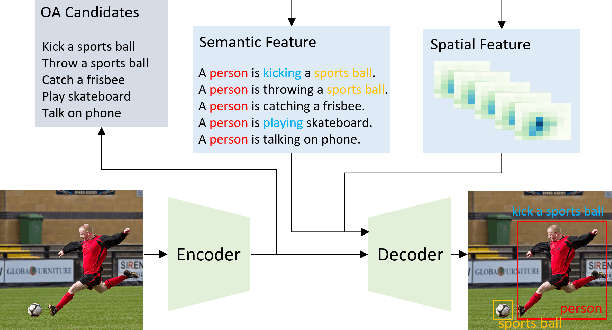
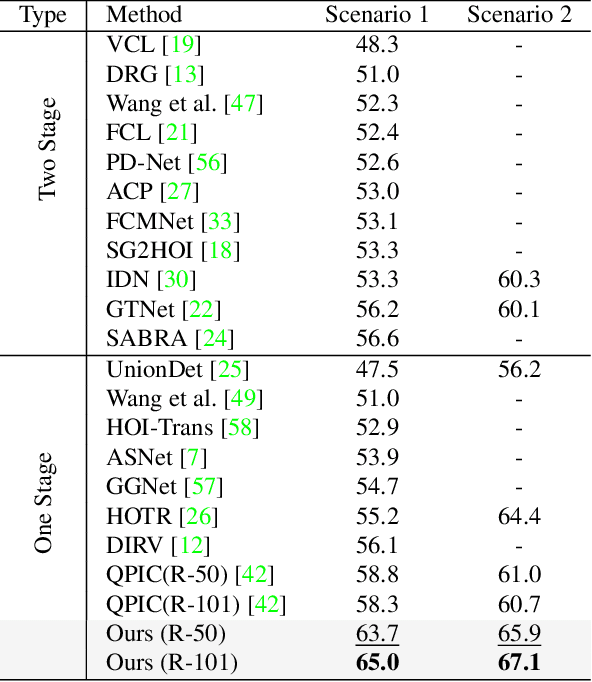
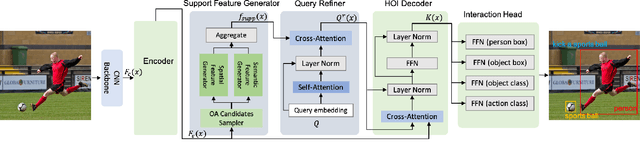
We propose a novel one-stage Transformer-based semantic and spatial refined transformer (SSRT) to solve the Human-Object Interaction detection task, which requires to localize humans and objects, and predicts their interactions. Differently from previous Transformer-based HOI approaches, which mostly focus at improving the design of the decoder outputs for the final detection, SSRT introduces two new modules to help select the most relevant object-action pairs within an image and refine the queries' representation using rich semantic and spatial features. These enhancements lead to state-of-the-art results on the two most popular HOI benchmarks: V-COCO and HICO-DET.
GTNet:Guided Transformer Network for Detecting Human-Object Interactions
Aug 03, 2021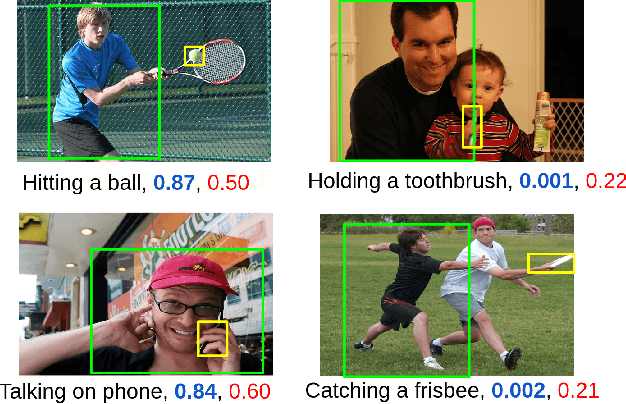
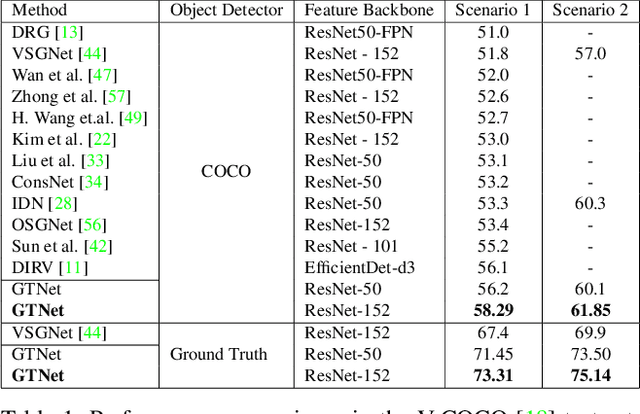
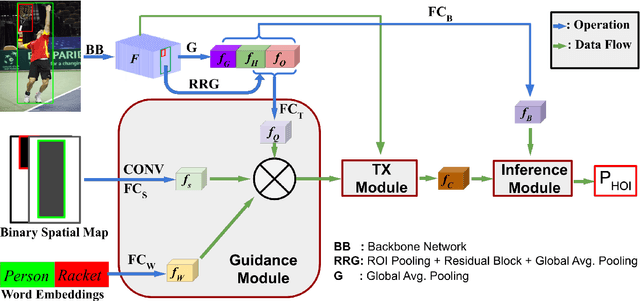
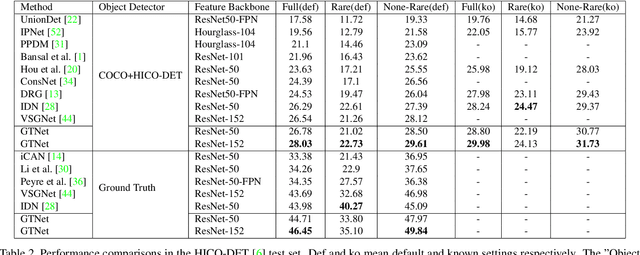
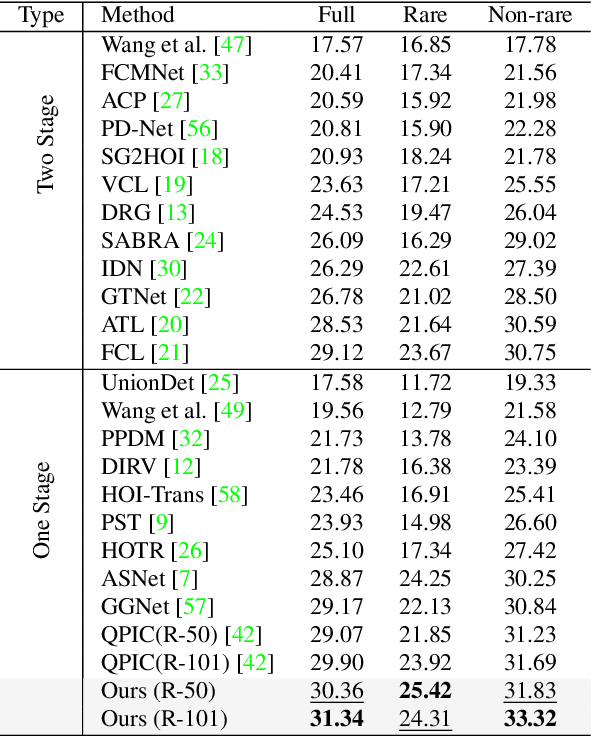
The human-object interaction (HOI) detection task refers to localizing humans, localizing objects, and predicting the interactions between each human-object pair. HOI is considered one of the fundamental steps in truly understanding complex visual scenes. For detecting HOI, it is important to utilize relative spatial configurations and object semantics to find salient spatial regions of images that highlight the interactions between human object pairs. This issue is addressed by the proposed self-attention based guided transformer network, GTNet. GTNet encodes this spatial contextual information in human and object visual features via self-attention while achieving a 4%-6% improvement over previous state of the art results on both the V-COCO and HICO-DET datasets. Code will be made available online.
StressNet: Detecting Stress in Thermal Videos
Nov 23, 2020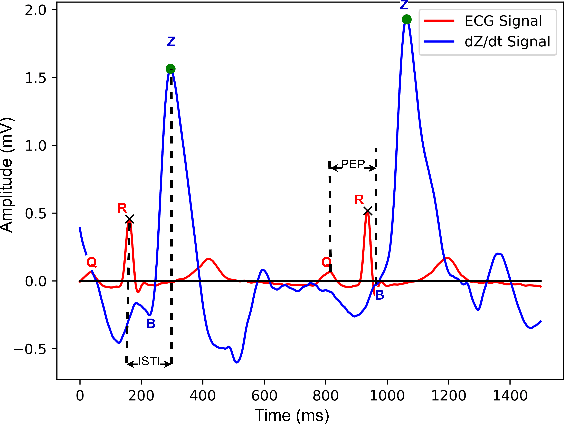
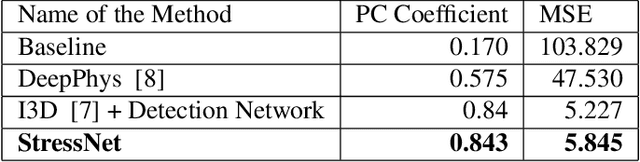
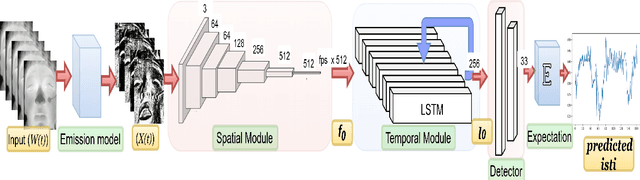
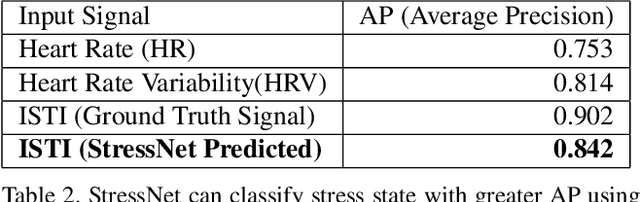
Precise measurement of physiological signals is critical for the effective monitoring of human vital signs. Recent developments in computer vision have demonstrated that signals such as pulse rate and respiration rate can be extracted from digital video of humans, increasing the possibility of contact-less monitoring. This paper presents a novel approach to obtaining physiological signals and classifying stress states from thermal video. The proposed network--"StressNet"--features a hybrid emission representation model that models the direct emission and absorption of heat by the skin and underlying blood vessels. This results in an information-rich feature representation of the face, which is used by spatio-temporal network for reconstructing the ISTI ( Initial Systolic Time Interval: a measure of change in cardiac sympathetic activity that is considered to be a quantitative index of stress in humans ). The reconstructed ISTI signal is fed into a stress-detection model to detect and classify the individual's stress state ( i.e. stress or no stress ). A detailed evaluation demonstrates that StressNet achieves estimated the ISTI signal with 95% accuracy and detect stress with average precision of 0.842. The source code is available on Github.
VSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
Mar 11, 2020

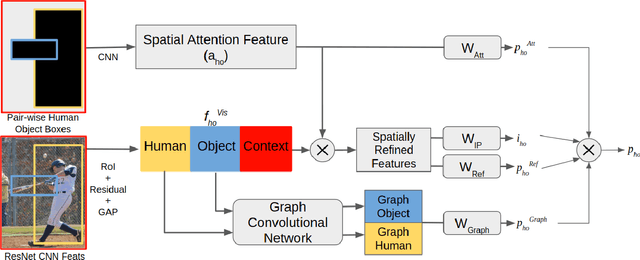

Comprehensive visual understanding requires detection frameworks that can effectively learn and utilize object interactions while analyzing objects individually. This is the main objective in Human-Object Interaction (HOI) detection task. In particular, relative spatial reasoning and structural connections between objects are essential cues for analyzing interactions, which is addressed by the proposed Visual-Spatial-Graph Network (VSGNet) architecture. VSGNet extracts visual features from the human-object pairs, refines the features with spatial configurations of the pair, and utilizes the structural connections between the pair via graph convolutions. The performance of VSGNet is thoroughly evaluated using the Verbs in COCO (V-COCO) and HICO-DET datasets. Experimental results indicate that VSGNet outperforms state-of-the-art solutions by 8% or 4 mAP in V-COCO and 16% or 3 mAP in HICO-DET.