 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Embodied Perception in Dynamic Environments via Disentangled Weight Fusion
Apr 02, 2026Embodied perception systems face severe challenges of dynamic environment distribution drift when they continuously interact in open physical spaces. However, the existing domain incremental awareness methods often rely on the domain id obtained in advance during the testing phase, which limits their practicability in unknown interaction scenarios. At the same time, the model often overfits to the context-specific perceptual noise, which leads to insufficient generalization ability and catastrophic forgetting. To address these limitations, we propose a domain-id and exemplar-free incremental learning framework for embodied multimedia systems, which aims to achieve robust continuous environment adaptation. This method designs a disentangled representation mechanism to remove non-essential environmental style interference, and guide the model to focus on extracting semantic intrinsic features shared across scenes, thereby eliminating perceptual uncertainty and improving generalization. We further use the weight fusion strategy to dynamically integrate the old and new environment knowledge in the parameter space, so as to ensure that the model adapts to the new distribution without storing historical data and maximally retains the discrimination ability of the old environment. Extensive experiments on multiple standard benchmark datasets show that the proposed method significantly reduces catastrophic forgetting in a completely exemplar-free and domain-id free setting, and its accuracy is better than the existing state-of-the-art methods.
Are Finer Citations Always Better? Rethinking Granularity for Attributed Generation
Apr 01, 2026Citation granularity - whether to cite individual sentences, paragraphs, or documents - is a critical design choice in attributed generation. While fine-grained citations are often preferred for precise human verification, their impact on model performance remains under-explored. We analyze four model scales (8B-120B) and demonstrate that enforcing fine-grained citations degrades attribution quality by 16-276% compared to the best-performing granularity. We observe a consistent performance pattern where attribution quality peaks at intermediate granularities (paragraph-level). Our analysis suggests that fine-grained (sentence-level) citations disrupt necessary semantic dependencies for attributing evidence to answer claims, while excessively coarse citations (multi-paragraph) introduce distracting noise. Importantly, the magnitude of this performance gap varies non-monotonically with model scale: fine-grained constraints disproportionately penalize larger models, suggesting that atomic citation units disrupt the multi-sentence information synthesis at which these models excel. Strikingly, citation-optimal granularity leads to substantial gains in attribution quality while preserving or even improving answer correctness. Overall, our findings demonstrate that optimizing solely for human verification via fine-grained citation disregards model constraints, compromising both attribution faithfulness and generation reliability. Instead, effective attribution requires aligning citation granularity with the model's natural semantic scope.
Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
OOD-MMSafe: Advancing MLLM Safety from Harmful Intent to Hidden Consequences
Mar 10, 2026While safety alignment for Multimodal Large Language Models (MLLMs) has gained significant attention, current paradigms primarily target malicious intent or situational violations. We propose shifting the safety frontier toward consequence-driven safety, a paradigm essential for the robust deployment of autonomous and embodied agents. To formalize this shift, we introduce OOD-MMSafe, a benchmark comprising 455 curated query-image pairs designed to evaluate a model's ability to identify latent hazards within context-dependent causal chains. Our analysis reveals a pervasive causal blindness among frontier models, with the highest 67.5% failure rate in high-capacity closed-source models, and identifies a preference ceiling where static alignment yields format-centric failures rather than improved safety reasoning as model capacity grows. To address these bottlenecks, we develop the Consequence-Aware Safety Policy Optimization (CASPO) framework, which integrates the model's intrinsic reasoning as a dynamic reference for token-level self-distillation rewards. Experimental results demonstrate that CASPO significantly enhances consequence projection, reducing the failure ratio of risk identification to 7.3% for Qwen2.5-VL-7B and 5.7% for Qwen3-VL-4B while maintaining overall effectiveness.
Advancing Autonomous Driving System Testing: Demands, Challenges, and Future Directions
Dec 09, 2025Autonomous driving systems (ADSs) promise improved transportation efficiency and safety, yet ensuring their reliability in complex real-world environments remains a critical challenge. Effective testing is essential to validate ADS performance and reduce deployment risks. This study investigates current ADS testing practices for both modular and end-to-end systems, identifies key demands from industry practitioners and academic researchers, and analyzes the gaps between existing research and real-world requirements. We review major testing techniques and further consider emerging factors such as Vehicle-to-Everything (V2X) communication and foundation models, including large language models and vision foundation models, to understand their roles in enhancing ADS testing. We conducted a large-scale survey with 100 participants from both industry and academia. Survey questions were refined through expert discussions, followed by quantitative and qualitative analyses to reveal key trends, challenges, and unmet needs. Our results show that existing ADS testing techniques struggle to comprehensively evaluate real-world performance, particularly regarding corner case diversity, the simulation to reality gap, the lack of systematic testing criteria, exposure to potential attacks, practical challenges in V2X deployment, and the high computational cost of foundation model-based testing. By further analyzing participant responses together with 105 representative studies, we summarize the current research landscape and highlight major limitations. This study consolidates critical research gaps in ADS testing and outlines key future research directions, including comprehensive testing criteria, cross-model collaboration in V2X systems, cross-modality adaptation for foundation model-based testing, and scalable validation frameworks for large-scale ADS evaluation.
FedLAD: A Modular and Adaptive Testbed for Federated Log Anomaly Detection
Dec 09, 2025Log-based anomaly detection (LAD) is critical for ensuring the reliability of large-scale distributed systems. However, most existing LAD approaches assume centralized training, which is often impractical due to privacy constraints and the decentralized nature of system logs. While federated learning (FL) offers a promising alternative, there is a lack of dedicated testbeds tailored to the needs of LAD in federated settings. To address this, we present FedLAD, a unified platform for training and evaluating LAD models under FL constraints. FedLAD supports plug-and-play integration of diverse LAD models, benchmark datasets, and aggregation strategies, while offering runtime support for validation logging (self-monitoring), parameter tuning (self-configuration), and adaptive strategy control (self-adaptation). By enabling reproducible and scalable experimentation, FedLAD bridges the gap between FL frameworks and LAD requirements, providing a solid foundation for future research. Project code is publicly available at: https://github.com/AA-cityu/FedLAD.
Jailbreak Distillation: Renewable Safety Benchmarking
May 28, 2025Large language models (LLMs) are rapidly deployed in critical applications, raising urgent needs for robust safety benchmarking. We propose Jailbreak Distillation (JBDistill), a novel benchmark construction framework that "distills" jailbreak attacks into high-quality and easily-updatable safety benchmarks. JBDistill utilizes a small set of development models and existing jailbreak attack algorithms to create a candidate prompt pool, then employs prompt selection algorithms to identify an effective subset of prompts as safety benchmarks. JBDistill addresses challenges in existing safety evaluation: the use of consistent evaluation prompts across models ensures fair comparisons and reproducibility. It requires minimal human effort to rerun the JBDistill pipeline and produce updated benchmarks, alleviating concerns on saturation and contamination. Extensive experiments demonstrate our benchmarks generalize robustly to 13 diverse evaluation models held out from benchmark construction, including proprietary, specialized, and newer-generation LLMs, significantly outperforming existing safety benchmarks in effectiveness while maintaining high separability and diversity. Our framework thus provides an effective, sustainable, and adaptable solution for streamlining safety evaluation.
Certified Mitigation of Worst-Case LLM Copyright Infringement
Apr 22, 2025

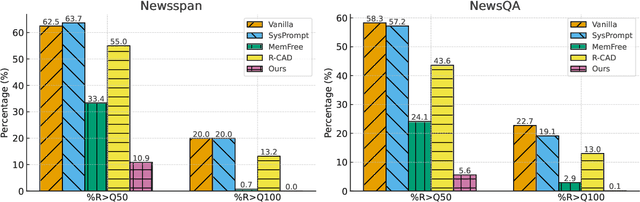
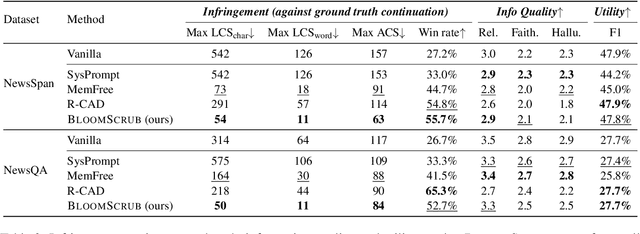
The exposure of large language models (LLMs) to copyrighted material during pre-training raises concerns about unintentional copyright infringement post deployment. This has driven the development of "copyright takedown" methods, post-training approaches aimed at preventing models from generating content substantially similar to copyrighted ones. While current mitigation approaches are somewhat effective for average-case risks, we demonstrate that they overlook worst-case copyright risks exhibits by the existence of long, verbatim quotes from copyrighted sources. We propose BloomScrub, a remarkably simple yet highly effective inference-time approach that provides certified copyright takedown. Our method repeatedly interleaves quote detection with rewriting techniques to transform potentially infringing segments. By leveraging efficient data sketches (Bloom filters), our approach enables scalable copyright screening even for large-scale real-world corpora. When quotes beyond a length threshold cannot be removed, the system can abstain from responding, offering certified risk reduction. Experimental results show that BloomScrub reduces infringement risk, preserves utility, and accommodates different levels of enforcement stringency with adaptive abstention. Our results suggest that lightweight, inference-time methods can be surprisingly effective for copyright prevention.
Can A Society of Generative Agents Simulate Human Behavior and Inform Public Health Policy? A Case Study on Vaccine Hesitancy
Mar 12, 2025Can we simulate a sandbox society with generative agents to model human behavior, thereby reducing the over-reliance on real human trials for assessing public policies? In this work, we investigate the feasibility of simulating health-related decision-making, using vaccine hesitancy, defined as the delay in acceptance or refusal of vaccines despite the availability of vaccination services (MacDonald, 2015), as a case study. To this end, we introduce the VacSim framework with 100 generative agents powered by Large Language Models (LLMs). VacSim simulates vaccine policy outcomes with the following steps: 1) instantiate a population of agents with demographics based on census data; 2) connect the agents via a social network and model vaccine attitudes as a function of social dynamics and disease-related information; 3) design and evaluate various public health interventions aimed at mitigating vaccine hesitancy. To align with real-world results, we also introduce simulation warmup and attitude modulation to adjust agents' attitudes. We propose a series of evaluations to assess the reliability of various LLM simulations. Experiments indicate that models like Llama and Qwen can simulate aspects of human behavior but also highlight real-world alignment challenges, such as inconsistent responses with demographic profiles. This early exploration of LLM-driven simulations is not meant to serve as definitive policy guidance; instead, it serves as a call for action to examine social simulation for policy development.
DSRC: Learning Density-insensitive and Semantic-aware Collaborative Representation against Corruptions
Dec 14, 2024



As a potential application of Vehicle-to-Everything (V2X) communication, multi-agent collaborative perception has achieved significant success in 3D object detection. While these methods have demonstrated impressive results on standard benchmarks, the robustness of such approaches in the face of complex real-world environments requires additional verification. To bridge this gap, we introduce the first comprehensive benchmark designed to evaluate the robustness of collaborative perception methods in the presence of natural corruptions typical of real-world environments. Furthermore, we propose DSRC, a robustness-enhanced collaborative perception method aiming to learn Density-insensitive and Semantic-aware collaborative Representation against Corruptions. DSRC consists of two key designs: i) a semantic-guided sparse-to-dense distillation framework, which constructs multi-view dense objects painted by ground truth bounding boxes to effectively learn density-insensitive and semantic-aware collaborative representation; ii) a feature-to-point cloud reconstruction approach to better fuse critical collaborative representation across agents. To thoroughly evaluate DSRC, we conduct extensive experiments on real-world and simulated datasets. The results demonstrate that our method outperforms SOTA collaborative perception methods in both clean and corrupted conditions. Code is available at https://github.com/Terry9a/DSRC.