 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Mitigation of Worst-Case LLM Copyright Infringement
Apr 22, 2025

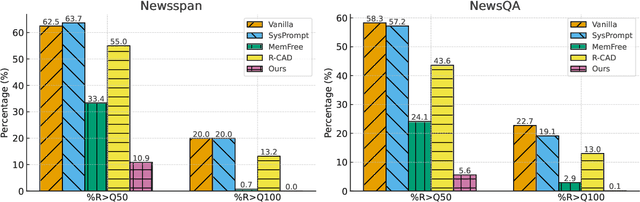
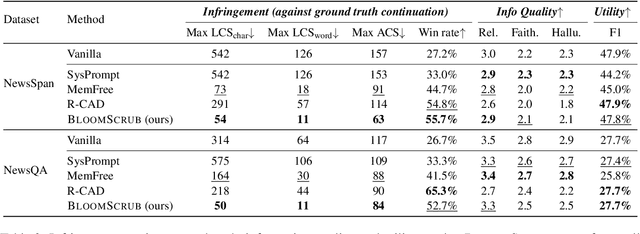
The exposure of large language models (LLMs) to copyrighted material during pre-training raises concerns about unintentional copyright infringement post deployment. This has driven the development of "copyright takedown" methods, post-training approaches aimed at preventing models from generating content substantially similar to copyrighted ones. While current mitigation approaches are somewhat effective for average-case risks, we demonstrate that they overlook worst-case copyright risks exhibits by the existence of long, verbatim quotes from copyrighted sources. We propose BloomScrub, a remarkably simple yet highly effective inference-time approach that provides certified copyright takedown. Our method repeatedly interleaves quote detection with rewriting techniques to transform potentially infringing segments. By leveraging efficient data sketches (Bloom filters), our approach enables scalable copyright screening even for large-scale real-world corpora. When quotes beyond a length threshold cannot be removed, the system can abstain from responding, offering certified risk reduction. Experimental results show that BloomScrub reduces infringement risk, preserves utility, and accommodates different levels of enforcement stringency with adaptive abstention. Our results suggest that lightweight, inference-time methods can be surprisingly effective for copyright prevention.
Language Models Benefit from Preparation with Elicited Knowledge
Sep 02, 2024The zero-shot chain of thought (CoT) approach is often used in question answering (QA) by language models (LMs) for tasks that require multiple reasoning steps, typically enhanced by the prompt "Let's think step by step." However, some QA tasks hinge more on accessing relevant knowledge than on chaining reasoning steps. We introduce a simple general prompting technique, called PREP, that involves using two instances of LMs: the first (LM1) generates relevant information, and the second (LM2) answers the question based on this information. PREP is designed to be general and independent of the user's domain knowledge, making it applicable across various QA tasks without the need for specialized prompt engineering. To evaluate the effectiveness of our prompting method, we create a dataset of 100 binary-choice questions, derived from an extensive schematic dataset on artifact parts and material composition. These questions ask which of two artifacts is less likely to share materials with another artifact. Such questions probe the LM's knowledge of shared materials in the part structure of different artifacts. We test our method on our dataset and three published commonsense reasoning datasets. The average accuracy of our method is consistently higher than that of all the other tested methods across all the tested datasets.