 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as a Tool for Mining Object Knowledge
Oct 16, 2024Commonsense knowledge is essential for machines to reason about the world. Large language models (LLMs) have demonstrated their ability to perform almost human-like text generation. Despite this success, they fall short as trustworthy intelligent systems, due to the opacity of the basis for their answers and a tendency to confabulate facts when questioned about obscure entities or technical domains. We hypothesize, however, that their general knowledge about objects in the everyday world is largely sound. Based on that hypothesis, this paper investigates LLMs' ability to formulate explicit knowledge about common physical artifacts, focusing on their parts and materials. Our work distinguishes between the substances that comprise an entire object and those that constitute its parts$\unicode{x2014}$a previously underexplored distinction in knowledge base construction. Using few-shot with five in-context examples and zero-shot multi-step prompting, we produce a repository of data on the parts and materials of about 2,300 objects and their subtypes. Our evaluation demonstrates LLMs' coverage and soundness in extracting knowledge. This contribution to knowledge mining should prove useful to AI research on reasoning about object structure and composition and serve as an explicit knowledge source (analogous to knowledge graphs) for LLMs performing multi-hop question answering.
Language Models Benefit from Preparation with Elicited Knowledge
Sep 02, 2024The zero-shot chain of thought (CoT) approach is often used in question answering (QA) by language models (LMs) for tasks that require multiple reasoning steps, typically enhanced by the prompt "Let's think step by step." However, some QA tasks hinge more on accessing relevant knowledge than on chaining reasoning steps. We introduce a simple general prompting technique, called PREP, that involves using two instances of LMs: the first (LM1) generates relevant information, and the second (LM2) answers the question based on this information. PREP is designed to be general and independent of the user's domain knowledge, making it applicable across various QA tasks without the need for specialized prompt engineering. To evaluate the effectiveness of our prompting method, we create a dataset of 100 binary-choice questions, derived from an extensive schematic dataset on artifact parts and material composition. These questions ask which of two artifacts is less likely to share materials with another artifact. Such questions probe the LM's knowledge of shared materials in the part structure of different artifacts. We test our method on our dataset and three published commonsense reasoning datasets. The average accuracy of our method is consistently higher than that of all the other tested methods across all the tested datasets.
History-Aware Question Answering in a Blocks World Dialogue System
May 26, 2020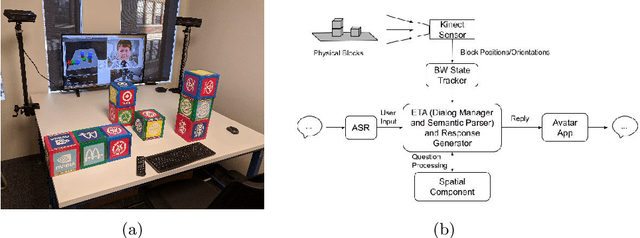
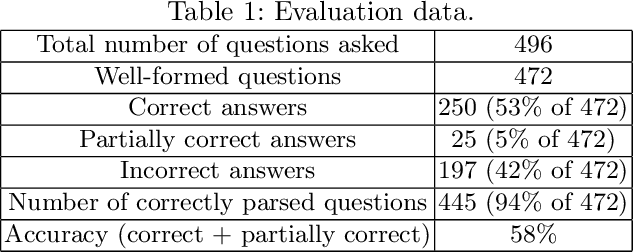
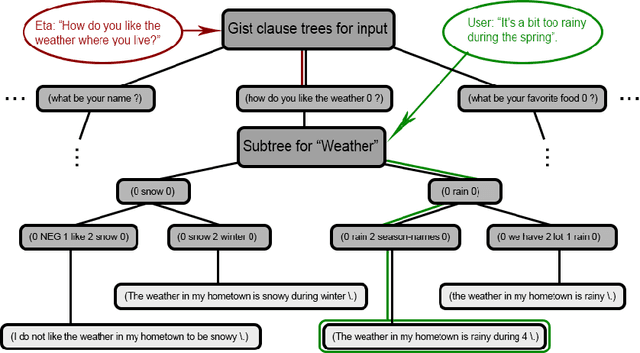
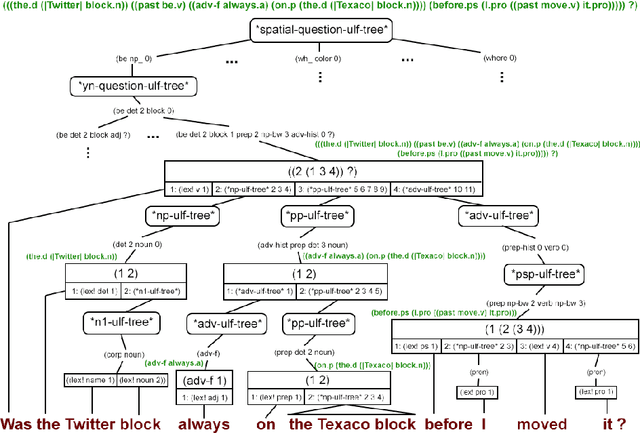
It is essential for dialogue-based spatial reasoning systems to maintain memory of historical states of the world. In addition to conveying that the dialogue agent is mentally present and engaged with the task, referring to historical states may be crucial for enabling collaborative planning (e.g., for planning to return to a previous state, or diagnosing a past misstep). In this paper, we approach the problem of spatial memory in a multi-modal spoken dialogue system capable of answering questions about interaction history in a physical blocks world setting. This work builds upon a full spatial question-answering pipeline consisting of a vision system, speech input and output mediated by an animated avatar, a dialogue system that robustly interprets spatial queries, and a constraint solver that derives answers based on 3-D spatial modelling. The contributions of this work include a symbolic dialogue context registering knowledge about discourse history and changes in the world, as well as a natural language understanding module capable of interpreting free-form historical questions and querying the dialogue context to form an answer.
A Spoken Dialogue System for Spatial Question Answering in a Physical Blocks World
Nov 06, 2019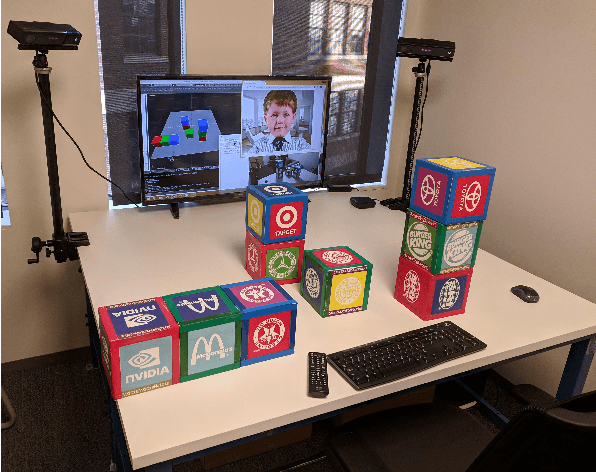

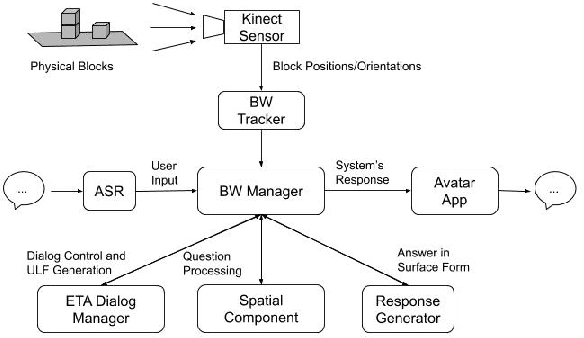
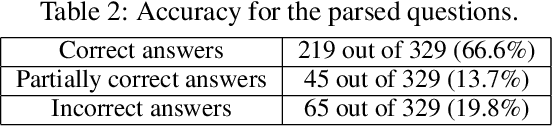
The blocks world is a classic toy domain that has long been used to build and test spatial reasoning systems. Despite its relative simplicity, tackling this domain in its full complexity requires the agent to exhibit a rich set of functional capabilities, ranging from vision to natural language understanding. There is currently a resurgence of interest in solving problems in such limited domains using modern techniques. In this work we tackle spatial question answering in a holistic way, using a vision system, speech input and output mediated by an animated avatar, a dialogue system that robustly interprets spatial queries, and a constraint solver that derives answers based on 3-D spatial modeling. The contributions of this work include a semantic parser that maps spatial questions into logical forms consistent with a general approach to meaning representation, a dialog manager based on a schema representation, and a constraint solver for spatial questions that provides answers in agreement with human perception. These and other components are integrated into a multi-modal human-computer interaction pipeline.
Discourse Behavior of Older Adults Interacting With a Dialogue Agent Competent in Multiple Topics
Jul 14, 2019
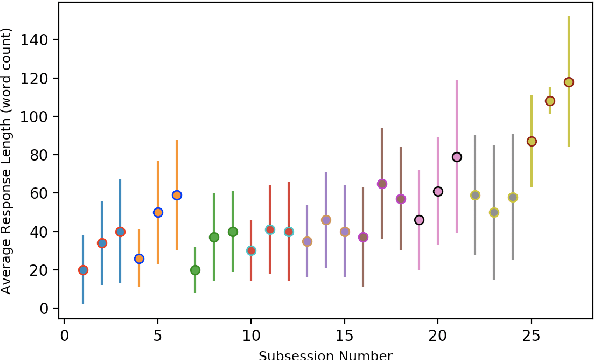

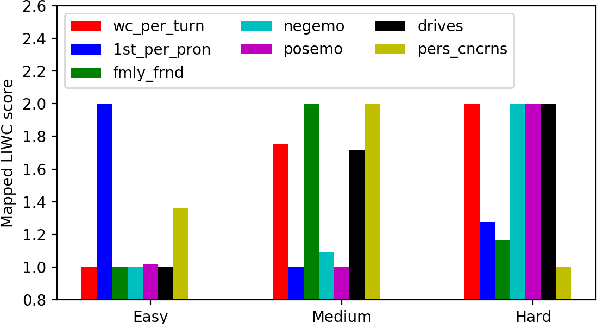
We present some results concerning the dialogue behavior and inferred sentiment of a group of older adults interacting with a computer-based avatar. Our avatar is unique in its ability to hold natural dialogues on a wide range of everyday topics---27 topics in three groups, developed with the help of gerontologists. The three groups vary in ``degrees of intimacy", and as such in degrees of difficulty for the user. Each participant interacted with the avatar for 7-9 sessions over a period of 3-4 weeks; analysis of the dialogues reveals correlations such as greater verbosity for more difficult topics, increasing verbosity with successive sessions, especially for more difficult topics, stronger sentiment on topics concerned with life goals rather than routine activities, and stronger self-disclosure for more intimate topics. In addition to their intrinsic interest, these results also reflect positively on the sophistication of our dialogue system.
Dialogue Design and Management for Multi-Session Casual Conversation with Older Adults
Jan 20, 2019
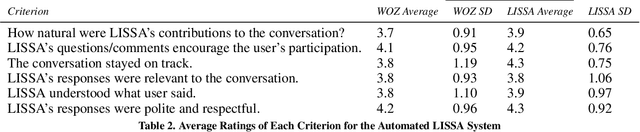
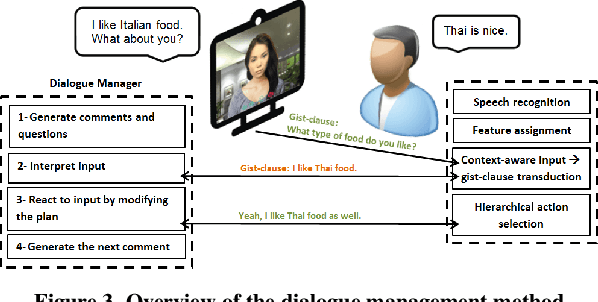
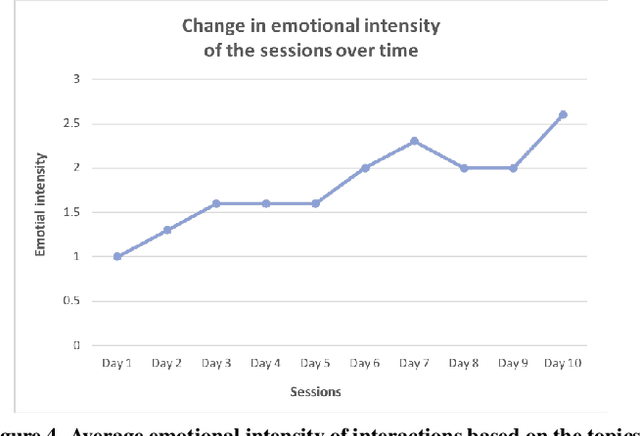
We address the problem of designing a conversational avatar capable of a sequence of casual conversations with older adults. Users at risk of loneliness, social anxiety or a sense of ennui may benefit from practicing such conversations in private, at their convenience. We describe an automatic spoken dialogue manager for LISSA, an on-screen virtual agent that can keep older users involved in conversations over several sessions, each lasting 10-20 minutes. The idea behind LISSA is to improve users' communication skills by providing feedback on their non-verbal behavior at certain points in the course of the conversations. In this paper, we analyze the dialogues collected from the first session between LISSA and each of 8 participants. We examine the quality of the conversations by comparing the transcripts with those collected in a WOZ setting. LISSA's contributions to the conversations were judged by research assistants who rated the extent to which the contributions were "natural", "on track", "encouraging", "understanding", "relevant", and "polite". The results show that the automatic dialogue manager was able to handle conversation with the users smoothly and naturally.