 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet the gist? Using large language models for few-shot decontextualization
Oct 10, 2023In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
We are what we repeatedly do: Inducing and deploying habitual schemas in persona-based responses
Oct 10, 2023Many practical applications of dialogue technology require the generation of responses according to a particular developer-specified persona. While a variety of personas can be elicited from recent large language models, the opaqueness and unpredictability of these models make it desirable to be able to specify personas in an explicit form. In previous work, personas have typically been represented as sets of one-off pieces of self-knowledge that are retrieved by the dialogue system for use in generation. However, in realistic human conversations, personas are often revealed through story-like narratives that involve rich habitual knowledge -- knowledge about kinds of events that an agent often participates in (e.g., work activities, hobbies, sporting activities, favorite entertainments, etc.), including typical goals, sub-events, preconditions, and postconditions of those events. We capture such habitual knowledge using an explicit schema representation, and propose an approach to dialogue generation that retrieves relevant schemas to condition a large language model to generate persona-based responses. Furthermore, we demonstrate a method for bootstrapping the creation of such schemas by first generating generic passages from a set of simple facts, and then inducing schemas from the generated passages.
A Flexible Schema-Guided Dialogue Management Framework: From Friendly Peer to Virtual Standardized Cancer Patient
Jul 15, 2022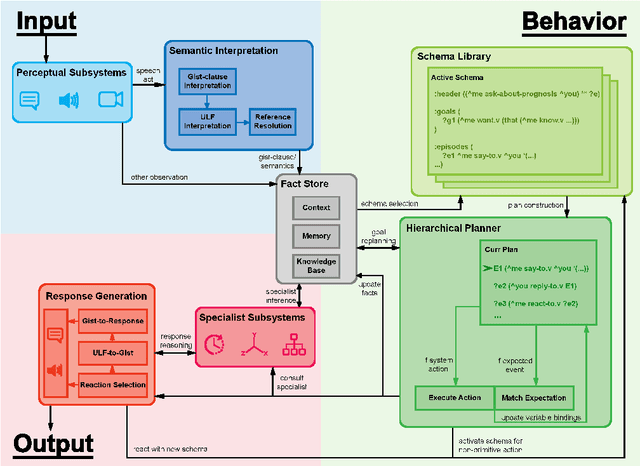
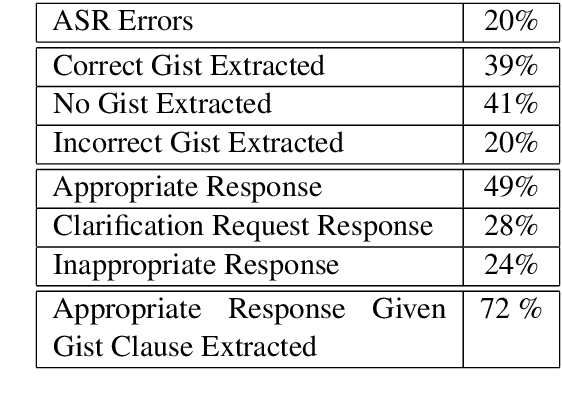

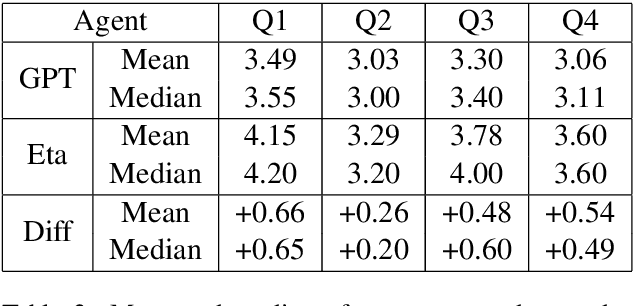
A schema-guided approach to dialogue management has been shown in recent work to be effective in creating robust customizable virtual agents capable of acting as friendly peers or task assistants. However, successful applications of these methods in open-ended, mixed-initiative domains remain elusive -- particularly within medical domains such as virtual standardized patients, where such complex interactions are commonplace -- and require more extensive and flexible dialogue management capabilities than previous systems provide. In this paper, we describe a general-purpose schema-guided dialogue management framework used to develop SOPHIE, a virtual standardized cancer patient that allows a doctor to conveniently practice for interactions with patients. We conduct a crowdsourced evaluation of conversations between medical students and SOPHIE. Our agent is judged to produce responses that are natural, emotionally appropriate, and consistent with her role as a cancer patient. Furthermore, it significantly outperforms an end-to-end neural model fine-tuned on a human standardized patient corpus, attesting to the advantages of a schema-guided approach.
Natural Language Inference with Mixed Effects
Oct 20, 2020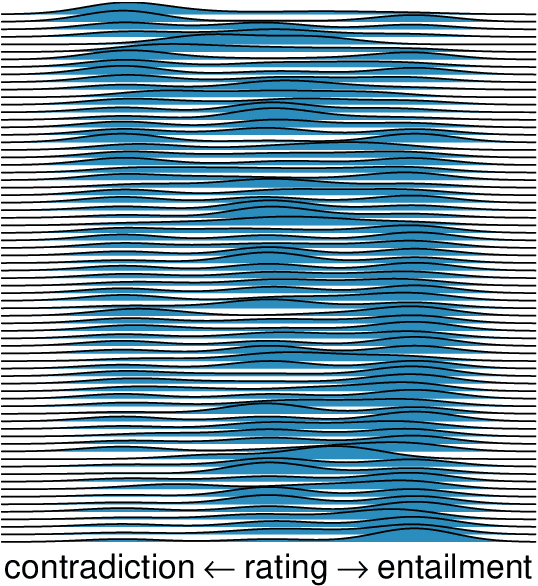
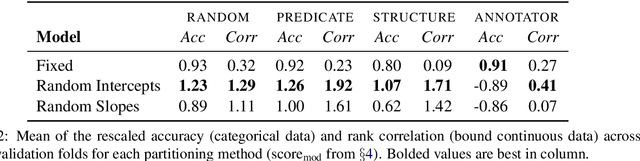
There is growing evidence that the prevalence of disagreement in the raw annotations used to construct natural language inference datasets makes the common practice of aggregating those annotations to a single label problematic. We propose a generic method that allows one to skip the aggregation step and train on the raw annotations directly without subjecting the model to unwanted noise that can arise from annotator response biases. We demonstrate that this method, which generalizes the notion of a \textit{mixed effects model} by incorporating \textit{annotator random effects} into any existing neural model, improves performance over models that do not incorporate such effects.
History-Aware Question Answering in a Blocks World Dialogue System
May 26, 2020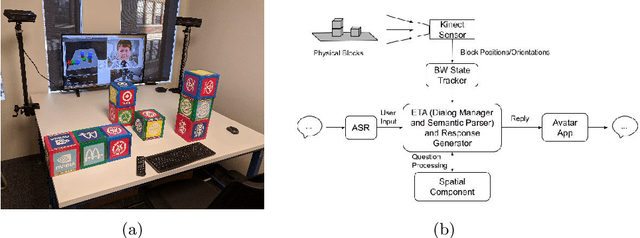
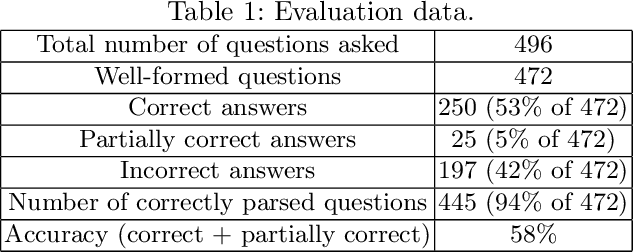
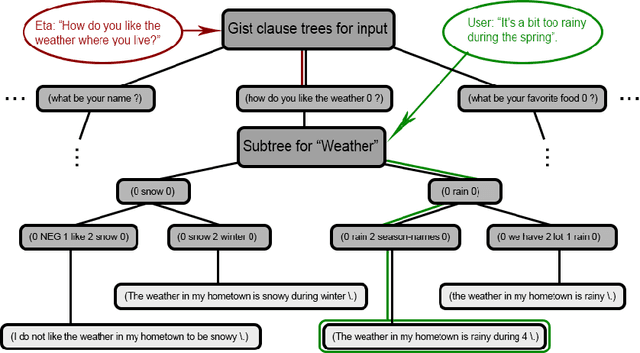
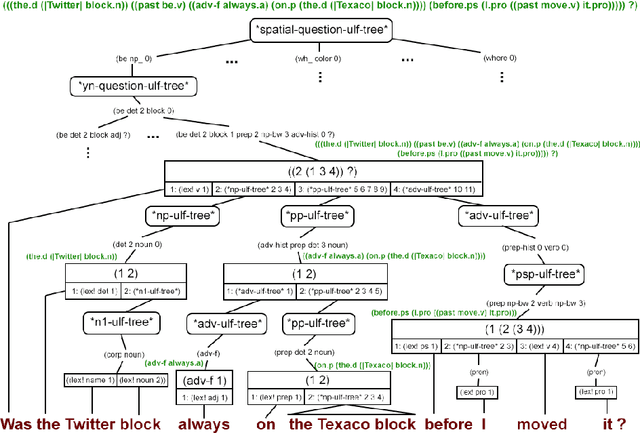
It is essential for dialogue-based spatial reasoning systems to maintain memory of historical states of the world. In addition to conveying that the dialogue agent is mentally present and engaged with the task, referring to historical states may be crucial for enabling collaborative planning (e.g., for planning to return to a previous state, or diagnosing a past misstep). In this paper, we approach the problem of spatial memory in a multi-modal spoken dialogue system capable of answering questions about interaction history in a physical blocks world setting. This work builds upon a full spatial question-answering pipeline consisting of a vision system, speech input and output mediated by an animated avatar, a dialogue system that robustly interprets spatial queries, and a constraint solver that derives answers based on 3-D spatial modelling. The contributions of this work include a symbolic dialogue context registering knowledge about discourse history and changes in the world, as well as a natural language understanding module capable of interpreting free-form historical questions and querying the dialogue context to form an answer.
A Spoken Dialogue System for Spatial Question Answering in a Physical Blocks World
Nov 06, 2019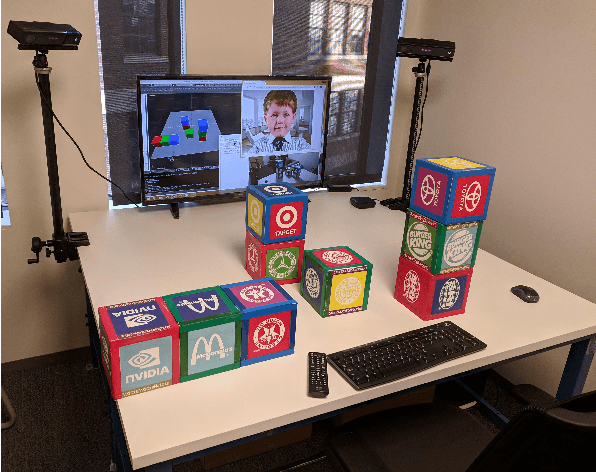

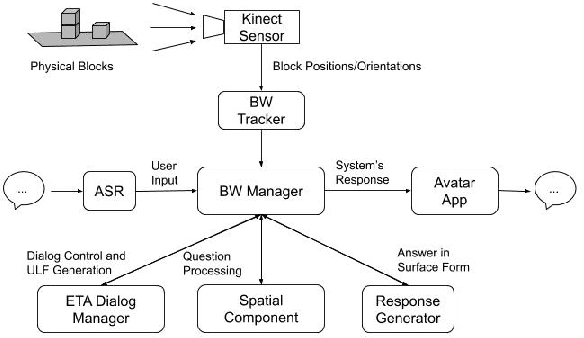
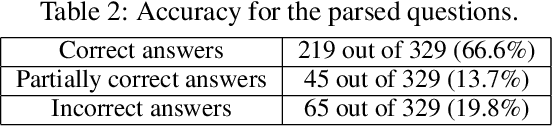
The blocks world is a classic toy domain that has long been used to build and test spatial reasoning systems. Despite its relative simplicity, tackling this domain in its full complexity requires the agent to exhibit a rich set of functional capabilities, ranging from vision to natural language understanding. There is currently a resurgence of interest in solving problems in such limited domains using modern techniques. In this work we tackle spatial question answering in a holistic way, using a vision system, speech input and output mediated by an animated avatar, a dialogue system that robustly interprets spatial queries, and a constraint solver that derives answers based on 3-D spatial modeling. The contributions of this work include a semantic parser that maps spatial questions into logical forms consistent with a general approach to meaning representation, a dialog manager based on a schema representation, and a constraint solver for spatial questions that provides answers in agreement with human perception. These and other components are integrated into a multi-modal human-computer interaction pipeline.
Dialogue Design and Management for Multi-Session Casual Conversation with Older Adults
Jan 20, 2019
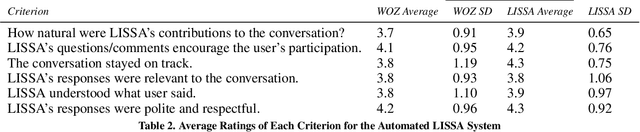
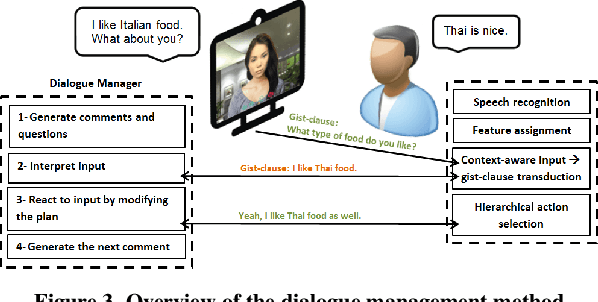
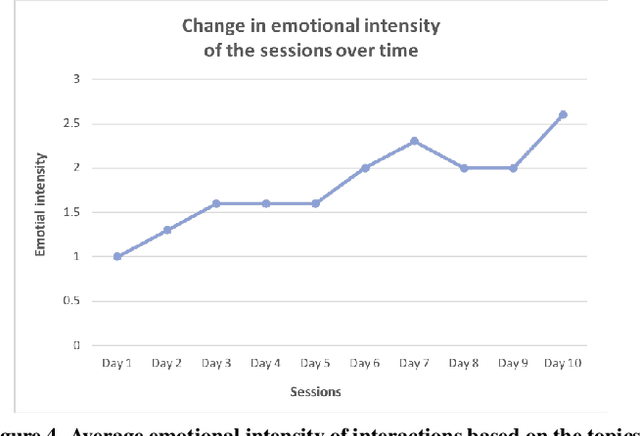
We address the problem of designing a conversational avatar capable of a sequence of casual conversations with older adults. Users at risk of loneliness, social anxiety or a sense of ennui may benefit from practicing such conversations in private, at their convenience. We describe an automatic spoken dialogue manager for LISSA, an on-screen virtual agent that can keep older users involved in conversations over several sessions, each lasting 10-20 minutes. The idea behind LISSA is to improve users' communication skills by providing feedback on their non-verbal behavior at certain points in the course of the conversations. In this paper, we analyze the dialogues collected from the first session between LISSA and each of 8 participants. We examine the quality of the conversations by comparing the transcripts with those collected in a WOZ setting. LISSA's contributions to the conversations were judged by research assistants who rated the extent to which the contributions were "natural", "on track", "encouraging", "understanding", "relevant", and "polite". The results show that the automatic dialogue manager was able to handle conversation with the users smoothly and naturally.