 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet the gist? Using large language models for few-shot decontextualization
Oct 10, 2023In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
We are what we repeatedly do: Inducing and deploying habitual schemas in persona-based responses
Oct 10, 2023Many practical applications of dialogue technology require the generation of responses according to a particular developer-specified persona. While a variety of personas can be elicited from recent large language models, the opaqueness and unpredictability of these models make it desirable to be able to specify personas in an explicit form. In previous work, personas have typically been represented as sets of one-off pieces of self-knowledge that are retrieved by the dialogue system for use in generation. However, in realistic human conversations, personas are often revealed through story-like narratives that involve rich habitual knowledge -- knowledge about kinds of events that an agent often participates in (e.g., work activities, hobbies, sporting activities, favorite entertainments, etc.), including typical goals, sub-events, preconditions, and postconditions of those events. We capture such habitual knowledge using an explicit schema representation, and propose an approach to dialogue generation that retrieves relevant schemas to condition a large language model to generate persona-based responses. Furthermore, we demonstrate a method for bootstrapping the creation of such schemas by first generating generic passages from a set of simple facts, and then inducing schemas from the generated passages.
A Flexible Schema-Guided Dialogue Management Framework: From Friendly Peer to Virtual Standardized Cancer Patient
Jul 15, 2022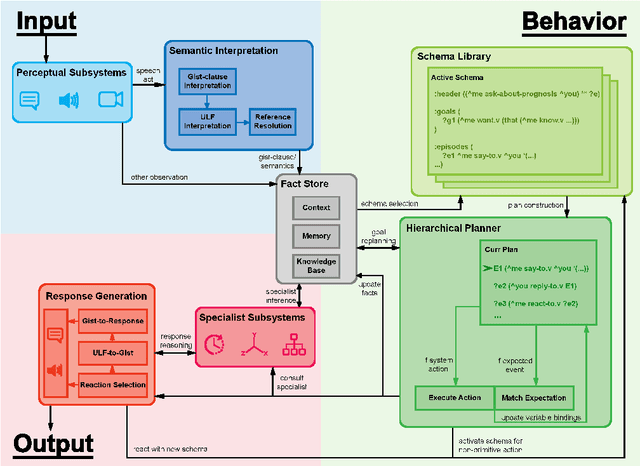
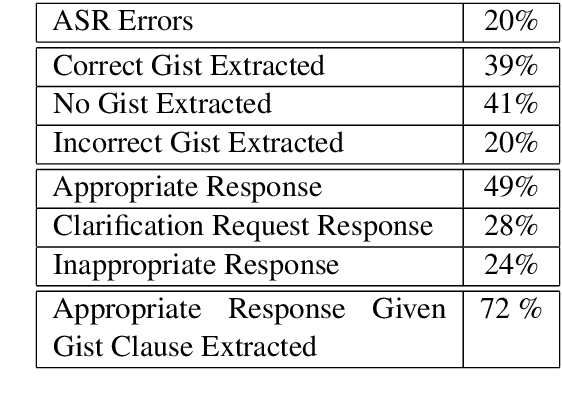

A schema-guided approach to dialogue management has been shown in recent work to be effective in creating robust customizable virtual agents capable of acting as friendly peers or task assistants. However, successful applications of these methods in open-ended, mixed-initiative domains remain elusive -- particularly within medical domains such as virtual standardized patients, where such complex interactions are commonplace -- and require more extensive and flexible dialogue management capabilities than previous systems provide. In this paper, we describe a general-purpose schema-guided dialogue management framework used to develop SOPHIE, a virtual standardized cancer patient that allows a doctor to conveniently practice for interactions with patients. We conduct a crowdsourced evaluation of conversations between medical students and SOPHIE. Our agent is judged to produce responses that are natural, emotionally appropriate, and consistent with her role as a cancer patient. Furthermore, it significantly outperforms an end-to-end neural model fine-tuned on a human standardized patient corpus, attesting to the advantages of a schema-guided approach.
Mining Logical Event Schemas From Pre-Trained Language Models
Apr 12, 2022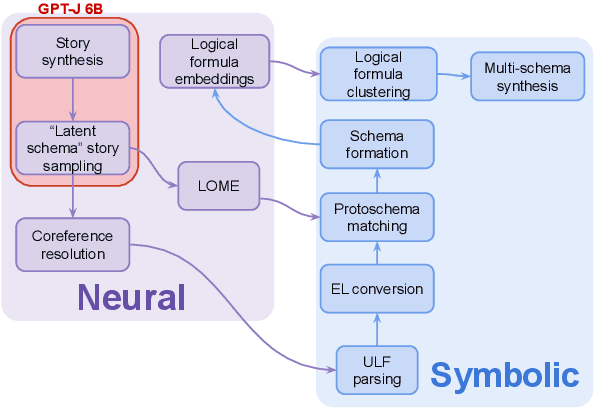
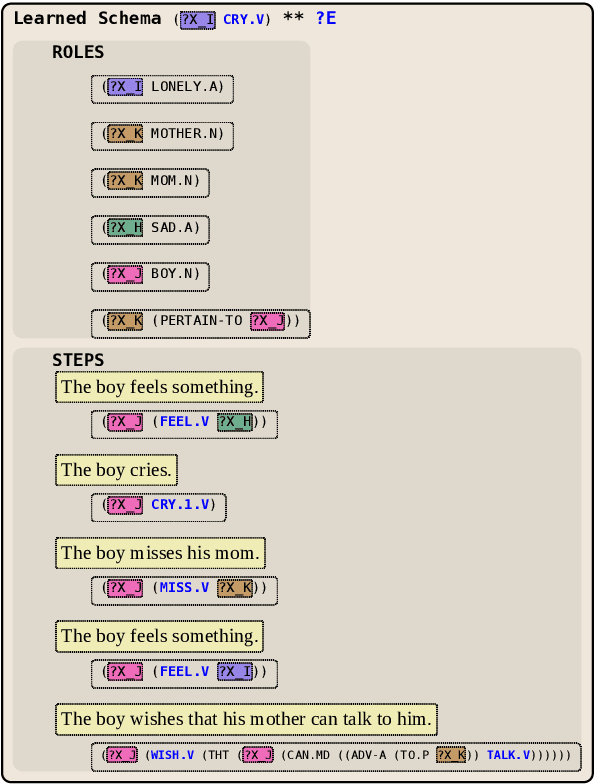
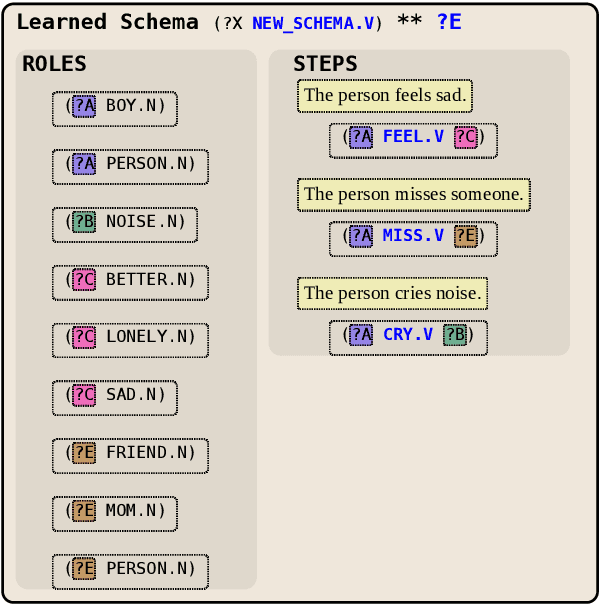
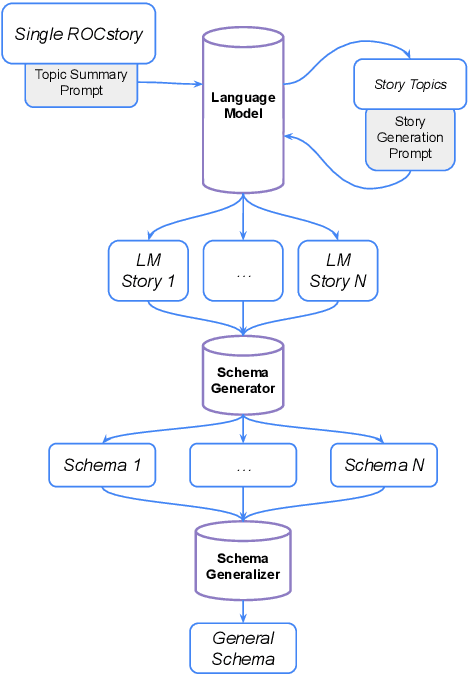
We present NESL (the Neuro-Episodic Schema Learner), an event schema learning system that combines large language models, FrameNet parsing, a powerful logical representation of language, and a set of simple behavioral schemas meant to bootstrap the learning process. In lieu of a pre-made corpus of stories, our dataset is a continuous feed of "situation samples" from a pre-trained language model, which are then parsed into FrameNet frames, mapped into simple behavioral schemas, and combined and generalized into complex, hierarchical schemas for a variety of everyday scenarios. We show that careful sampling from the language model can help emphasize stereotypical properties of situations and de-emphasize irrelevant details, and that the resulting schemas specify situations more comprehensively than those learned by other systems.
A Transition-based Parser for Unscoped Episodic Logical Forms
Mar 15, 2021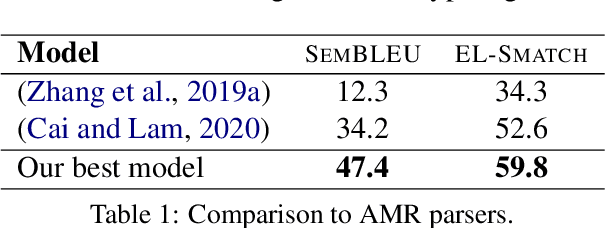
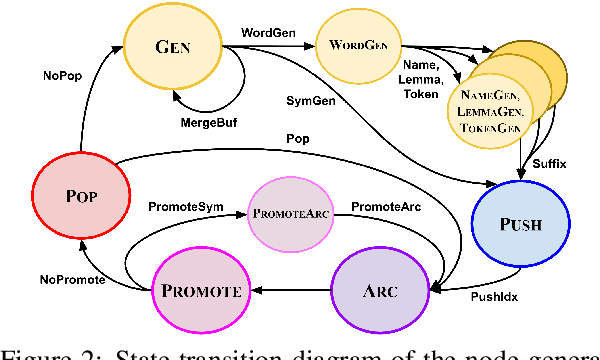

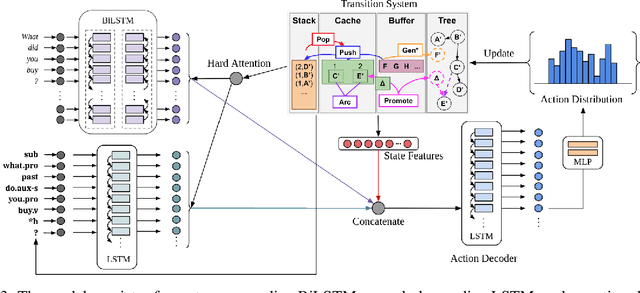
"Episodic Logic:Unscoped Logical Form" (EL-ULF) is a semantic representation capturing predicate-argument structure as well as more challenging aspects of language within the Episodic Logic formalism. We present the first learned approach for parsing sentences into ULFs, using a growing set of annotated examples. The results provide a strong baseline for future improvement. Our method learns a sequence-to-sequence model for predicting the transition action sequence within a modified cache transition system. We evaluate the efficacy of type grammar-based constraints, a word-to-symbol lexicon, and transition system state features in this task. Our system is available at https://github.com/genelkim/ulf-transition-parser We also present the first official annotated ULF dataset at https://www.cs.rochester.edu/u/gkim21/ulf/resources/.
A Type-coherent, Expressive Representation as an Initial Step to Language Understanding
Mar 28, 2019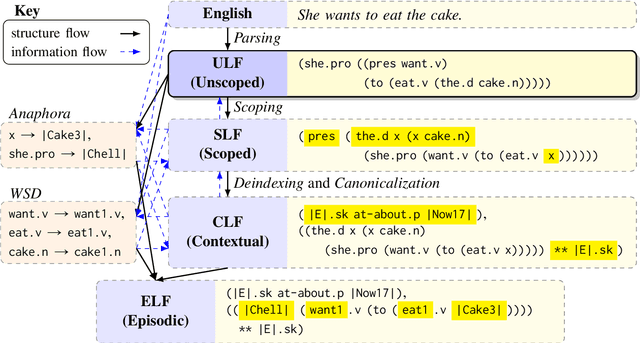
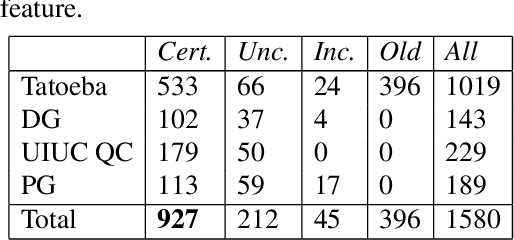
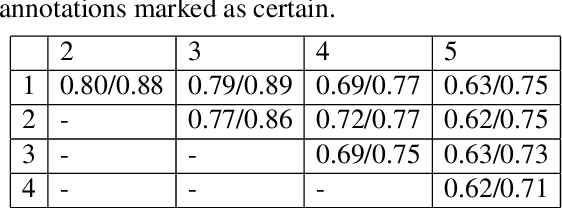

A growing interest in tasks involving language understanding by the NLP community has led to the need for effective semantic parsing and inference. Modern NLP systems use semantic representations that do not quite fulfill the nuanced needs for language understanding: adequately modeling language semantics, enabling general inferences, and being accurately recoverable. This document describes underspecified logical forms (ULF) for Episodic Logic (EL), which is an initial form for a semantic representation that balances these needs. ULFs fully resolve the semantic type structure while leaving issues such as quantifier scope, word sense, and anaphora unresolved; they provide a starting point for further resolution into EL, and enable certain structural inferences without further resolution. This document also presents preliminary results of creating a hand-annotated corpus of ULFs for the purpose of training a precise ULF parser, showing a three-person pairwise interannotator agreement of 0.88 on confident annotations. We hypothesize that a divide-and-conquer approach to semantic parsing starting with derivation of ULFs will lead to semantic analyses that do justice to subtle aspects of linguistic meaning, and will enable construction of more accurate semantic parsers.
A New Characterization of Probabilities in Bayesian Networks
Jul 11, 2012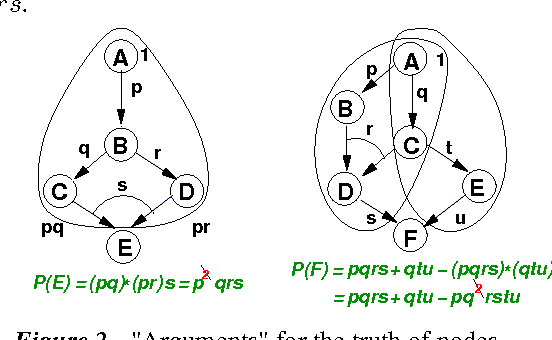
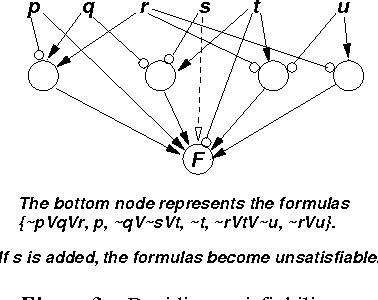
We characterize probabilities in Bayesian networks in terms of algebraic expressions called quasi-probabilities. These are arrived at by casting Bayesian networks as noisy AND-OR-NOT networks, and viewing the subnetworks that lead to a node as arguments for or against a node. Quasi-probabilities are in a sense the "natural" algebra of Bayesian networks: we can easily compute the marginal quasi-probability of any node recursively, in a compact form; and we can obtain the joint quasi-probability of any set of nodes by multiplying their marginals (using an idempotent product operator). Quasi-probabilities are easily manipulated to improve the efficiency of probabilistic inference. They also turn out to be representable as square-wave pulse trains, and joint and marginal distributions can be computed by multiplication and complementation of pulse trains.
Knowledge Representation for Lexical Semantics: Is Standard First Order Logic Enough?
Dec 10, 1994Natural language understanding applications such as interactive planning and face-to-face translation require extensive inferencing. Many of these inferences are based on the meaning of particular open class words. Providing a representation that can support such lexically-based inferences is a primary concern of lexical semantics. The representation language of first order logic has well-understood semantics and a multitude of inferencing systems have been implemented for it. Thus it is a prime candidate to serve as a lexical semantics representation. However, we argue that FOL, although a good starting point, needs to be extended before it can efficiently and concisely support all the lexically-based inferences needed.