Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Inference with Mixed Effects
Paper and Code
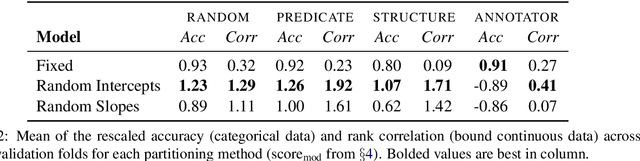
There is growing evidence that the prevalence of disagreement in the raw annotations used to construct natural language inference datasets makes the common practice of aggregating those annotations to a single label problematic. We propose a generic method that allows one to skip the aggregation step and train on the raw annotations directly without subjecting the model to unwanted noise that can arise from annotator response biases. We demonstrate that this method, which generalizes the notion of a \textit{mixed effects model} by incorporating \textit{annotator random effects} into any existing neural model, improves performance over models that do not incorporate such effects.
* The Ninth Joint Conference on Lexical and Computational Semantics
(*SEM2020)
View paper on