 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Mitigation of Worst-Case LLM Copyright Infringement
Paper and Code
Apr 22, 2025

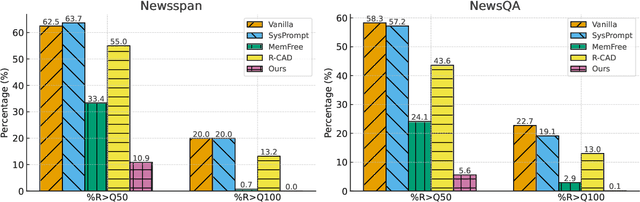
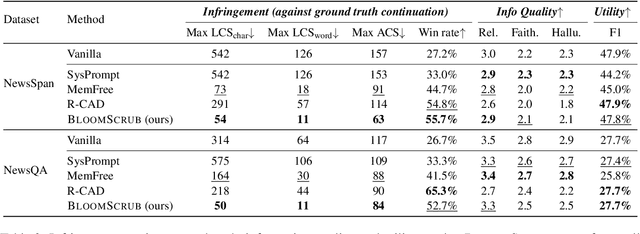
The exposure of large language models (LLMs) to copyrighted material during pre-training raises concerns about unintentional copyright infringement post deployment. This has driven the development of "copyright takedown" methods, post-training approaches aimed at preventing models from generating content substantially similar to copyrighted ones. While current mitigation approaches are somewhat effective for average-case risks, we demonstrate that they overlook worst-case copyright risks exhibits by the existence of long, verbatim quotes from copyrighted sources. We propose BloomScrub, a remarkably simple yet highly effective inference-time approach that provides certified copyright takedown. Our method repeatedly interleaves quote detection with rewriting techniques to transform potentially infringing segments. By leveraging efficient data sketches (Bloom filters), our approach enables scalable copyright screening even for large-scale real-world corpora. When quotes beyond a length threshold cannot be removed, the system can abstain from responding, offering certified risk reduction. Experimental results show that BloomScrub reduces infringement risk, preserves utility, and accommodates different levels of enforcement stringency with adaptive abstention. Our results suggest that lightweight, inference-time methods can be surprisingly effective for copyright prevention.