 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHán Dān Xué Bù (Mimicry) or Qīng Chū Yú Lán (Mastery)? A Cognitive Perspective on Reasoning Distillation in Large Language Models
Jan 08, 2026Recent Large Reasoning Models trained via reinforcement learning exhibit a "natural" alignment with human cognitive costs. However, we show that the prevailing paradigm of reasoning distillation -- training student models to mimic these traces via Supervised Fine-Tuning (SFT) -- fails to transmit this cognitive structure. Testing the "Hán Dān Xué Bù" (Superficial Mimicry) hypothesis across 14 models, we find that distillation induces a "Functional Alignment Collapse": while teacher models mirror human difficulty scaling ($\bar{r}=0.64$), distilled students significantly degrade this alignment ($\bar{r}=0.34$), often underperforming their own pre-distillation baselines ("Negative Transfer"). Our analysis suggests that SFT induces a "Cargo Cult" effect, where students ritualistically replicate the linguistic form of reasoning (verbosity) without internalizing the teacher's dynamic resource allocation policy. Consequently, reasoning distillation decouples computational cost from cognitive demand, revealing that human-like cognition is an emergent property of active reinforcement, not passive imitation.
Explain EEG-based End-to-end Deep Learning Models in the Frequency Domain
Jul 25, 2024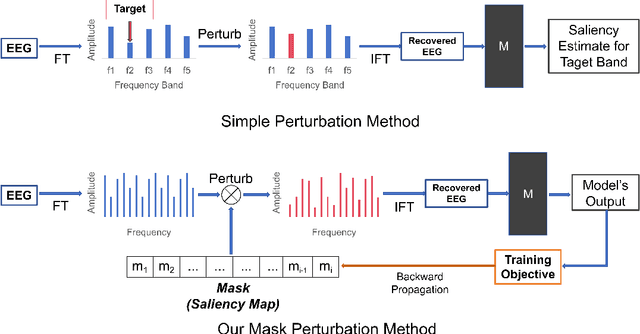

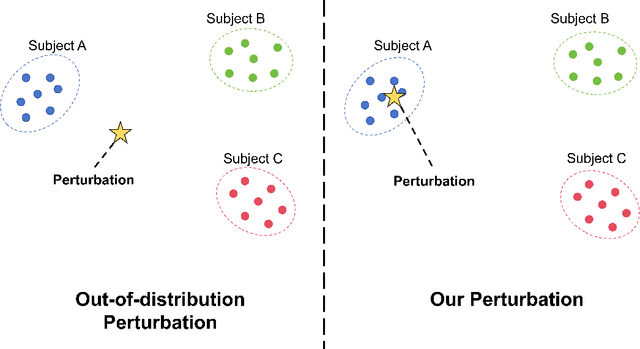

The recent rise of EEG-based end-to-end deep learning models presents a significant challenge in elucidating how these models process raw EEG signals and generate predictions in the frequency domain. This challenge limits the transparency and credibility of EEG-based end-to-end models, hindering their application in security-sensitive areas. To address this issue, we propose a mask perturbation method to explain the behavior of end-to-end models in the frequency domain. Considering the characteristics of EEG data, we introduce a target alignment loss to mitigate the out-of-distribution problem associated with perturbation operations. Additionally, we develop a perturbation generator to define perturbation generation in the frequency domain. Our explanation method is validated through experiments on multiple representative end-to-end deep learning models in the EEG decoding field, using an established EEG benchmark dataset. The results demonstrate the effectiveness and superiority of our method, and highlight its potential to advance research in EEG-based end-to-end models.
Cascaded Self-supervised Learning for Subject-independent EEG-based Emotion Recognition
Mar 06, 2024



EEG-based Emotion recognition holds significant promise for applications in human-computer interaction, medicine, and neuroscience. While deep learning has shown potential in this field, current approaches usually rely on large-scale high-quality labeled datasets, limiting the performance of deep learning. Self-supervised learning offers a solution by automatically generating labels, but its inter-subject generalizability remains under-explored. For this reason, our interest lies in offering a self-supervised learning paradigm with better inter-subject generalizability. Inspired by recent efforts in combining low-level and high-level tasks in deep learning, we propose a cascaded self-supervised architecture for EEG emotion recognition. Then, we introduce a low-level task, time-to-frequency reconstruction (TFR). This task leverages the inherent time-frequency relationship in EEG signals. Our architecture integrates it with the high-level contrastive learning modules, performing self-supervised learning for EEG-based emotion recognition. Experiment on DEAP and DREAMER datasets demonstrates superior performance of our method over similar works. The outcome results also highlight the indispensability of the TFR task and the robustness of our method to label scarcity, validating the effectiveness of the proposed method.
Spatio-Temporal Domain Awareness for Multi-Agent Collaborative Perception
Aug 01, 2023



Multi-agent collaborative perception as a potential application for vehicle-to-everything communication could significantly improve the perception performance of autonomous vehicles over single-agent perception. However, several challenges remain in achieving pragmatic information sharing in this emerging research. In this paper, we propose SCOPE, a novel collaborative perception framework that aggregates the spatio-temporal awareness characteristics across on-road agents in an end-to-end manner. Specifically, SCOPE has three distinct strengths: i) it considers effective semantic cues of the temporal context to enhance current representations of the target agent; ii) it aggregates perceptually critical spatial information from heterogeneous agents and overcomes localization errors via multi-scale feature interactions; iii) it integrates multi-source representations of the target agent based on their complementary contributions by an adaptive fusion paradigm. To thoroughly evaluate SCOPE, we consider both real-world and simulated scenarios of collaborative 3D object detection tasks on three datasets. Extensive experiments demonstrate the superiority of our approach and the necessity of the proposed components.
A novel efficient Multi-view traffic-related object detection framework
Feb 23, 2023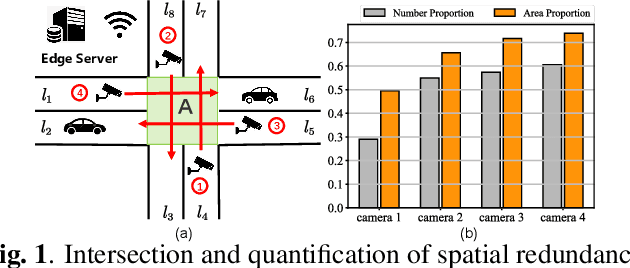
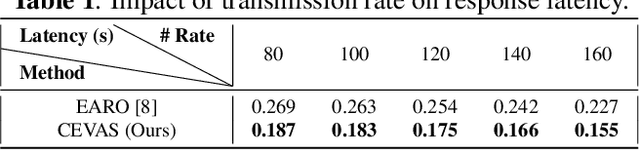

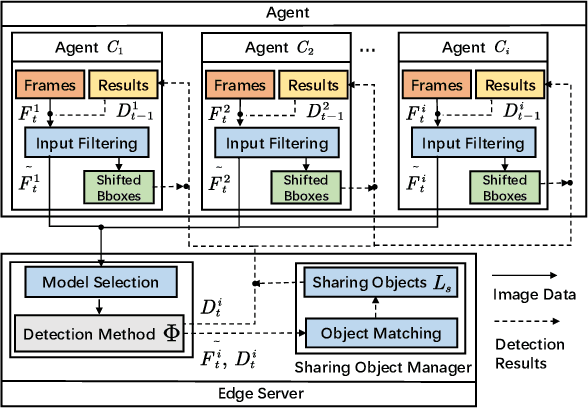
With the rapid development of intelligent transportation system applications, a tremendous amount of multi-view video data has emerged to enhance vehicle perception. However, performing video analytics efficiently by exploiting the spatial-temporal redundancy from video data remains challenging. Accordingly, we propose a novel traffic-related framework named CEVAS to achieve efficient object detection using multi-view video data. Briefly, a fine-grained input filtering policy is introduced to produce a reasonable region of interest from the captured images. Also, we design a sharing object manager to manage the information of objects with spatial redundancy and share their results with other vehicles. We further derive a content-aware model selection policy to select detection methods adaptively. Experimental results show that our framework significantly reduces response latency while achieving the same detection accuracy as the state-of-the-art methods.
Rethinking Saliency Map: An Context-aware Perturbation Method to Explain EEG-based Deep Learning Model
May 30, 2022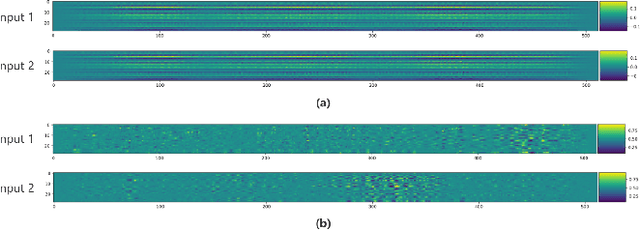
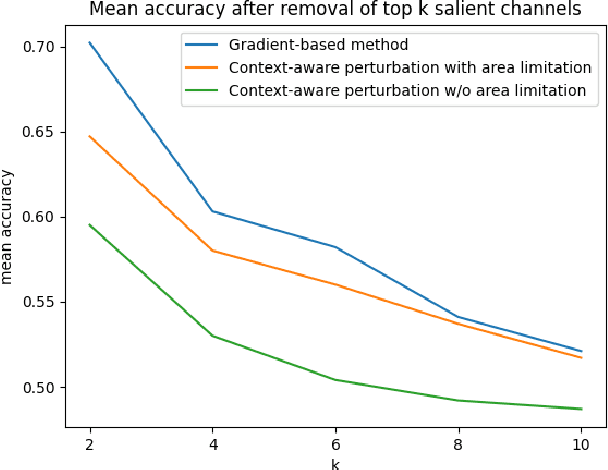
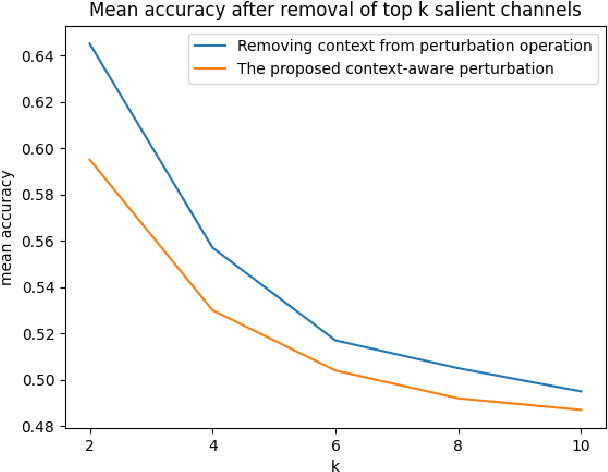
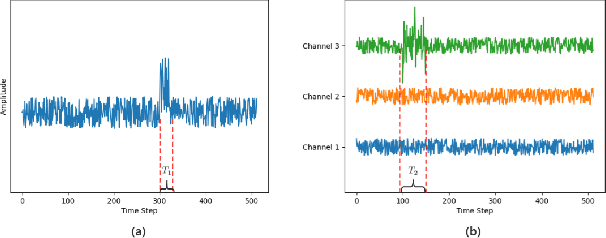
Deep learning is widely used to decode the electroencephalogram (EEG) signal. However, there are few attempts to specifically investigate how to explain the EEG-based deep learning models. We conduct a review to summarize the existing works explaining the EEG-based deep learning model. Unfortunately, we find that there is no appropriate method to explain them. Based on the characteristic of EEG data, we suggest a context-aware perturbation method to generate a saliency map from the perspective of the raw EEG signal. Moreover, we also justify that the context information can be used to suppress the artifacts in the EEG-based deep learning model. In practice, some users might want a simple version of the explanation, which only indicates a few features as salient points. To this end, we propose an optional area limitation strategy to restrict the highlighted region. To validate our idea and make a comparison with the other methods, we select three representative EEG-based models to implement experiments on the emotional EEG dataset DEAP. The results of the experiments support the advantages of our method.