 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Safe Robot Manipulation: From Semantic Scene Understanding to Motion Safeguards
Oct 19, 2024



Ensuring safe interactions in human-centric environments requires robots to understand and adhere to constraints recognized by humans as "common sense" (e.g., "moving a cup of water above a laptop is unsafe as the water may spill" or "rotating a cup of water is unsafe as it can lead to pouring its content"). Recent advances in computer vision and machine learning have enabled robots to acquire a semantic understanding of and reason about their operating environments. While extensive literature on safe robot decision-making exists, semantic understanding is rarely integrated into these formulations. In this work, we propose a semantic safety filter framework to certify robot inputs with respect to semantically defined constraints (e.g., unsafe spatial relationships, behaviours, and poses) and geometrically defined constraints (e.g., environment-collision and self-collision constraints). In our proposed approach, given perception inputs, we build a semantic map of the 3D environment and leverage the contextual reasoning capabilities of large language models to infer semantically unsafe conditions. These semantically unsafe conditions are then mapped to safe actions through a control barrier certification formulation. We evaluated our semantic safety filter approach in teleoperated tabletop manipulation tasks and pick-and-place tasks, demonstrating its effectiveness in incorporating semantic constraints to ensure safe robot operation beyond collision avoidance.
A novel efficient Multi-view traffic-related object detection framework
Feb 23, 2023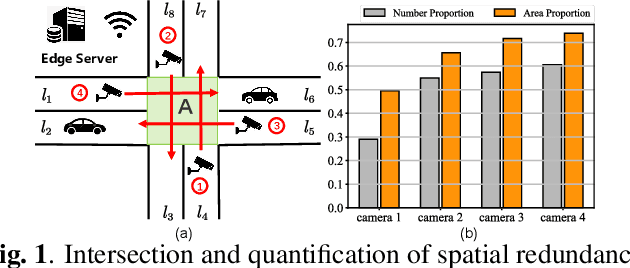
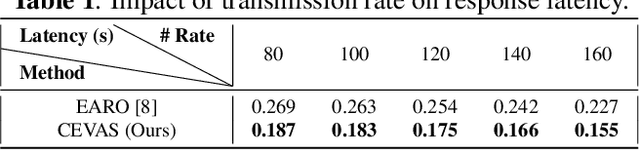

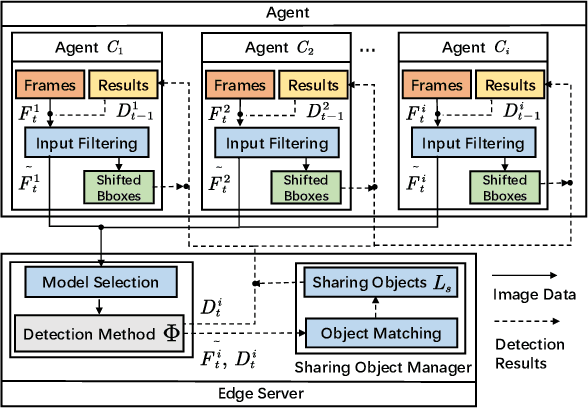
With the rapid development of intelligent transportation system applications, a tremendous amount of multi-view video data has emerged to enhance vehicle perception. However, performing video analytics efficiently by exploiting the spatial-temporal redundancy from video data remains challenging. Accordingly, we propose a novel traffic-related framework named CEVAS to achieve efficient object detection using multi-view video data. Briefly, a fine-grained input filtering policy is introduced to produce a reasonable region of interest from the captured images. Also, we design a sharing object manager to manage the information of objects with spatial redundancy and share their results with other vehicles. We further derive a content-aware model selection policy to select detection methods adaptively. Experimental results show that our framework significantly reduces response latency while achieving the same detection accuracy as the state-of-the-art methods.
Multi-scale frequency separation network for image deblurring
Jun 01, 2022

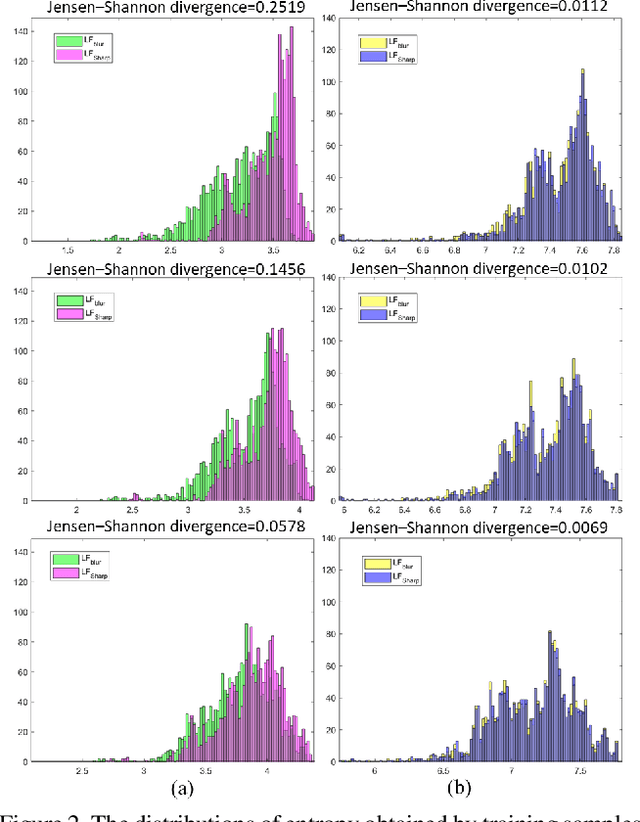
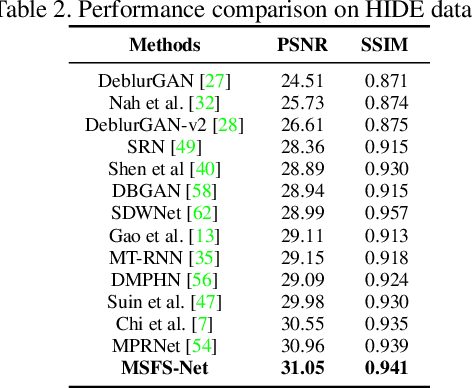
Image deblurring aims to restore the detailed texture information or structures from the blurry images, which has become an indispensable step in many computer-vision tasks. Although various methods have been proposed to deal with the image deblurring problem, most of them treated the blurry image as a whole and neglected the characteristics of different image frequencies. In this paper, we present a new method called multi-scale frequency separation network (MSFS-Net) for image deblurring. MSFS-Net introduces the frequency separation module (FSM) into an encoder-decoder network architecture to capture the low and high-frequency information of image at multiple scales. Then, a simple cycle-consistency strategy and a sophisticated contrastive learning module (CLM) are respectively designed to retain the low-frequency information and recover the high-frequency information during deblurring. At last, the features of different scales are fused by a cross-scale feature fusion module (CSFFM). Extensive experiments on benchmark datasets show that the proposed network achieves state-of-the-art performance.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021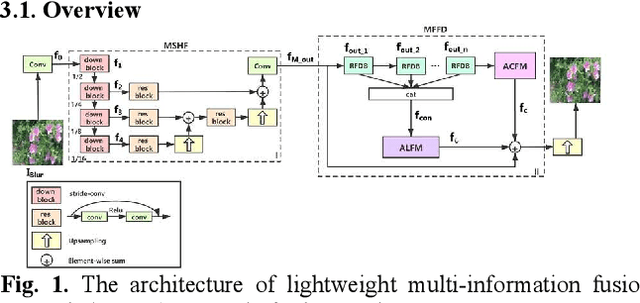
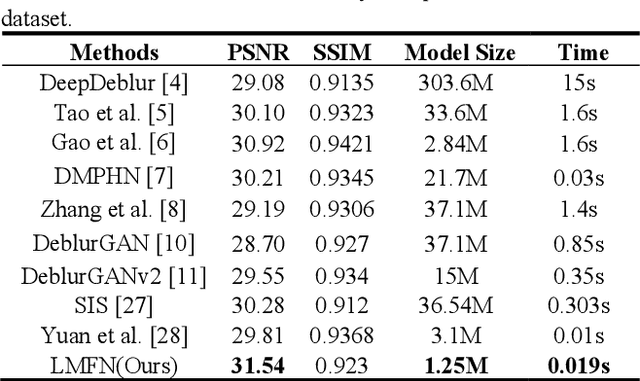
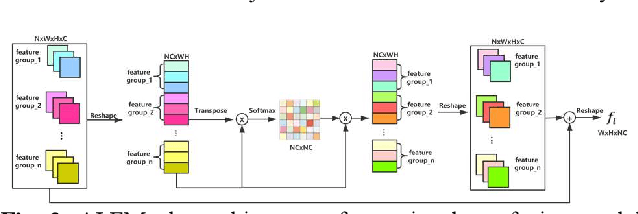

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.