 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDNet: Physics-Inspired Neural Network for Flow Estimation based on Helmholtz Decomposition
Jun 12, 2024



Flow estimation problems are ubiquitous in scientific imaging. Often, the underlying flows are subject to physical constraints that can be exploited in the flow estimation; for example, incompressible (divergence-free) flows are expected for many fluid experiments, while irrotational (curl-free) flows arise in the analysis of optical distortions and wavefront sensing. In this work, we propose a Physics- Inspired Neural Network (PINN) named HDNet, which performs a Helmholtz decomposition of an arbitrary flow field, i.e., it decomposes the input flow into a divergence-only and a curl-only component. HDNet can be trained exclusively on synthetic data generated by reverse Helmholtz decomposition, which we call Helmholtz synthesis. As a PINN, HDNet is fully differentiable and can easily be integrated into arbitrary flow estimation problems.
Multi-scale frequency separation network for image deblurring
Jun 01, 2022

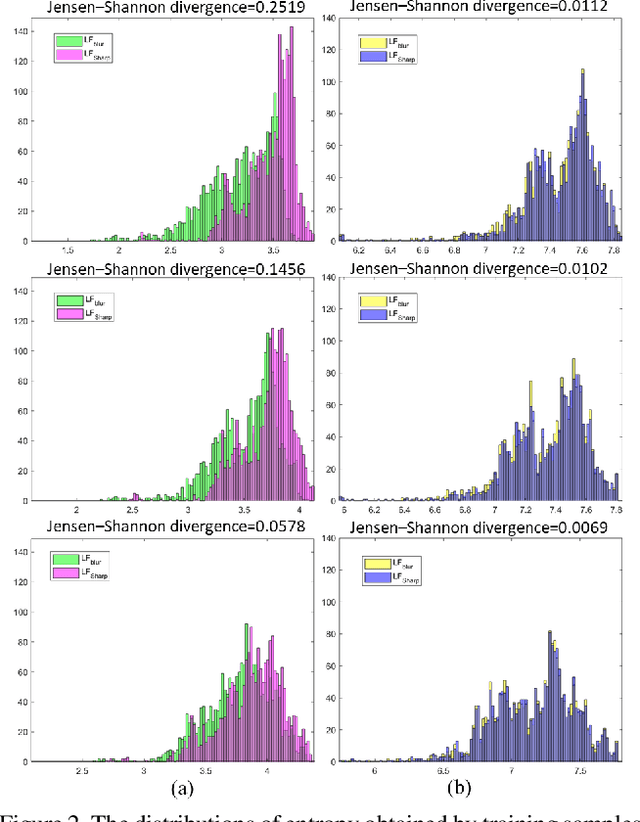
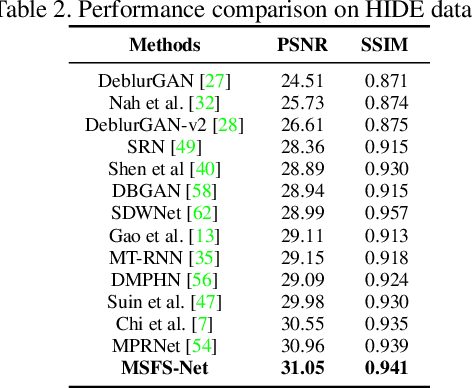
Image deblurring aims to restore the detailed texture information or structures from the blurry images, which has become an indispensable step in many computer-vision tasks. Although various methods have been proposed to deal with the image deblurring problem, most of them treated the blurry image as a whole and neglected the characteristics of different image frequencies. In this paper, we present a new method called multi-scale frequency separation network (MSFS-Net) for image deblurring. MSFS-Net introduces the frequency separation module (FSM) into an encoder-decoder network architecture to capture the low and high-frequency information of image at multiple scales. Then, a simple cycle-consistency strategy and a sophisticated contrastive learning module (CLM) are respectively designed to retain the low-frequency information and recover the high-frequency information during deblurring. At last, the features of different scales are fused by a cross-scale feature fusion module (CSFFM). Extensive experiments on benchmark datasets show that the proposed network achieves state-of-the-art performance.
ISP-Agnostic Image Reconstruction for Under-Display Cameras
Nov 02, 2021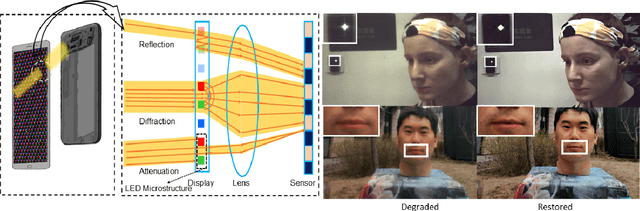

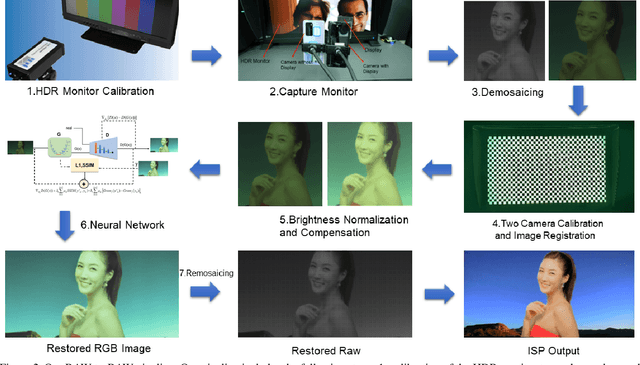
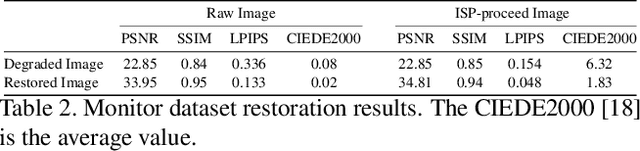
Under-display cameras have been proposed in recent years as a way to reduce the form factor of mobile devices while maximizing the screen area. Unfortunately, placing the camera behind the screen results in significant image distortions, including loss of contrast, blur, noise, color shift, scattering artifacts, and reduced light sensitivity. In this paper, we propose an image-restoration pipeline that is ISP-agnostic, i.e. it can be combined with any legacy ISP to produce a final image that matches the appearance of regular cameras using the same ISP. This is achieved with a deep learning approach that performs a RAW-to-RAW image restoration. To obtain large quantities of real under-display camera training data with sufficient contrast and scene diversity, we furthermore develop a data capture method utilizing an HDR monitor, as well as a data augmentation method to generate suitable HDR content. The monitor data is supplemented with real-world data that has less scene diversity but allows us to achieve fine detail recovery without being limited by the monitor resolution. Together, this approach successfully restores color and contrast as well as image detail.
Shape and Reflectance Reconstruction in Uncontrolled Environments by Differentiable Rendering
Oct 25, 2021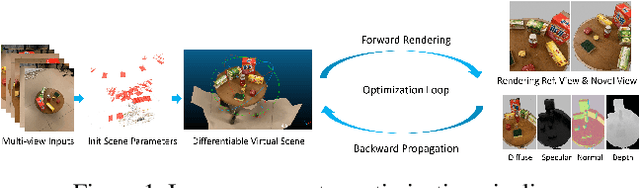
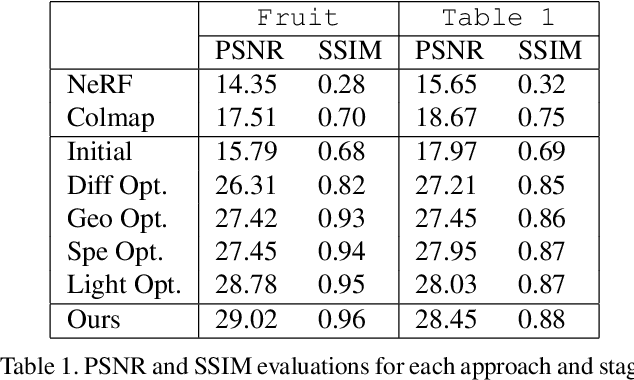


Simultaneous reconstruction of geometry and reflectance properties in uncontrolled environments remains a challenging problem. In this paper, we propose an efficient method to reconstruct the scene's 3D geometry and reflectance from multi-view photography using conventional hand-held cameras. Our method automatically builds a virtual scene in a differentiable rendering system that roughly matches the real world's scene parameters, optimized by minimizing photometric objectives alternatingly and stochastically. With the optimal scene parameters evaluated, photo-realistic novel views for various viewing angles and distances can then be generated by our approach. We present the results of captured scenes with complex geometry and various reflection types. Our method also shows superior performance compared to state-of-the-art alternatives in novel view synthesis visually and quantitatively.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021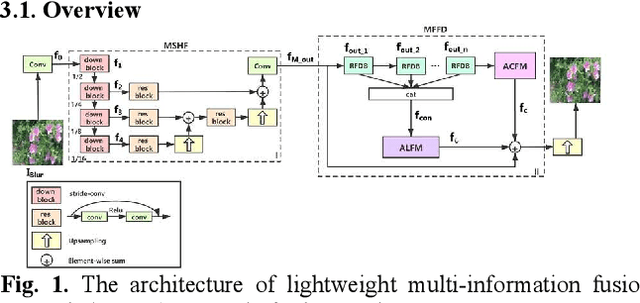
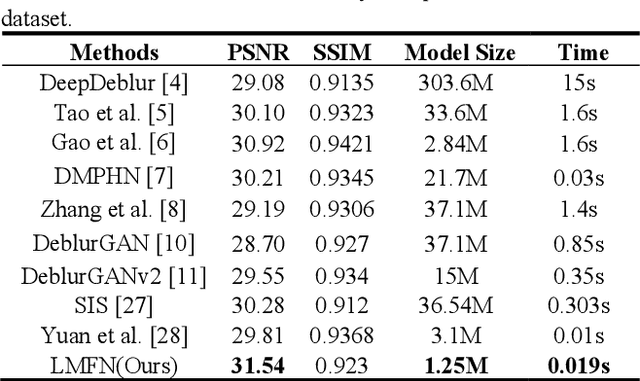
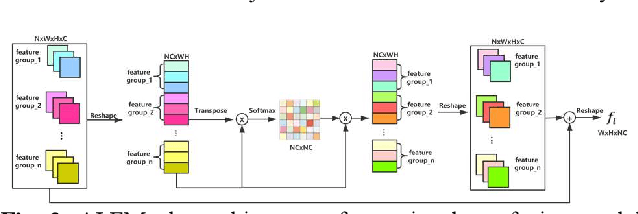

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
Making Study Populations Visible through Knowledge Graphs
Jul 09, 2019

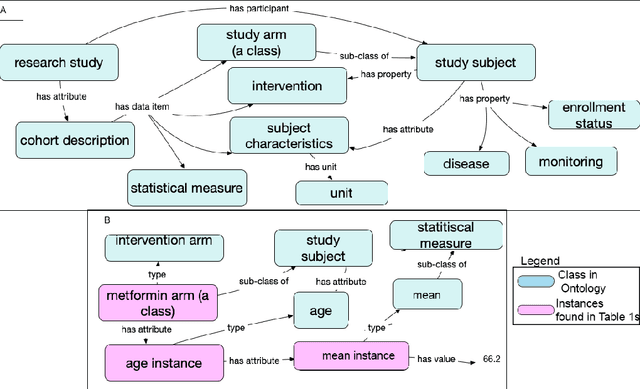
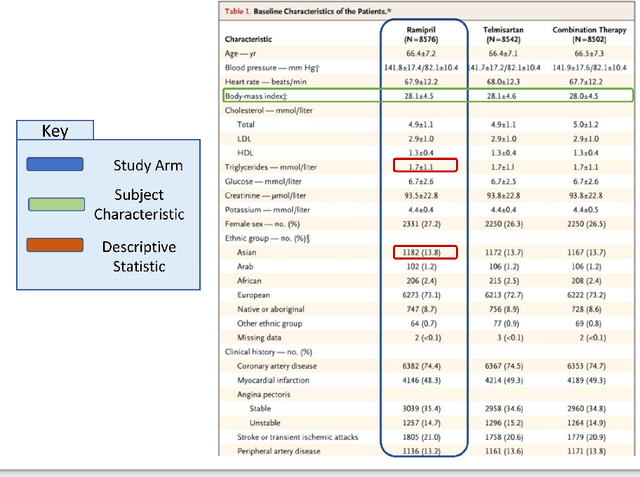
Treatment recommendations within Clinical Practice Guidelines (CPGs) are largely based on findings from clinical trials and case studies, referred to here as research studies, that are often based on highly selective clinical populations, referred to here as study cohorts. When medical practitioners apply CPG recommendations, they need to understand how well their patient population matches the characteristics of those in the study cohort, and thus are confronted with the challenges of locating the study cohort information and making an analytic comparison. To address these challenges, we develop an ontology-enabled prototype system, which exposes the population descriptions in research studies in a declarative manner, with the ultimate goal of allowing medical practitioners to better understand the applicability and generalizability of treatment recommendations. We build a Study Cohort Ontology (SCO) to encode the vocabulary of study population descriptions, that are often reported in the first table in the published work, thus they are often referred to as Table 1. We leverage the well-used Semanticscience Integrated Ontology (SIO) for defining property associations between classes. Further, we model the key components of Table 1s, i.e., collections of study subjects, subject characteristics, and statistical measures in RDF knowledge graphs. We design scenarios for medical practitioners to perform population analysis, and generate cohort similarity visualizations to determine the applicability of a study population to the clinical population of interest. Our semantic approach to make study populations visible, by standardized representations of Table 1s, allows users to quickly derive clinically relevant inferences about study populations.