 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny Resolution Any Geometry: From Multi-View To Multi-Patch
Mar 03, 2026Joint estimation of surface normals and depth is essential for holistic 3D scene understanding, yet high-resolution prediction remains difficult due to the trade-off between preserving fine local detail and maintaining global consistency. To address this challenge, we propose the Ultra Resolution Geometry Transformer (URGT), which adapts the Visual Geometry Grounded Transformer (VGGT) into a unified multi-patch transformer for monocular high-resolution depth--normal estimation. A single high-resolution image is partitioned into patches that are augmented with coarse depth and normal priors from pre-trained models, and jointly processed in a single forward pass to predict refined geometric outputs. Global coherence is enforced through cross-patch attention, which enables long-range geometric reasoning and seamless propagation of information across patches within a shared backbone. To further enhance spatial robustness, we introduce a GridMix patch sampling strategy that probabilistically samples grid configurations during training, improving inter-patch consistency and generalization. Our method achieves state-of-the-art results on UnrealStereo4K, jointly improving depth and normal estimation, reducing AbsRel from 0.0582 to 0.0291, RMSE from 2.17 to 1.31, and lowering mean angular error from 23.36 degrees to 18.51 degrees, while producing sharper and more stable geometry. The proposed multi-patch framework also demonstrates strong zero-shot and cross-domain generalization and scales effectively to very high resolutions, offering an efficient and extensible solution for high-quality geometry refinement.
HDNet: Physics-Inspired Neural Network for Flow Estimation based on Helmholtz Decomposition
Jun 12, 2024



Flow estimation problems are ubiquitous in scientific imaging. Often, the underlying flows are subject to physical constraints that can be exploited in the flow estimation; for example, incompressible (divergence-free) flows are expected for many fluid experiments, while irrotational (curl-free) flows arise in the analysis of optical distortions and wavefront sensing. In this work, we propose a Physics- Inspired Neural Network (PINN) named HDNet, which performs a Helmholtz decomposition of an arbitrary flow field, i.e., it decomposes the input flow into a divergence-only and a curl-only component. HDNet can be trained exclusively on synthetic data generated by reverse Helmholtz decomposition, which we call Helmholtz synthesis. As a PINN, HDNet is fully differentiable and can easily be integrated into arbitrary flow estimation problems.
Neural Adaptive SCEne Tracing
Mar 16, 2022
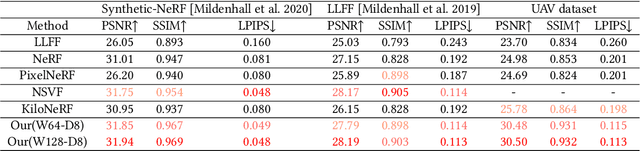
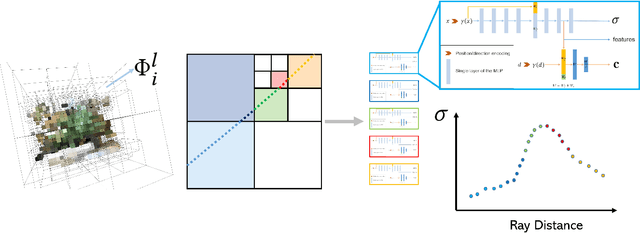
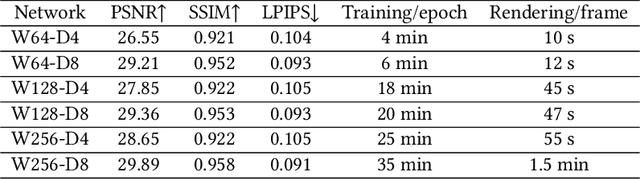
Neural rendering with implicit neural networks has recently emerged as an attractive proposition for scene reconstruction, achieving excellent quality albeit at high computational cost. While the most recent generation of such methods has made progress on the rendering (inference) times, very little progress has been made on improving the reconstruction (training) times. In this work, we present Neural Adaptive Scene Tracing (NAScenT), the first neural rendering method based on directly training a hybrid explicit-implicit neural representation. NAScenT uses a hierarchical octree representation with one neural network per leaf node and combines this representation with a two-stage sampling process that concentrates ray samples where they matter most near object surfaces. As a result, NAScenT is capable of reconstructing challenging scenes including both large, sparsely populated volumes like UAV captured outdoor environments, as well as small scenes with high geometric complexity. NAScenT outperforms existing neural rendering approaches in terms of both quality and training time.
NeAT: Neural Adaptive Tomography
Feb 04, 2022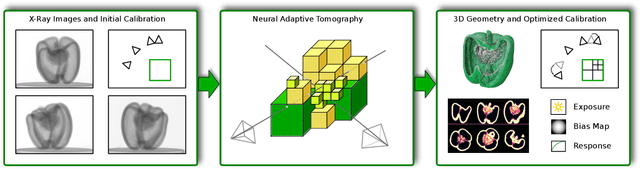
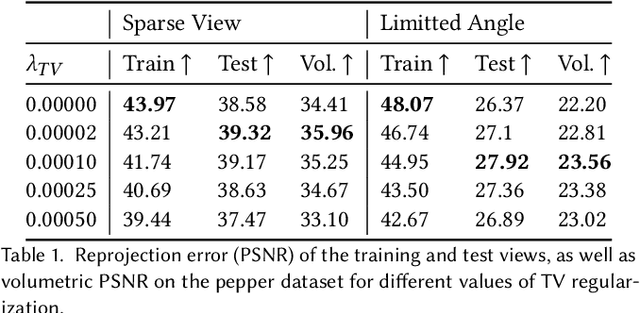

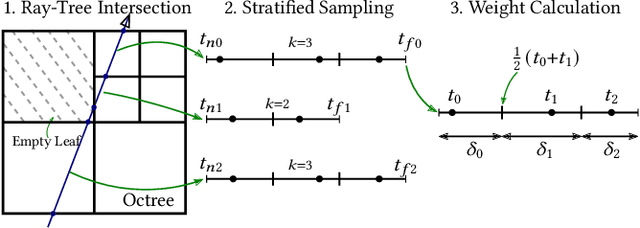
In this paper, we present Neural Adaptive Tomography (NeAT), the first adaptive, hierarchical neural rendering pipeline for multi-view inverse rendering. Through a combination of neural features with an adaptive explicit representation, we achieve reconstruction times far superior to existing neural inverse rendering methods. The adaptive explicit representation improves efficiency by facilitating empty space culling and concentrating samples in complex regions, while the neural features act as a neural regularizer for the 3D reconstruction. The NeAT framework is designed specifically for the tomographic setting, which consists only of semi-transparent volumetric scenes instead of opaque objects. In this setting, NeAT outperforms the quality of existing optimization-based tomography solvers while being substantially faster.