 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
Jan 11, 2024Point-based radiance field rendering has demonstrated impressive results for novel view synthesis, offering a compelling blend of rendering quality and computational efficiency. However, also latest approaches in this domain are not without their shortcomings. 3D Gaussian Splatting [Kerbl and Kopanas et al. 2023] struggles when tasked with rendering highly detailed scenes, due to blurring and cloudy artifacts. On the other hand, ADOP [R\"uckert et al. 2022] can accommodate crisper images, but the neural reconstruction network decreases performance, it grapples with temporal instability and it is unable to effectively address large gaps in the point cloud. In this paper, we present TRIPS (Trilinear Point Splatting), an approach that combines ideas from both Gaussian Splatting and ADOP. The fundamental concept behind our novel technique involves rasterizing points into a screen-space image pyramid, with the selection of the pyramid layer determined by the projected point size. This approach allows rendering arbitrarily large points using a single trilinear write. A lightweight neural network is then used to reconstruct a hole-free image including detail beyond splat resolution. Importantly, our render pipeline is entirely differentiable, allowing for automatic optimization of both point sizes and positions. Our evaluation demonstrate that TRIPS surpasses existing state-of-the-art methods in terms of rendering quality while maintaining a real-time frame rate of 60 frames per second on readily available hardware. This performance extends to challenging scenarios, such as scenes featuring intricate geometry, expansive landscapes, and auto-exposed footage.
LiveNVS: Neural View Synthesis on Live RGB-D Streams
Nov 29, 2023



Existing real-time RGB-D reconstruction approaches, like Kinect Fusion, lack real-time photo-realistic visualization. This is due to noisy, oversmoothed or incomplete geometry and blurry textures which are fused from imperfect depth maps and camera poses. Recent neural rendering methods can overcome many of such artifacts but are mostly optimized for offline usage, hindering the integration into a live reconstruction pipeline. In this paper, we present LiveNVS, a system that allows for neural novel view synthesis on a live RGB-D input stream with very low latency and real-time rendering. Based on the RGB-D input stream, novel views are rendered by projecting neural features into the target view via a densely fused depth map and aggregating the features in image-space to a target feature map. A generalizable neural network then translates the target feature map into a high-quality RGB image. LiveNVS achieves state-of-the-art neural rendering quality of unknown scenes during capturing, allowing users to virtually explore the scene and assess reconstruction quality in real-time.
VET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Nov 08, 2023

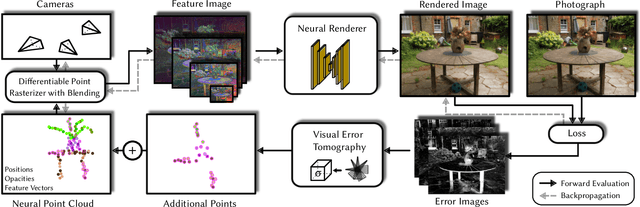

In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.
Neural Adaptive SCEne Tracing
Mar 16, 2022
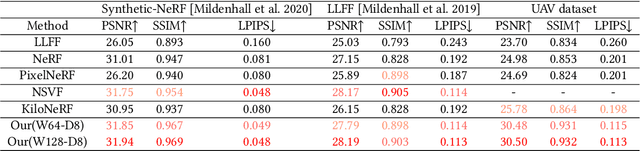
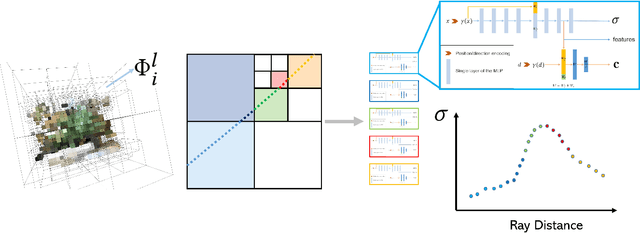
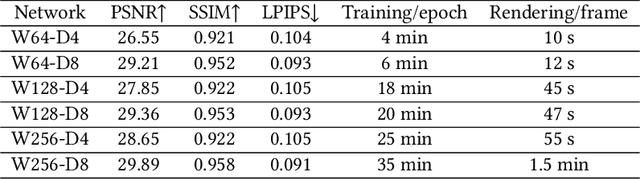
Neural rendering with implicit neural networks has recently emerged as an attractive proposition for scene reconstruction, achieving excellent quality albeit at high computational cost. While the most recent generation of such methods has made progress on the rendering (inference) times, very little progress has been made on improving the reconstruction (training) times. In this work, we present Neural Adaptive Scene Tracing (NAScenT), the first neural rendering method based on directly training a hybrid explicit-implicit neural representation. NAScenT uses a hierarchical octree representation with one neural network per leaf node and combines this representation with a two-stage sampling process that concentrates ray samples where they matter most near object surfaces. As a result, NAScenT is capable of reconstructing challenging scenes including both large, sparsely populated volumes like UAV captured outdoor environments, as well as small scenes with high geometric complexity. NAScenT outperforms existing neural rendering approaches in terms of both quality and training time.
NeAT: Neural Adaptive Tomography
Feb 04, 2022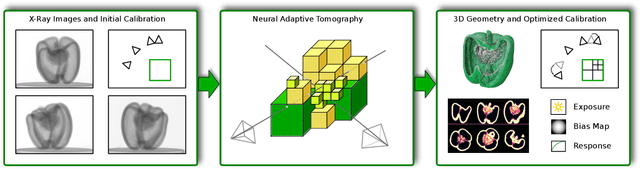
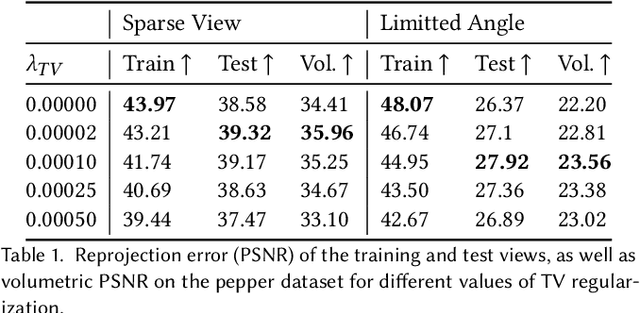

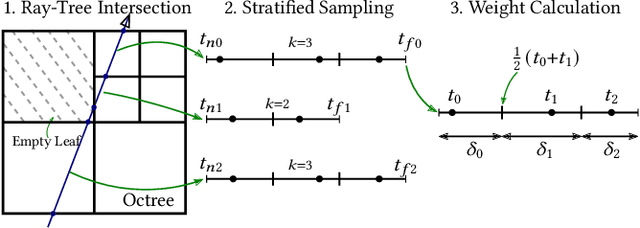
In this paper, we present Neural Adaptive Tomography (NeAT), the first adaptive, hierarchical neural rendering pipeline for multi-view inverse rendering. Through a combination of neural features with an adaptive explicit representation, we achieve reconstruction times far superior to existing neural inverse rendering methods. The adaptive explicit representation improves efficiency by facilitating empty space culling and concentrating samples in complex regions, while the neural features act as a neural regularizer for the 3D reconstruction. The NeAT framework is designed specifically for the tomographic setting, which consists only of semi-transparent volumetric scenes instead of opaque objects. In this setting, NeAT outperforms the quality of existing optimization-based tomography solvers while being substantially faster.
ADOP: Approximate Differentiable One-Pixel Point Rendering
Oct 15, 2021



We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene's parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.