 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Paper and Code


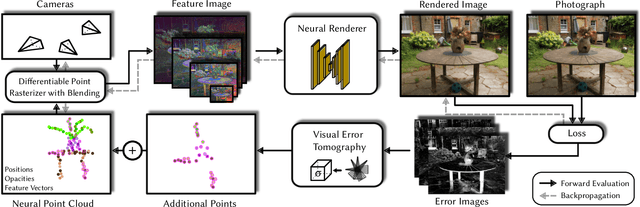

In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.