 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabH2O: A Unified Foundation Model for Tabular Prediction
May 18, 2026We present TabH2O, a foundation model for tabular data that performs classification and regression in a single forward pass via in-context learning. TabH2O builds on the TabICL architecture with several key modifications: (1) unified training, a single model handles both classification and regression via a dual-head architecture, eliminating the need for separate models and reducing total pretraining cost; (2) single-stage pretraining, training stability improvements (bounded scalable softmax, inter-stage normalization, learnable residual scaling, logit soft-capping) eliminate the need for multi-stage curriculum learning, enabling training with full-length sequences from the start; and (3) noise-aware pretraining, synthetic datasets include explicit noise dimensions to teach the model robustness to irrelevant features. We evaluate TabH2O v1 (29.2M parameters) on the TALENT benchmark (300 datasets), where it achieves an average rank of 2.55 out of 6 evaluated methods, outperforming tuned CatBoost (4.07), H2O AutoML (4.18), and LightGBM (5.08), competitive with TabPFN v2.6 (2.74), and behind TabICL v2 (2.12), while placing in the top-3 on 81% of the testing datasets across classification and regression tasks.
Fus3D: Decoding Consolidated 3D Geometry from Feed-forward Geometry Transformer Latents
Mar 26, 2026We propose a feed-forward method for dense Signed Distance Field (SDF) regression from unstructured image collections in less than three seconds, without camera calibration or post-hoc fusion. Our key insight is that the intermediate feature space of pretrained multi-view feed-forward geometry transformers already encodes a powerful joint world representation; yet, existing pipelines discard it, routing features through per-view prediction heads before assembling 3D geometry post-hoc, which discards valuable completeness information and accumulates inaccuracies. We instead perform 3D extraction directly from geometry transformer features via learned volumetric extraction: voxelized canonical embeddings that progressively absorb multi-view geometry information through interleaved cross- and self-attention into a structured volumetric latent grid. A simple convolutional decoder then maps this grid to a dense SDF. We additionally propose a scalable, validity-aware supervision scheme directly using SDFs derived from depth maps or 3D assets, tackling practical issues like non-watertight meshes. Our approach yields complete and well-defined distance values across sparse- and dense-view settings and demonstrates geometrically plausible completions. Code and further material can be found at https://lorafib.github.io/fus3d.
VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points
Oct 23, 2024



Recent advances in novel view synthesis (NVS), particularly neural radiance fields (NeRF) and Gaussian splatting (3DGS), have demonstrated impressive results in photorealistic scene rendering. These techniques hold great potential for applications in virtual tourism and teleportation, where immersive realism is crucial. However, the high-performance demands of virtual reality (VR) systems present challenges in directly utilizing even such fast-to-render scene representations like 3DGS due to latency and computational constraints. In this paper, we propose foveated rendering as a promising solution to these obstacles. We analyze state-of-the-art NVS methods with respect to their rendering performance and compatibility with the human visual system. Our approach introduces a novel foveated rendering approach for Virtual Reality, that leverages the sharp, detailed output of neural point rendering for the foveal region, fused with a smooth rendering of 3DGS for the peripheral vision. Our evaluation confirms that perceived sharpness and detail-richness are increased by our approach compared to a standard VR-ready 3DGS configuration. Our system meets the necessary performance requirements for real-time VR interactions, ultimately enhancing the user's immersive experience. Project page: https://lfranke.github.io/vr_splatting
Refinement of Monocular Depth Maps via Multi-View Differentiable Rendering
Oct 04, 2024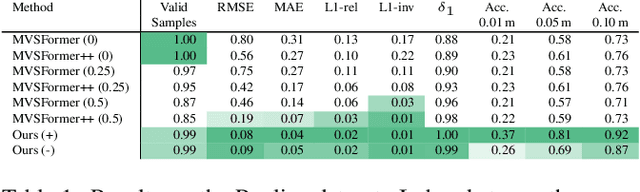
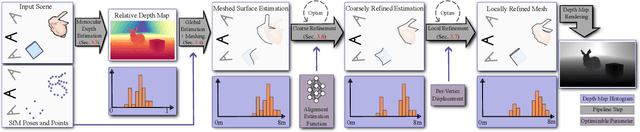
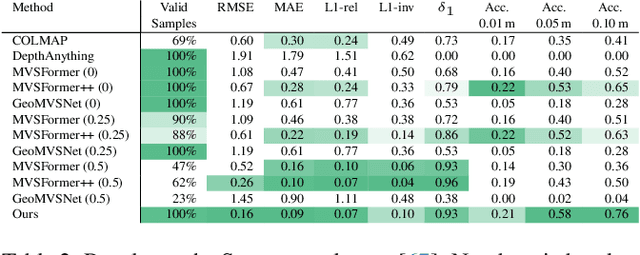

The accurate reconstruction of per-pixel depth for an image is vital for many tasks in computer graphics, computer vision, and robotics. In this paper, we present a novel approach to generate view consistent and detailed depth maps from a number of posed images. We leverage advances in monocular depth estimation, which generate topologically complete, but metrically inaccurate depth maps and refine them in a two-stage optimization process based on a differentiable renderer. Taking the monocular depth map as input, we first scale this map to absolute distances based on structure-from-motion and transform the depths to a triangle surface mesh. We then refine this depth mesh in a local optimization, enforcing photometric and geometric consistency. Our evaluation shows that our method is able to generate dense, detailed, high-quality depth maps, also in challenging indoor scenarios, and outperforms state-of-the-art depth reconstruction approaches. Overview and supplemental material of this project can be found at https://lorafib.github.io/ref_depth/.
TRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
Jan 11, 2024Point-based radiance field rendering has demonstrated impressive results for novel view synthesis, offering a compelling blend of rendering quality and computational efficiency. However, also latest approaches in this domain are not without their shortcomings. 3D Gaussian Splatting [Kerbl and Kopanas et al. 2023] struggles when tasked with rendering highly detailed scenes, due to blurring and cloudy artifacts. On the other hand, ADOP [R\"uckert et al. 2022] can accommodate crisper images, but the neural reconstruction network decreases performance, it grapples with temporal instability and it is unable to effectively address large gaps in the point cloud. In this paper, we present TRIPS (Trilinear Point Splatting), an approach that combines ideas from both Gaussian Splatting and ADOP. The fundamental concept behind our novel technique involves rasterizing points into a screen-space image pyramid, with the selection of the pyramid layer determined by the projected point size. This approach allows rendering arbitrarily large points using a single trilinear write. A lightweight neural network is then used to reconstruct a hole-free image including detail beyond splat resolution. Importantly, our render pipeline is entirely differentiable, allowing for automatic optimization of both point sizes and positions. Our evaluation demonstrate that TRIPS surpasses existing state-of-the-art methods in terms of rendering quality while maintaining a real-time frame rate of 60 frames per second on readily available hardware. This performance extends to challenging scenarios, such as scenes featuring intricate geometry, expansive landscapes, and auto-exposed footage.
LiveNVS: Neural View Synthesis on Live RGB-D Streams
Nov 29, 2023



Existing real-time RGB-D reconstruction approaches, like Kinect Fusion, lack real-time photo-realistic visualization. This is due to noisy, oversmoothed or incomplete geometry and blurry textures which are fused from imperfect depth maps and camera poses. Recent neural rendering methods can overcome many of such artifacts but are mostly optimized for offline usage, hindering the integration into a live reconstruction pipeline. In this paper, we present LiveNVS, a system that allows for neural novel view synthesis on a live RGB-D input stream with very low latency and real-time rendering. Based on the RGB-D input stream, novel views are rendered by projecting neural features into the target view via a densely fused depth map and aggregating the features in image-space to a target feature map. A generalizable neural network then translates the target feature map into a high-quality RGB image. LiveNVS achieves state-of-the-art neural rendering quality of unknown scenes during capturing, allowing users to virtually explore the scene and assess reconstruction quality in real-time.
VET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Nov 08, 2023

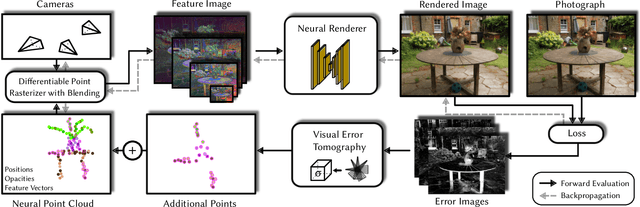

In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.
LumiPath - Towards Real-time Physically-based Rendering on Embedded Devices
Mar 09, 2019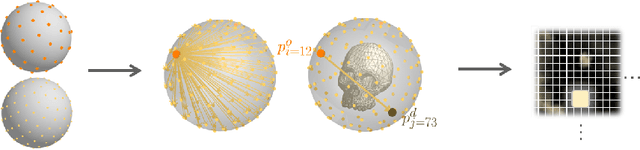
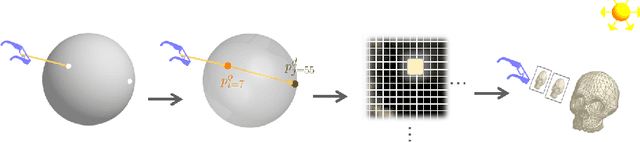
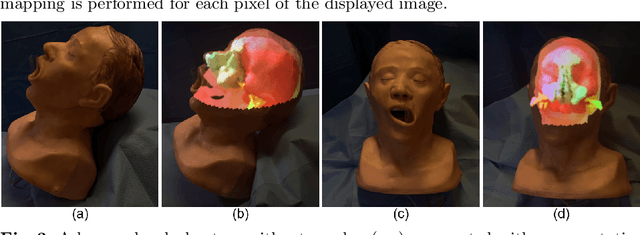
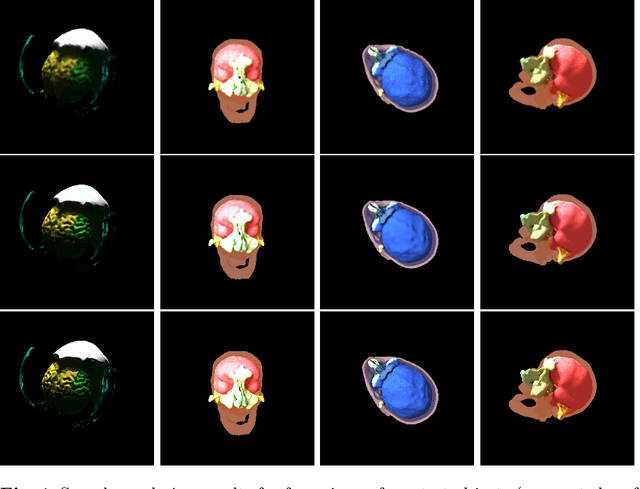
As the computational power of toady's devices increases, real-time physically-based rendering becomes possible, and is rapidly gaining attention across a variety of domains. These include gaming, where physically-based rendering enhances immersion and overall entertainment experience, all the way to medicine, where it constitutes a powerful tool for intuitive volumetric data visualization. However, leveraging the obvious benefits of physically-based rendering (also referred to as photo-realistic rendering) remains challenging on embedded devices such as optical see-through head-mounted displays because of their limited computational power, and restricted memory usage and power consumption. We propose methods that aim at overcoming these limitations, fueling the implementation of real-time physically-based rendering on embedded devices. We navigate the compromise between memory requirement, computational power, and image quality to achieve reasonable rendering results by introducing a flexible representation of plenoptic functions and adapting a fast approximation algorithm for image generation from our plenoptic functions. We conclude by discussing potential applications and limitations of the proposed method.