 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end differentiable design of geometric waveguide displays
Jan 07, 2026Geometric waveguides are a promising architecture for optical see-through augmented reality displays, but their performance is severely bottlenecked by the difficulty of jointly optimizing non-sequential light transport and polarization-dependent multilayer thin-film coatings. Here we present the first end-to-end differentiable optimization framework for geometric waveguide that couples non-sequential Monte Carlo polarization ray tracing with a differentiable transfer-matrix thin-film solver. A differentiable Monte Carlo ray tracer avoids the exponential growth of deterministic ray splitting while enabling gradients backpropagation from eyebox metrics to design parameters. With memory-saving strategies, we optimize more than one thousand layer-thickness parameters and billions of non-sequential ray-surface intersections on a single multi-GPU workstation. Automated layer pruning is achieved by starting from over-parameterized stacks and driving redundant layers to zero thickness under discrete manufacturability constraints, effectively performing topology optimization to discover optimal coating structures. On a representative design, starting from random initialization within thickness bounds, our method increases light efficiency from 4.1\% to 33.5\% and improves eyebox and FoV uniformity by $\sim$17$\times$ and $\sim$11$\times$, respectively. Furthermore, we jointly optimize the waveguide and an image preprocessing network to improve perceived image quality. Our framework not only enables system-level, high-dimensional coating optimization inside the waveguide, but also expands the scope of differentiable optics for next-generation optical design.
Performance Validation of Coded Wavefront Sensing for Quantitative Phase Imaging of Static and Dynamic Specimens Using Digital Holographic Microscopy
Aug 23, 2025Coded wavefront sensing (Coded-WFS) is a snapshot quantitative phase imaging (QPI) technique that has been shown to successfully leverage the memory effect to retrieve the phase of biological specimens. In this paper, we perform QPI on static silica beads and dynamic HEK cells using Coded-WFS. The accuracy of the retrieved phase map is validated using digital holographic microscopy (DHM) for the same specimens. We report comparisons of simultaneous bright-field intensity and optical path delay.
Learned Off-aperture Encoding for Wide Field-of-view RGBD Imaging
Jul 30, 2025End-to-end (E2E) designed imaging systems integrate coded optical designs with decoding algorithms to enhance imaging fidelity for diverse visual tasks. However, existing E2E designs encounter significant challenges in maintaining high image fidelity at wide fields of view, due to high computational complexity, as well as difficulties in modeling off-axis wave propagation while accounting for off-axis aberrations. In particular, the common approach of placing the encoding element into the aperture or pupil plane results in only a global control of the wavefront. To overcome these limitations, this work explores an additional design choice by positioning a DOE off-aperture, enabling a spatial unmixing of the degrees of freedom and providing local control over the wavefront over the image plane. Our approach further leverages hybrid refractive-diffractive optical systems by linking differentiable ray and wave optics modeling, thereby optimizing depth imaging quality and demonstrating system versatility. Experimental results reveal that the off-aperture DOE enhances the imaging quality by over 5 dB in PSNR at a FoV of approximately $45^\circ$ when paired with a simple thin lens, outperforming traditional on-aperture systems. Furthermore, we successfully recover color and depth information at nearly $28^\circ$ FoV using off-aperture DOE configurations with compound optics. Physical prototypes for both applications validate the effectiveness and versatility of the proposed method.
Large-Area Fabrication-aware Computational Diffractive Optics
May 28, 2025Differentiable optics, as an emerging paradigm that jointly optimizes optics and (optional) image processing algorithms, has made innovative optical designs possible across a broad range of applications. Many of these systems utilize diffractive optical components (DOEs) for holography, PSF engineering, or wavefront shaping. Existing approaches have, however, mostly remained limited to laboratory prototypes, owing to a large quality gap between simulation and manufactured devices. We aim at lifting the fundamental technical barriers to the practical use of learned diffractive optical systems. To this end, we propose a fabrication-aware design pipeline for diffractive optics fabricated by direct-write grayscale lithography followed by nano-imprinting replication, which is directly suited for inexpensive mass production of large area designs. We propose a super-resolved neural lithography model that can accurately predict the 3D geometry generated by the fabrication process. This model can be seamlessly integrated into existing differentiable optics frameworks, enabling fabrication-aware, end-to-end optimization of computational optical systems. To tackle the computational challenges, we also devise tensor-parallel compute framework centered on distributing large-scale FFT computation across many GPUs. As such, we demonstrate large scale diffractive optics designs up to 32.16 mm $\times$ 21.44 mm, simulated on grids of up to 128,640 by 85,760 feature points. We find adequate agreement between simulation and fabricated prototypes for applications such as holography and PSF engineering. We also achieve high image quality from an imaging system comprised only of a single DOE, with images processed only by a Wiener filter utilizing the simulation PSF. We believe our findings lift the fabrication limitations for real-world applications of diffractive optics and differentiable optical design.
Latent Space Imaging
Jul 09, 2024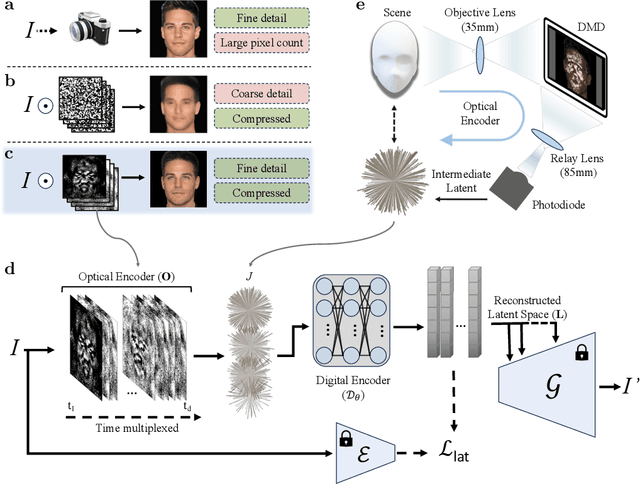


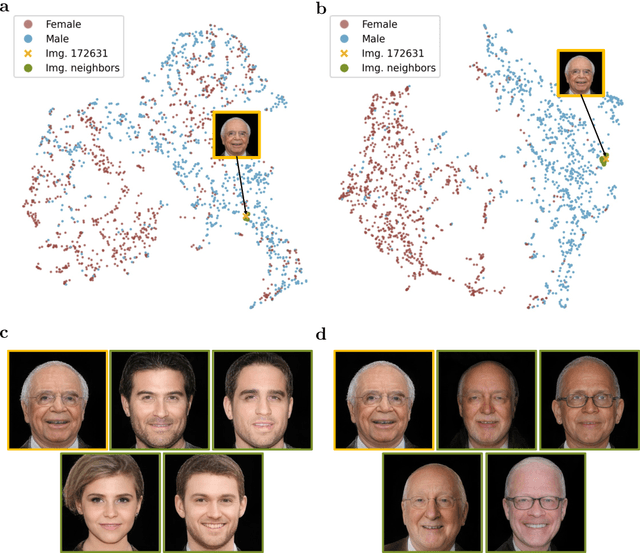
Digital imaging systems have classically been based on brute-force measuring and processing of pixels organized on regular grids. The human visual system, on the other hand, performs a massive data reduction from the number of photo-receptors to the optic nerve, essentially encoding the image information into a low bandwidth latent space representation suitable for processing by the human brain. In this work, we propose to follow a similar approach for the development of artificial vision systems. Latent Space Imaging is a new paradigm that, through a combination of optics and software, directly encodes the image information into the semantically rich latent space of a generative model, thus substantially reducing bandwidth and memory requirements during the capture process. We demonstrate this new principle through an initial hardware prototype based on the single pixel camera. By designing an amplitude modulation scheme that encodes into the latent space of a generative model, we achieve compression ratios from 1:100 to 1:1,000 during the imaging process, illustrating the potential of latent space imaging for highly efficient imaging hardware, to enable future applications in high speed imaging, or task-specific cameras with substantially reduced hardware complexity.
NeST: Neural Stress Tensor Tomography by leveraging 3D Photoelasticity
Jun 14, 2024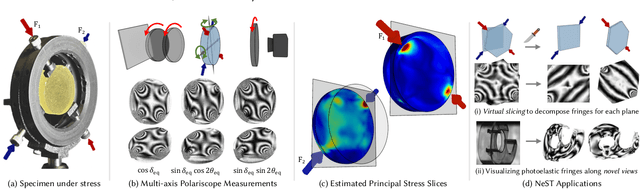

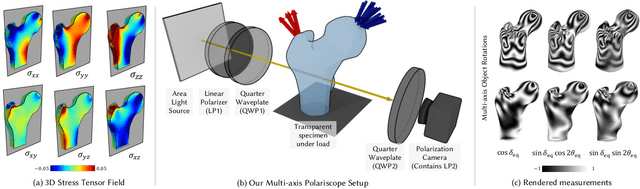
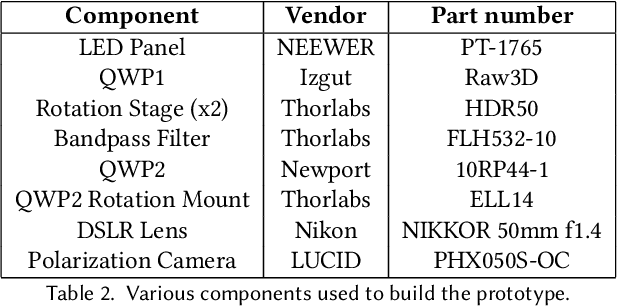
Photoelasticity enables full-field stress analysis in transparent objects through stress-induced birefringence. Existing techniques are limited to 2D slices and require destructively slicing the object. Recovering the internal 3D stress distribution of the entire object is challenging as it involves solving a tensor tomography problem and handling phase wrapping ambiguities. We introduce NeST, an analysis-by-synthesis approach for reconstructing 3D stress tensor fields as neural implicit representations from polarization measurements. Our key insight is to jointly handle phase unwrapping and tensor tomography using a differentiable forward model based on Jones calculus. Our non-linear model faithfully matches real captures, unlike prior linear approximations. We develop an experimental multi-axis polariscope setup to capture 3D photoelasticity and experimentally demonstrate that NeST reconstructs the internal stress distribution for objects with varying shape and force conditions. Additionally, we showcase novel applications in stress analysis, such as visualizing photoelastic fringes by virtually slicing the object and viewing photoelastic fringes from unseen viewpoints. NeST paves the way for scalable non-destructive 3D photoelastic analysis.
HDNet: Physics-Inspired Neural Network for Flow Estimation based on Helmholtz Decomposition
Jun 12, 2024



Flow estimation problems are ubiquitous in scientific imaging. Often, the underlying flows are subject to physical constraints that can be exploited in the flow estimation; for example, incompressible (divergence-free) flows are expected for many fluid experiments, while irrotational (curl-free) flows arise in the analysis of optical distortions and wavefront sensing. In this work, we propose a Physics- Inspired Neural Network (PINN) named HDNet, which performs a Helmholtz decomposition of an arbitrary flow field, i.e., it decomposes the input flow into a divergence-only and a curl-only component. HDNet can be trained exclusively on synthetic data generated by reverse Helmholtz decomposition, which we call Helmholtz synthesis. As a PINN, HDNet is fully differentiable and can easily be integrated into arbitrary flow estimation problems.
End-to-End Hybrid Refractive-Diffractive Lens Design with Differentiable Ray-Wave Model
Jun 02, 2024



Hybrid refractive-diffractive lenses combine the light efficiency of refractive lenses with the information encoding power of diffractive optical elements (DOE), showing great potential as the next generation of imaging systems. However, accurately simulating such hybrid designs is generally difficult, and in particular, there are no existing differentiable image formation models for hybrid lenses with sufficient accuracy. In this work, we propose a new hybrid ray-tracing and wave-propagation (ray-wave) model for accurate simulation of both optical aberrations and diffractive phase modulation, where the DOE is placed between the last refractive surface and the image sensor, i.e. away from the Fourier plane that is often used as a DOE position. The proposed ray-wave model is fully differentiable, enabling gradient back-propagation for end-to-end co-design of refractive-diffractive lens optimization and the image reconstruction network. We validate the accuracy of the proposed model by comparing the simulated point spread functions (PSFs) with theoretical results, as well as simulation experiments that show our model to be more accurate than solutions implemented in commercial software packages like Zemax. We demonstrate the effectiveness of the proposed model through real-world experiments and show significant improvements in both aberration correction and extended depth-of-field (EDoF) imaging. We believe the proposed model will motivate further investigation into a wide range of applications in computational imaging, computational photography, and advanced optical design. Code will be released upon publication.
Limitations of Data-Driven Spectral Reconstruction -- An Optics-Aware Analysis
Jan 08, 2024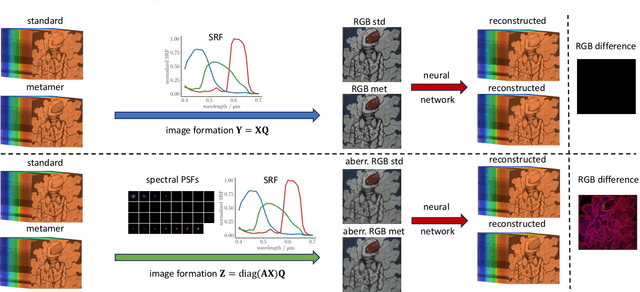

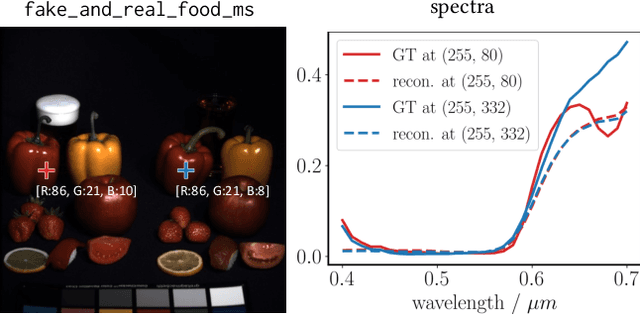
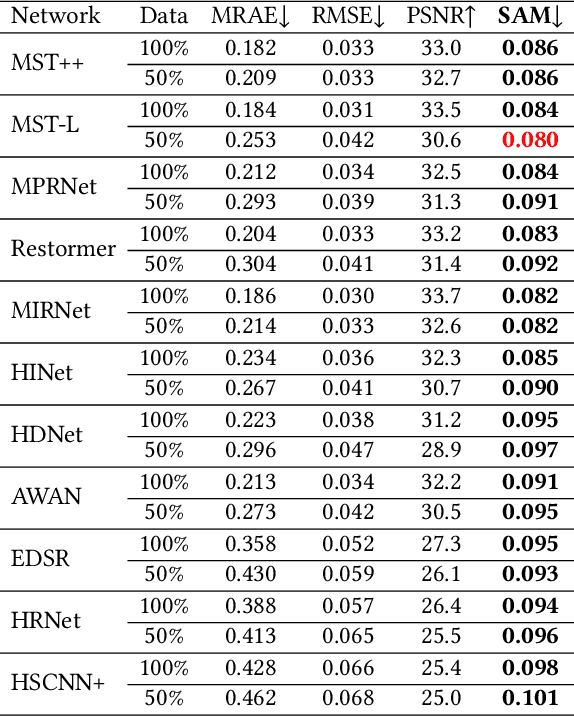
Hyperspectral imaging empowers computer vision systems with the distinct capability of identifying materials through recording their spectral signatures. Recent efforts in data-driven spectral reconstruction aim at extracting spectral information from RGB images captured by cost-effective RGB cameras, instead of dedicated hardware. In this paper we systematically analyze the performance of such methods, evaluating both the practical limitations with respect to current datasets and overfitting, as well as fundamental limits with respect to the nature of the information encoded in the RGB images, and the dependency of this information on the optical system of the camera. We find that the current models are not robust under slight variations, e.g., in noise level or compression of the RGB file. Both the methods and the datasets are also limited in their ability to cope with metameric colors. This issue can in part be overcome with metameric data augmentation. Moreover, optical lens aberrations can help to improve the encoding of the metameric information into the RGB image, which paves the road towards higher performing spectral imaging and reconstruction approaches.
MetaISP -- Exploiting Global Scene Structure for Accurate Multi-Device Color Rendition
Jan 06, 2024



Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. Each smartphone manufacturer has developed its ISPs with its own characteristic heuristics for improving the color rendition, for example, skin tones and other visually essential colors. The recent interest in replacing the historically grown ISP systems with deep-learned pipelines to match DSLR's image quality improves structural features in the image. However, these works ignore the superior color processing based on semantic scene analysis that distinguishes mobile phone ISPs from DSLRs. Here, we present MetaISP, a single model designed to learn how to translate between the color and local contrast characteristics of different devices. MetaISP takes the RAW image from device A as input and translates it to RGB images that inherit the appearance characteristics of devices A, B, and C. We achieve this result by employing a lightweight deep learning technique that conditions its output appearance based on the device of interest. In this approach, we leverage novel attention mechanisms inspired by cross-covariance to learn global scene semantics. Additionally, we use the metadata that typically accompanies RAW images and estimate scene illuminants when they are unavailable.