 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapshot Polarimetric Display Inverse Rendering
May 24, 2026Inverse rendering remains a core challenge in graphics and vision, especially in the snapshot configurations required for lightweight desktop workflows, where the per-frame information budget is highly constrained. Previous inverse rendering work explores various available dimensions for enriching the per-shot information, including temporal modulation, spectral encoding, and polarization. In this work, we introduce polarimetric display inverse rendering, using an LCD to project a linearly polarized RGB binary pattern and an RGB polarization camera augmented with a quarter-wave plate to acquire spectro-polarimetric measurements in a single shot. A feed-forward transformer maps these measurements to per-pixel normal, albedo, roughness, and metallicity. To overcome training data scarcity, we expand a limited set of measured polarimetric bidirectional reflectance distribution functions via a generative manifold. Evaluations on a real desktop setup demonstrate accurate inverse rendering across diverse scenes, outperforming existing approaches.
Latent Space Imaging
Jul 09, 2024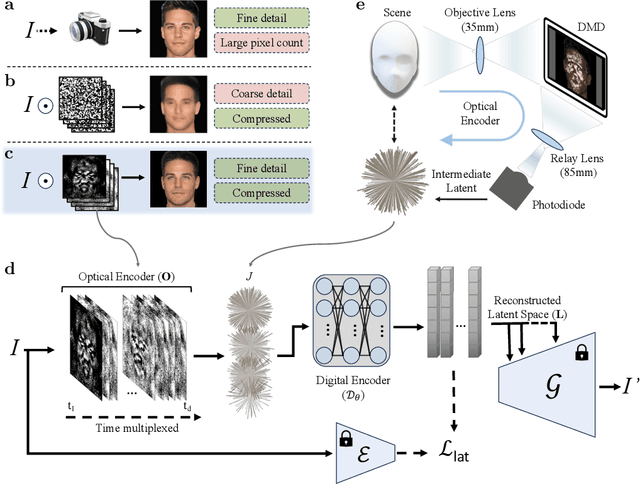


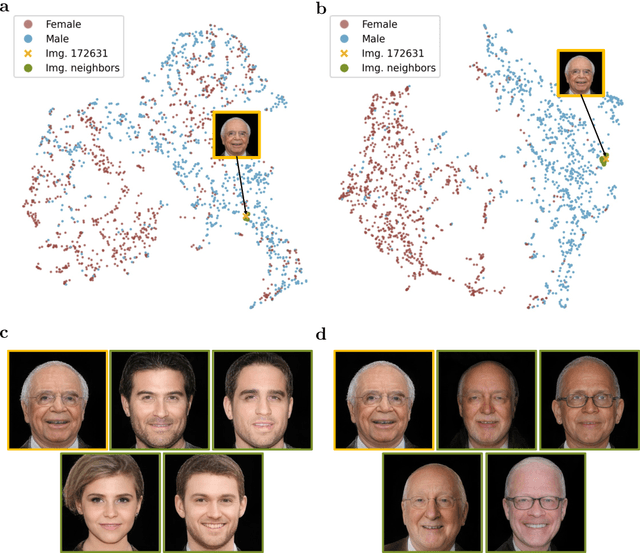
Digital imaging systems have classically been based on brute-force measuring and processing of pixels organized on regular grids. The human visual system, on the other hand, performs a massive data reduction from the number of photo-receptors to the optic nerve, essentially encoding the image information into a low bandwidth latent space representation suitable for processing by the human brain. In this work, we propose to follow a similar approach for the development of artificial vision systems. Latent Space Imaging is a new paradigm that, through a combination of optics and software, directly encodes the image information into the semantically rich latent space of a generative model, thus substantially reducing bandwidth and memory requirements during the capture process. We demonstrate this new principle through an initial hardware prototype based on the single pixel camera. By designing an amplitude modulation scheme that encodes into the latent space of a generative model, we achieve compression ratios from 1:100 to 1:1,000 during the imaging process, illustrating the potential of latent space imaging for highly efficient imaging hardware, to enable future applications in high speed imaging, or task-specific cameras with substantially reduced hardware complexity.
Learning Photometric Feature Transform for Free-form Object Scan
Aug 07, 2023



We propose a novel framework to automatically learn to aggregate and transform photometric measurements from multiple unstructured views into spatially distinctive and view-invariant low-level features, which are fed to a multi-view stereo method to enhance 3D reconstruction. The illumination conditions during acquisition and the feature transform are jointly trained on a large amount of synthetic data. We further build a system to reconstruct the geometry and anisotropic reflectance of a variety of challenging objects from hand-held scans. The effectiveness of the system is demonstrated with a lightweight prototype, consisting of a camera and an array of LEDs, as well as an off-the-shelf tablet. Our results are validated against reconstructions from a professional 3D scanner and photographs, and compare favorably with state-of-the-art techniques.
DiFT: Differentiable Differential Feature Transform for Multi-View Stereo
Mar 16, 2022
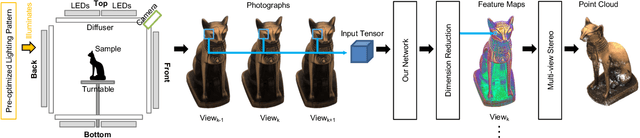
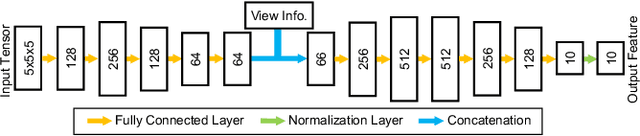

We present a novel framework to automatically learn to transform the differential cues from a stack of images densely captured with a rotational motion into spatially discriminative and view-invariant per-pixel features at each view. These low-level features can be directly fed to any existing multi-view stereo technique for enhanced 3D reconstruction. The lighting condition during acquisition can also be jointly optimized in a differentiable fashion. We sample from a dozen of pre-scanned objects with a wide variety of geometry and reflectance to synthesize a large amount of high-quality training data. The effectiveness of our features is demonstrated on a number of challenging objects acquired with a lightstage, comparing favorably with state-of-the-art techniques. Finally, we explore additional applications of geometric detail visualization and computational stylization of complex appearance.
Learning Efficient Photometric Feature Transform for Multi-view Stereo
Mar 27, 2021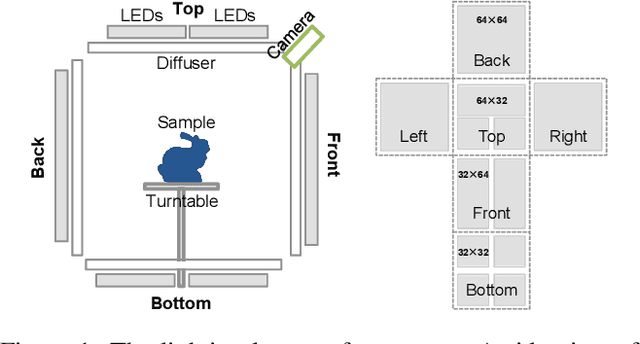

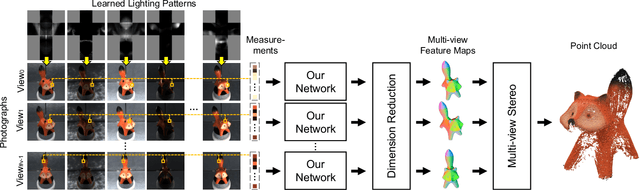
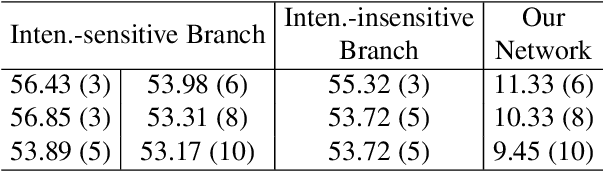
We present a novel framework to learn to convert the perpixel photometric information at each view into spatially distinctive and view-invariant low-level features, which can be plugged into existing multi-view stereo pipeline for enhanced 3D reconstruction. Both the illumination conditions during acquisition and the subsequent per-pixel feature transform can be jointly optimized in a differentiable fashion. Our framework automatically adapts to and makes efficient use of the geometric information available in different forms of input data. High-quality 3D reconstructions of a variety of challenging objects are demonstrated on the data captured with an illumination multiplexing device, as well as a point light. Our results compare favorably with state-of-the-art techniques.