 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination
May 28, 2025We present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning. Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels. RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. We demonstrate and evaluate RenderFormer on scenes with varying complexity in shape and light transport.
* Accepted to SIGGRAPH 2025. Project page: https://microsoft.github.io/renderformer
MaterialPicker: Multi-Modal Material Generation with Diffusion Transformers
Dec 04, 2024



High-quality material generation is key for virtual environment authoring and inverse rendering. We propose MaterialPicker, a multi-modal material generator leveraging a Diffusion Transformer (DiT) architecture, improving and simplifying the creation of high-quality materials from text prompts and/or photographs. Our method can generate a material based on an image crop of a material sample, even if the captured surface is distorted, viewed at an angle or partially occluded, as is often the case in photographs of natural scenes. We further allow the user to specify a text prompt to provide additional guidance for the generation. We finetune a pre-trained DiT-based video generator into a material generator, where each material map is treated as a frame in a video sequence. We evaluate our approach both quantitatively and qualitatively and show that it enables more diverse material generation and better distortion correction than previous work.
ARM: Appearance Reconstruction Model for Relightable 3D Generation
Nov 16, 2024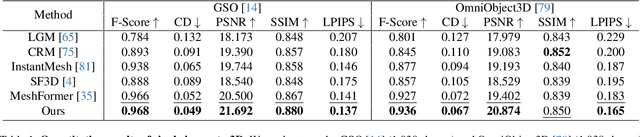
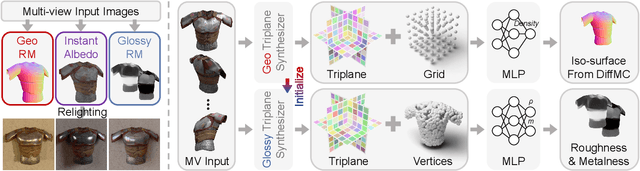
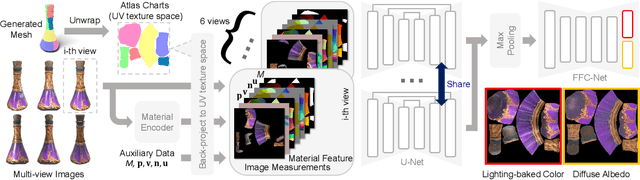
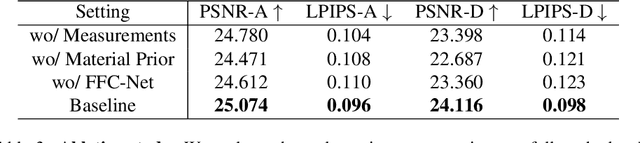
Recent image-to-3D reconstruction models have greatly advanced geometry generation, but they still struggle to faithfully generate realistic appearance. To address this, we introduce ARM, a novel method that reconstructs high-quality 3D meshes and realistic appearance from sparse-view images. The core of ARM lies in decoupling geometry from appearance, processing appearance within the UV texture space. Unlike previous methods, ARM improves texture quality by explicitly back-projecting measurements onto the texture map and processing them in a UV space module with a global receptive field. To resolve ambiguities between material and illumination in input images, ARM introduces a material prior that encodes semantic appearance information, enhancing the robustness of appearance decomposition. Trained on just 8 H100 GPUs, ARM outperforms existing methods both quantitatively and qualitatively.
GS^3: Efficient Relighting with Triple Gaussian Splatting
Oct 15, 2024
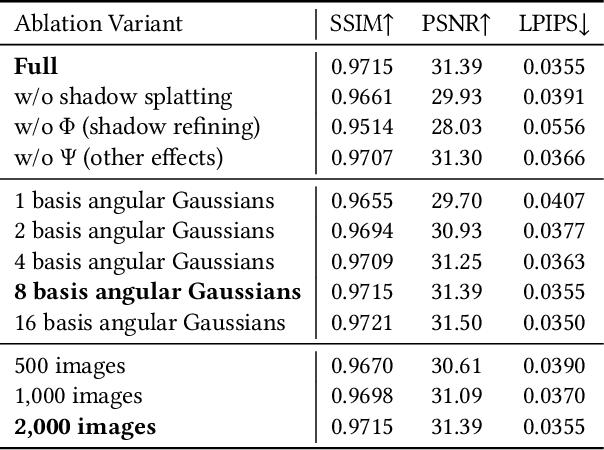

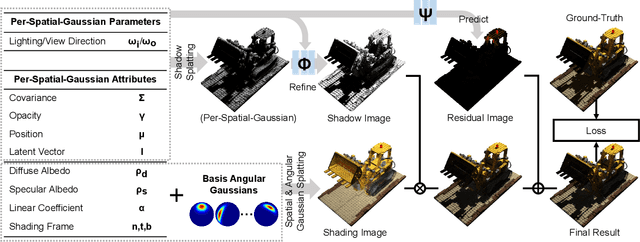
We present a spatial and angular Gaussian based representation and a triple splatting process, for real-time, high-quality novel lighting-and-view synthesis from multi-view point-lit input images. To describe complex appearance, we employ a Lambertian plus a mixture of angular Gaussians as an effective reflectance function for each spatial Gaussian. To generate self-shadow, we splat all spatial Gaussians towards the light source to obtain shadow values, which are further refined by a small multi-layer perceptron. To compensate for other effects like global illumination, another network is trained to compute and add a per-spatial-Gaussian RGB tuple. The effectiveness of our representation is demonstrated on 30 samples with a wide variation in geometry (from solid to fluffy) and appearance (from translucent to anisotropic), as well as using different forms of input data, including rendered images of synthetic/reconstructed objects, photographs captured with a handheld camera and a flash, or from a professional lightstage. We achieve a training time of 40-70 minutes and a rendering speed of 90 fps on a single commodity GPU. Our results compare favorably with state-of-the-art techniques in terms of quality/performance. Our code and data are publicly available at https://GSrelight.github.io/.
* Accepted to SIGGRAPH Asia 2024. Project page: https://gsrelight.github.io/
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024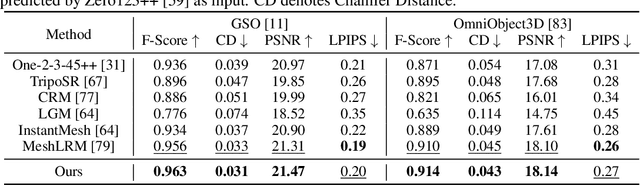
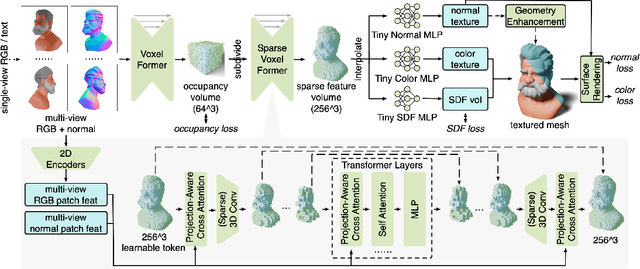


Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
ElastoGen: 4D Generative Elastodynamics
May 23, 2024We present ElastoGen, a knowledge-driven model that generates physically accurate and coherent 4D elastodynamics. Instead of relying on petabyte-scale data-driven learning, ElastoGen leverages the principles of physics-in-the-loop and learns from established physical knowledge, such as partial differential equations and their numerical solutions. The core idea of ElastoGen is converting the global differential operator, corresponding to the nonlinear elastodynamic equations, into iterative local convolution-like operations, which naturally fit modern neural networks. Each network module is specifically designed to support this goal rather than functioning as a black box. As a result, ElastoGen is exceptionally lightweight in terms of both training requirements and network scale. Additionally, due to its alignment with physical procedures, ElastoGen efficiently generates accurate dynamics for a wide range of hyperelastic materials and can be easily integrated with upstream and downstream deep modules to enable end-to-end 4D generation.
DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation
Feb 19, 2024



This paper presents a novel method for exerting fine-grained lighting control during text-driven diffusion-based image generation. While existing diffusion models already have the ability to generate images under any lighting condition, without additional guidance these models tend to correlate image content and lighting. Moreover, text prompts lack the necessary expressional power to describe detailed lighting setups. To provide the content creator with fine-grained control over the lighting during image generation, we augment the text-prompt with detailed lighting information in the form of radiance hints, i.e., visualizations of the scene geometry with a homogeneous canonical material under the target lighting. However, the scene geometry needed to produce the radiance hints is unknown. Our key observation is that we only need to guide the diffusion process, hence exact radiance hints are not necessary; we only need to point the diffusion model in the right direction. Based on this observation, we introduce a three stage method for controlling the lighting during image generation. In the first stage, we leverage a standard pretrained diffusion model to generate a provisional image under uncontrolled lighting. Next, in the second stage, we resynthesize and refine the foreground object in the generated image by passing the target lighting to a refined diffusion model, named DiLightNet, using radiance hints computed on a coarse shape of the foreground object inferred from the provisional image. To retain the texture details, we multiply the radiance hints with a neural encoding of the provisional synthesized image before passing it to DiLightNet. Finally, in the third stage, we resynthesize the background to be consistent with the lighting on the foreground object. We demonstrate and validate our lighting controlled diffusion model on a variety of text prompts and lighting conditions.
Gaussian Splashing: Dynamic Fluid Synthesis with Gaussian Splatting
Jan 27, 2024

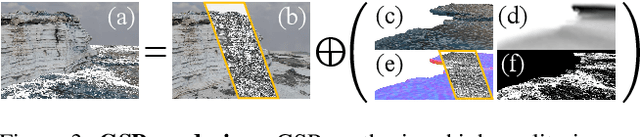
We demonstrate the feasibility of integrating physics-based animations of solids and fluids with 3D Gaussian Splatting (3DGS) to create novel effects in virtual scenes reconstructed using 3DGS. Leveraging the coherence of the Gaussian splatting and position-based dynamics (PBD) in the underlying representation, we manage rendering, view synthesis, and the dynamics of solids and fluids in a cohesive manner. Similar to Gaussian shader, we enhance each Gaussian kernel with an added normal, aligning the kernel's orientation with the surface normal to refine the PBD simulation. This approach effectively eliminates spiky noises that arise from rotational deformation in solids. It also allows us to integrate physically based rendering to augment the dynamic surface reflections on fluids. Consequently, our framework is capable of realistically reproducing surface highlights on dynamic fluids and facilitating interactions between scene objects and fluids from new views. For more information, please visit our project page at \url{https://amysteriouscat.github.io/GaussianSplashing/}.
A Real-time Method for Inserting Virtual Objects into Neural Radiance Fields
Oct 09, 2023



We present the first real-time method for inserting a rigid virtual object into a neural radiance field, which produces realistic lighting and shadowing effects, as well as allows interactive manipulation of the object. By exploiting the rich information about lighting and geometry in a NeRF, our method overcomes several challenges of object insertion in augmented reality. For lighting estimation, we produce accurate, robust and 3D spatially-varying incident lighting that combines the near-field lighting from NeRF and an environment lighting to account for sources not covered by the NeRF. For occlusion, we blend the rendered virtual object with the background scene using an opacity map integrated from the NeRF. For shadows, with a precomputed field of spherical signed distance field, we query the visibility term for any point around the virtual object, and cast soft, detailed shadows onto 3D surfaces. Compared with state-of-the-art techniques, our approach can insert virtual object into scenes with superior fidelity, and has a great potential to be further applied to augmented reality systems.
Relighting Neural Radiance Fields with Shadow and Highlight Hints
Aug 25, 2023



This paper presents a novel neural implicit radiance representation for free viewpoint relighting from a small set of unstructured photographs of an object lit by a moving point light source different from the view position. We express the shape as a signed distance function modeled by a multi layer perceptron. In contrast to prior relightable implicit neural representations, we do not disentangle the different reflectance components, but model both the local and global reflectance at each point by a second multi layer perceptron that, in addition, to density features, the current position, the normal (from the signed distace function), view direction, and light position, also takes shadow and highlight hints to aid the network in modeling the corresponding high frequency light transport effects. These hints are provided as a suggestion, and we leave it up to the network to decide how to incorporate these in the final relit result. We demonstrate and validate our neural implicit representation on synthetic and real scenes exhibiting a wide variety of shapes, material properties, and global illumination light transport.
* Accepted to SIGGRAPH 2023. Author's version. Project page: https://nrhints.github.io/