 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldString: Actionable World Representation
May 20, 2026Inspired by the emergent behaviors in large language models that generalized human intelligence, the research community is pursuing similar emergent capabilities within world models, with a emphasis on modeling the physical world. Within the scope of physical world model, objects are the fundamental primitives that constitute physical reality. From humans to computers, nearly everything we interact with is an object. These objects are rarely static; they are actionable entities with varying states determined by their intrinsic properties. While current methods approach object action states either via video generation or dynamic scene reconstruction, none explicitly model this basic element in a unified, principled way to build an actionable object representation. We propose WorldString, a neural architecture capable of modeling the state manifold of real-world objects by learning directly from point clouds or RGB-D video streams. Serving as a versatile digital twin, it acts as a foundational building block for physical world models; thus, we name it WorldString. Sweetly, its fully differentiable structure seamlessly enables future integration with policy learning and neural dynamics.
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Nov 19, 2025Egocentric videos are a valuable and scalable data source to learn manipulation policies. However, due to significant data heterogeneity, most existing approaches utilize human data for simple pre-training, which does not unlock its full potential. This paper first provides a scalable recipe for collecting and using egocentric data by categorizing human data into two categories: in-the-wild and on-task alongside with systematic analysis on how to use the data. We first curate a dataset, PHSD, which contains over 1,000 hours of diverse in-the-wild egocentric data and over 20 hours of on-task data directly aligned to the target manipulation tasks. This enables learning a large egocentric language-conditioned flow matching policy, Human0. With domain adaptation techniques, Human0 minimizes the gap between humans and humanoids. Empirically, we show Human0 achieves several novel properties from scaling human data, including language following of instructions from only human data, few-shot learning, and improved robustness using on-task data. Project website: https://xiongyicai.github.io/In-N-On/
FreeArt3D: Training-Free Articulated Object Generation using 3D Diffusion
Oct 29, 2025Articulated 3D objects are central to many applications in robotics, AR/VR, and animation. Recent approaches to modeling such objects either rely on optimization-based reconstruction pipelines that require dense-view supervision or on feed-forward generative models that produce coarse geometric approximations and often overlook surface texture. In contrast, open-world 3D generation of static objects has achieved remarkable success, especially with the advent of native 3D diffusion models such as Trellis. However, extending these methods to articulated objects by training native 3D diffusion models poses significant challenges. In this work, we present FreeArt3D, a training-free framework for articulated 3D object generation. Instead of training a new model on limited articulated data, FreeArt3D repurposes a pre-trained static 3D diffusion model (e.g., Trellis) as a powerful shape prior. It extends Score Distillation Sampling (SDS) into the 3D-to-4D domain by treating articulation as an additional generative dimension. Given a few images captured in different articulation states, FreeArt3D jointly optimizes the object's geometry, texture, and articulation parameters without requiring task-specific training or access to large-scale articulated datasets. Our method generates high-fidelity geometry and textures, accurately predicts underlying kinematic structures, and generalizes well across diverse object categories. Despite following a per-instance optimization paradigm, FreeArt3D completes in minutes and significantly outperforms prior state-of-the-art approaches in both quality and versatility.
RigAnything: Template-Free Autoregressive Rigging for Diverse 3D Assets
Feb 13, 2025


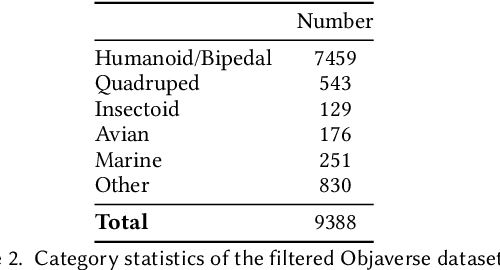
We present RigAnything, a novel autoregressive transformer-based model, which makes 3D assets rig-ready by probabilistically generating joints, skeleton topologies, and assigning skinning weights in a template-free manner. Unlike most existing auto-rigging methods, which rely on predefined skeleton template and are limited to specific categories like humanoid, RigAnything approaches the rigging problem in an autoregressive manner, iteratively predicting the next joint based on the global input shape and the previous prediction. While autoregressive models are typically used to generate sequential data, RigAnything extends their application to effectively learn and represent skeletons, which are inherently tree structures. To achieve this, we organize the joints in a breadth-first search (BFS) order, enabling the skeleton to be defined as a sequence of 3D locations and the parent index. Furthermore, our model improves the accuracy of position prediction by leveraging diffusion modeling, ensuring precise and consistent placement of joints within the hierarchy. This formulation allows the autoregressive model to efficiently capture both spatial and hierarchical relationships within the skeleton. Trained end-to-end on both RigNet and Objaverse datasets, RigAnything demonstrates state-of-the-art performance across diverse object types, including humanoids, quadrupeds, marine creatures, insects, and many more, surpassing prior methods in quality, robustness, generalizability, and efficiency. Please check our website for more details: https://www.liuisabella.com/RigAnything.
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024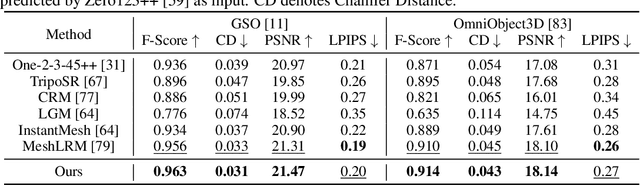
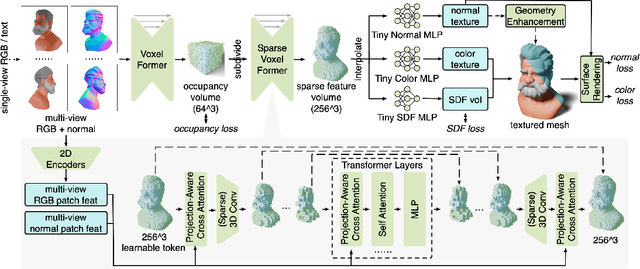


Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Monocular Videos
Apr 18, 2024



Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of structure and detail from monocular visual observations. The problem becomes even more challenging for dynamic scenes and objects. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh given a single monocular video. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from a video. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines.
Robo360: A 3D Omnispective Multi-Material Robotic Manipulation Dataset
Dec 09, 2023
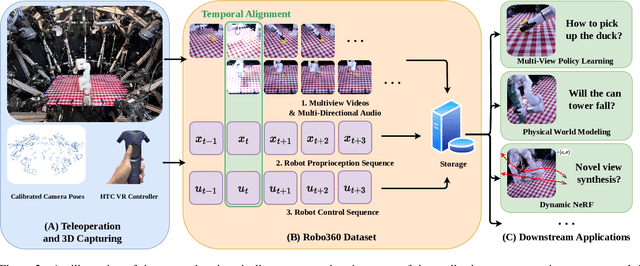
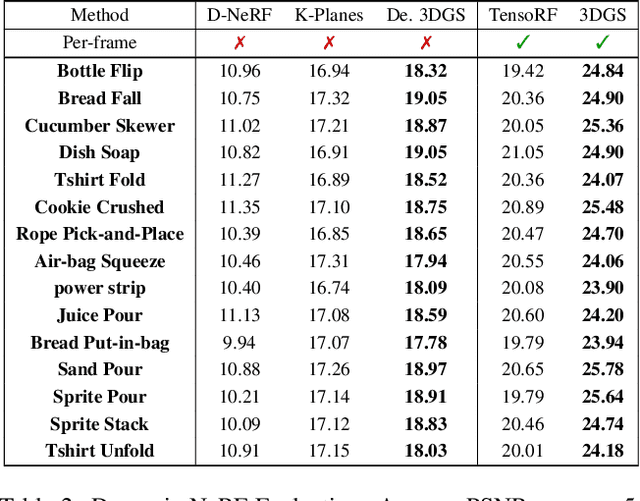

Building robots that can automate labor-intensive tasks has long been the core motivation behind the advancements in computer vision and the robotics community. Recent interest in leveraging 3D algorithms, particularly neural fields, has led to advancements in robot perception and physical understanding in manipulation scenarios. However, the real world's complexity poses significant challenges. To tackle these challenges, we present Robo360, a dataset that features robotic manipulation with a dense view coverage, which enables high-quality 3D neural representation learning, and a diverse set of objects with various physical and optical properties and facilitates research in various object manipulation and physical world modeling tasks. We confirm the effectiveness of our dataset using existing dynamic NeRF and evaluate its potential in learning multi-view policies. We hope that Robo360 can open new research directions yet to be explored at the intersection of understanding the physical world in 3D and robot control.
OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
Sep 14, 2023
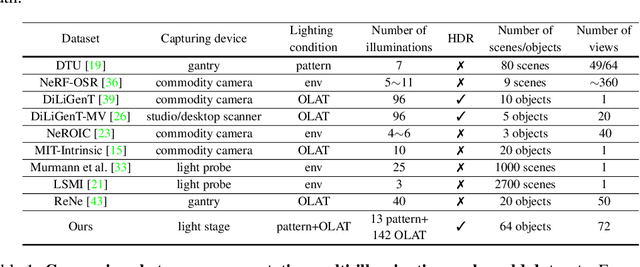

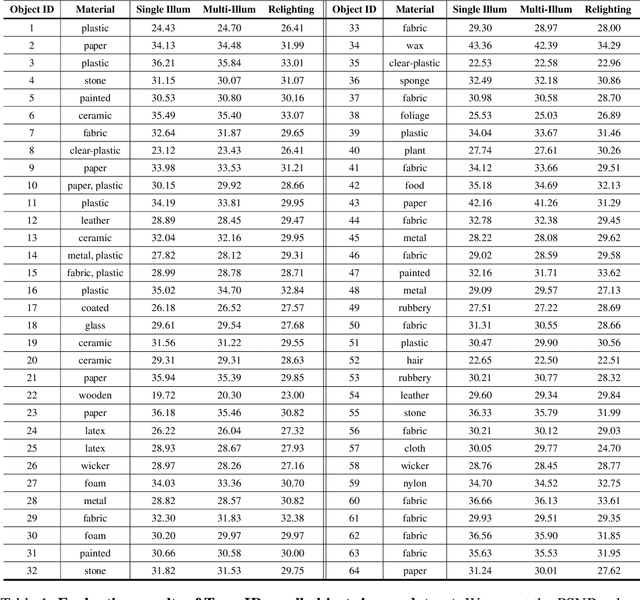
We introduce OpenIllumination, a real-world dataset containing over 108K images of 64 objects with diverse materials, captured under 72 camera views and a large number of different illuminations. For each image in the dataset, we provide accurate camera parameters, illumination ground truth, and foreground segmentation masks. Our dataset enables the quantitative evaluation of most inverse rendering and material decomposition methods for real objects. We examine several state-of-the-art inverse rendering methods on our dataset and compare their performances. The dataset and code can be found on the project page: https://oppo-us-research.github.io/OpenIllumination.
TensoIR: Tensorial Inverse Rendering
Apr 24, 2023We propose TensoIR, a novel inverse rendering approach based on tensor factorization and neural fields. Unlike previous works that use purely MLP-based neural fields, thus suffering from low capacity and high computation costs, we extend TensoRF, a state-of-the-art approach for radiance field modeling, to estimate scene geometry, surface reflectance, and environment illumination from multi-view images captured under unknown lighting conditions. Our approach jointly achieves radiance field reconstruction and physically-based model estimation, leading to photo-realistic novel view synthesis and relighting results. Benefiting from the efficiency and extensibility of the TensoRF-based representation, our method can accurately model secondary shading effects (like shadows and indirect lighting) and generally support input images captured under single or multiple unknown lighting conditions. The low-rank tensor representation allows us to not only achieve fast and compact reconstruction but also better exploit shared information under an arbitrary number of capturing lighting conditions. We demonstrate the superiority of our method to baseline methods qualitatively and quantitatively on various challenging synthetic and real-world scenes.