 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRoam: World Wandering via Long-Horizon Panoramic Video Generation
Mar 31, 2026Modeling scenes using video generation models has garnered growing research interest in recent years. However, most existing approaches rely on perspective video models that synthesize only limited observations of a scene, leading to issues of completeness and global consistency. We propose OmniRoam, a controllable panoramic video generation framework that exploits the rich per-frame scene coverage and inherent long-term spatial and temporal consistency of panoramic representation, enabling long-horizon scene wandering. Our framework begins with a preview stage, where a trajectory-controlled video generation model creates a quick overview of the scene from a given input image or video. Then, in the refine stage, this video is temporally extended and spatially upsampled to produce long-range, high-resolution videos, thus enabling high-fidelity world wandering. To train our model, we introduce two panoramic video datasets that incorporate both synthetic and real-world captured videos. Experiments show that our framework consistently outperforms state-of-the-art methods in terms of visual quality, controllability, and long-term scene consistency, both qualitatively and quantitatively. We further showcase several extensions of this framework, including real-time video generation and 3D reconstruction. Code is available at https://github.com/yuhengliu02/OmniRoam.
LoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
RigAnything: Template-Free Autoregressive Rigging for Diverse 3D Assets
Feb 13, 2025


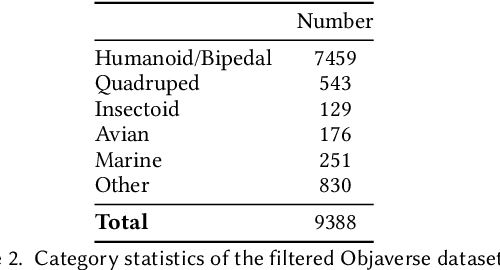
We present RigAnything, a novel autoregressive transformer-based model, which makes 3D assets rig-ready by probabilistically generating joints, skeleton topologies, and assigning skinning weights in a template-free manner. Unlike most existing auto-rigging methods, which rely on predefined skeleton template and are limited to specific categories like humanoid, RigAnything approaches the rigging problem in an autoregressive manner, iteratively predicting the next joint based on the global input shape and the previous prediction. While autoregressive models are typically used to generate sequential data, RigAnything extends their application to effectively learn and represent skeletons, which are inherently tree structures. To achieve this, we organize the joints in a breadth-first search (BFS) order, enabling the skeleton to be defined as a sequence of 3D locations and the parent index. Furthermore, our model improves the accuracy of position prediction by leveraging diffusion modeling, ensuring precise and consistent placement of joints within the hierarchy. This formulation allows the autoregressive model to efficiently capture both spatial and hierarchical relationships within the skeleton. Trained end-to-end on both RigNet and Objaverse datasets, RigAnything demonstrates state-of-the-art performance across diverse object types, including humanoids, quadrupeds, marine creatures, insects, and many more, surpassing prior methods in quality, robustness, generalizability, and efficiency. Please check our website for more details: https://www.liuisabella.com/RigAnything.
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Mar 21, 2024



We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
Real-time 3D-aware Portrait Editing from a Single Image
Feb 21, 2024
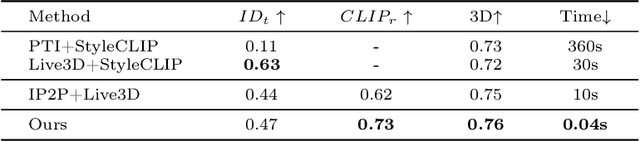
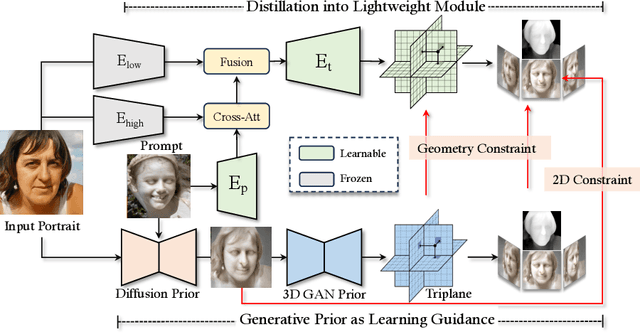

This work presents 3DPE, a practical tool that can efficiently edit a face image following given prompts, like reference images or text descriptions, in the 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and open-vocabulary editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified novel types of editing during inference (e.g., with ~5min fine-tuning per case). The code, the model, and the interface will be made publicly available to facilitate future research.
Learning Naturally Aggregated Appearance for Efficient 3D Editing
Dec 11, 2023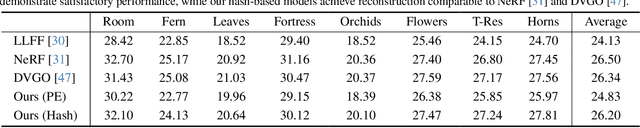

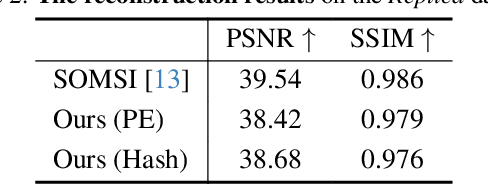

Neural radiance fields, which represent a 3D scene as a color field and a density field, have demonstrated great progress in novel view synthesis yet are unfavorable for editing due to the implicitness. In view of such a deficiency, we propose to replace the color field with an explicit 2D appearance aggregation, also called canonical image, with which users can easily customize their 3D editing via 2D image processing. To avoid the distortion effect and facilitate convenient editing, we complement the canonical image with a projection field that maps 3D points onto 2D pixels for texture lookup. This field is carefully initialized with a pseudo canonical camera model and optimized with offset regularity to ensure naturalness of the aggregated appearance. Extensive experimental results on three datasets suggest that our representation, dubbed AGAP, well supports various ways of 3D editing (e.g., stylization, interactive drawing, and content extraction) with no need of re-optimization for each case, demonstrating its generalizability and efficiency. Project page is available at https://felixcheng97.github.io/AGAP/.
GenDeF: Learning Generative Deformation Field for Video Generation
Dec 07, 2023



We offer a new perspective on approaching the task of video generation. Instead of directly synthesizing a sequence of frames, we propose to render a video by warping one static image with a generative deformation field (GenDeF). Such a pipeline enjoys three appealing advantages. First, we can sufficiently reuse a well-trained image generator to synthesize the static image (also called canonical image), alleviating the difficulty in producing a video and thereby resulting in better visual quality. Second, we can easily convert a deformation field to optical flows, making it possible to apply explicit structural regularizations for motion modeling, leading to temporally consistent results. Third, the disentanglement between content and motion allows users to process a synthesized video through processing its corresponding static image without any tuning, facilitating many applications like video editing, keypoint tracking, and video segmentation. Both qualitative and quantitative results on three common video generation benchmarks demonstrate the superiority of our GenDeF method.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023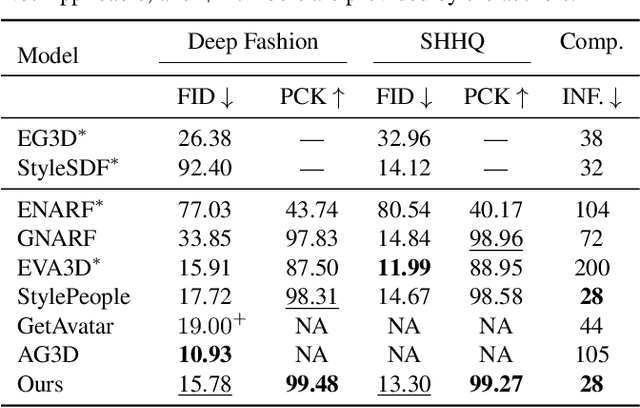



Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model
Nov 15, 2023
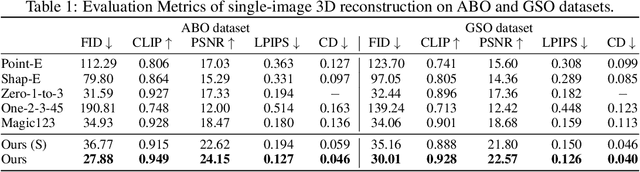

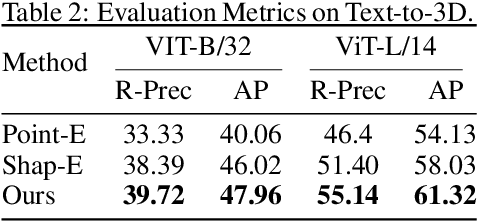
We propose \textbf{DMV3D}, a novel 3D generation approach that uses a transformer-based 3D large reconstruction model to denoise multi-view diffusion. Our reconstruction model incorporates a triplane NeRF representation and can denoise noisy multi-view images via NeRF reconstruction and rendering, achieving single-stage 3D generation in $\sim$30s on single A100 GPU. We train \textbf{DMV3D} on large-scale multi-view image datasets of highly diverse objects using only image reconstruction losses, without accessing 3D assets. We demonstrate state-of-the-art results for the single-image reconstruction problem where probabilistic modeling of unseen object parts is required for generating diverse reconstructions with sharp textures. We also show high-quality text-to-3D generation results outperforming previous 3D diffusion models. Our project website is at: https://justimyhxu.github.io/projects/dmv3d/ .
Exploring Sparse MoE in GANs for Text-conditioned Image Synthesis
Sep 07, 2023



Due to the difficulty in scaling up, generative adversarial networks (GANs) seem to be falling from grace on the task of text-conditioned image synthesis. Sparsely-activated mixture-of-experts (MoE) has recently been demonstrated as a valid solution to training large-scale models with limited computational resources. Inspired by such a philosophy, we present Aurora, a GAN-based text-to-image generator that employs a collection of experts to learn feature processing, together with a sparse router to help select the most suitable expert for each feature point. To faithfully decode the sampling stochasticity and the text condition to the final synthesis, our router adaptively makes its decision by taking into account the text-integrated global latent code. At 64x64 image resolution, our model trained on LAION2B-en and COYO-700M achieves 6.2 zero-shot FID on MS COCO. We release the code and checkpoints to facilitate the community for further development.