 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCL-Bench: Multimodal Context Learning from Visual Rules, Procedures, and Evidence
May 12, 2026We introduce MMCL-Bench, a benchmark for multimodal context learning: learning task-local rules, procedures, and empirical patterns from visual or mixed-modality teaching context and applying them to new visual instances. Unlike text-only context learning or standard multimodal question answering, this setting requires models to recover and localize relevant evidence from images, screenshots, manuals, videos, and frame sequences before they can reason over the learned context. MMCL-Bench contains 102 tasks spanning three categories: rule system application, procedural task execution, and empirical discovery and induction. We evaluate frontier multimodal models with strict rubric-based scoring and find that current systems remain far from robust multimodal context learning, with even the strongest model solving fewer than one-third of tasks under strict evaluation. Diagnostic ablations and error analysis show that failures arise throughout the context-to-answer pipeline, including context anchoring, visual evidence extraction, context reasoning, and response construction. MMCL-Bench thus highlights multimodal context learning as an important unsolved capability bottleneck for current multimodal models.
Advancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
Edicho: Consistent Image Editing in the Wild
Dec 30, 2024As a verified need, consistent editing across in-the-wild images remains a technical challenge arising from various unmanageable factors, like object poses, lighting conditions, and photography environments. Edicho steps in with a training-free solution based on diffusion models, featuring a fundamental design principle of using explicit image correspondence to direct editing. Specifically, the key components include an attention manipulation module and a carefully refined classifier-free guidance (CFG) denoising strategy, both of which take into account the pre-estimated correspondence. Such an inference-time algorithm enjoys a plug-and-play nature and is compatible to most diffusion-based editing methods, such as ControlNet and BrushNet. Extensive results demonstrate the efficacy of Edicho in consistent cross-image editing under diverse settings. We will release the code to facilitate future studies.
Real-time 3D-aware Portrait Editing from a Single Image
Feb 21, 2024
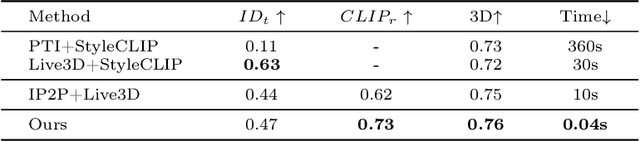
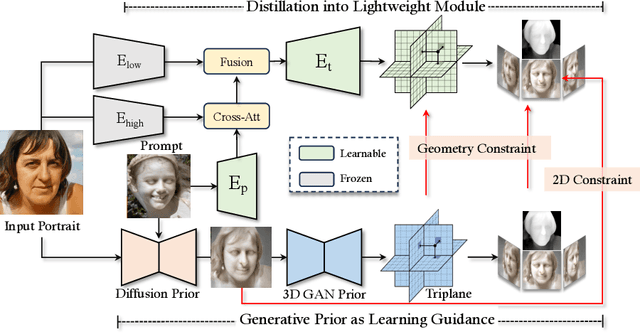

This work presents 3DPE, a practical tool that can efficiently edit a face image following given prompts, like reference images or text descriptions, in the 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and open-vocabulary editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified novel types of editing during inference (e.g., with ~5min fine-tuning per case). The code, the model, and the interface will be made publicly available to facilitate future research.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.
Revisiting the Evaluation of Image Synthesis with GANs
Apr 04, 2023
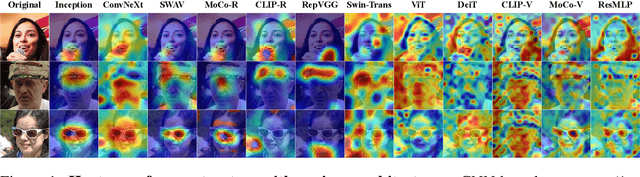


A good metric, which promises a reliable comparison between solutions, is essential to a well-defined task. Unlike most vision tasks that have per-sample ground-truth, image synthesis targets generating \emph{unseen} data and hence is usually evaluated with a distributional distance between one set of real samples and another set of generated samples. This work provides an empirical study on the evaluation of synthesis performance by taking the popular generative adversarial networks (GANs) as a representative of generative models. In particular, we make in-depth analyses on how to represent a data point in the feature space, how to calculate a fair distance using selected samples, and how many instances to use from each set. Experiments on multiple datasets and settings suggest that (1) a group of models including both CNN-based and ViT-based architectures serve as reliable and robust feature extractors, (2) Centered Kernel Alignment (CKA) enables better comparison across various extractors and hierarchical layers in one model, and (3) CKA shows satisfactory sample efficiency and complements existing metrics (\textit{e.g.}, FID) in characterizing the similarity between two internal data correlations. These findings help us design a new measurement system, based on which we re-evaluate the state-of-the-art generative models in a consistent and reliable way.
GLeaD: Improving GANs with A Generator-Leading Task
Dec 07, 2022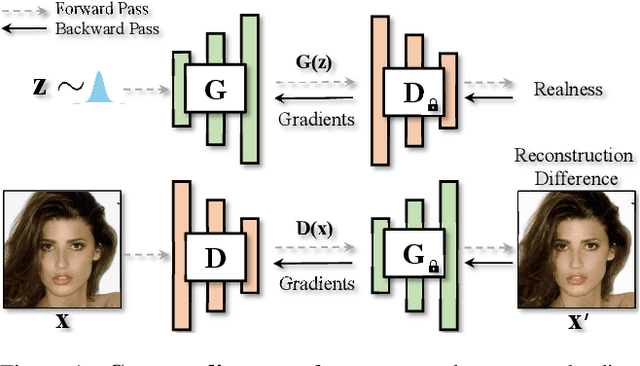



Generative adversarial network (GAN) is formulated as a two-player game between a generator (G) and a discriminator (D), where D is asked to differentiate whether an image comes from real data or is produced by G. Under such a formulation, D plays as the rule maker and hence tends to dominate the competition. Towards a fairer game in GANs, we propose a new paradigm for adversarial training, which makes G assign a task to D as well. Specifically, given an image, we expect D to extract representative features that can be adequately decoded by G to reconstruct the input. That way, instead of learning freely, D is urged to align with the view of G for domain classification. Experimental results on various datasets demonstrate the substantial superiority of our approach over the baselines. For instance, we improve the FID of StyleGAN2 from 4.30 to 2.55 on LSUN Bedroom and from 4.04 to 2.82 on LSUN Church. We believe that the pioneering attempt present in this work could inspire the community with better designed generator-leading tasks for GAN improvement.
High-fidelity GAN Inversion with Padding Space
Mar 21, 2022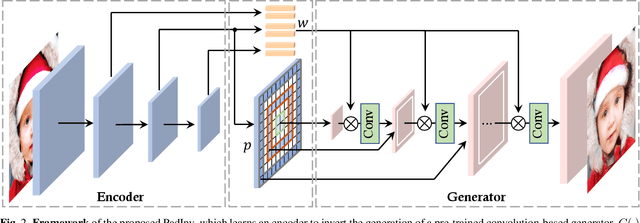



Inverting a Generative Adversarial Network (GAN) facilitates a wide range of image editing tasks using pre-trained generators. Existing methods typically employ the latent space of GANs as the inversion space yet observe the insufficient recovery of spatial details. In this work, we propose to involve the padding space of the generator to complement the latent space with spatial information. Concretely, we replace the constant padding (e.g., usually zeros) used in convolution layers with some instance-aware coefficients. In this way, the inductive bias assumed in the pre-trained model can be appropriately adapted to fit each individual image. Through learning a carefully designed encoder, we manage to improve the inversion quality both qualitatively and quantitatively, outperforming existing alternatives. We then demonstrate that such a space extension barely affects the native GAN manifold, hence we can still reuse the prior knowledge learned by GANs for various downstream applications. Beyond the editing tasks explored in prior arts, our approach allows a more flexible image manipulation, such as the separate control of face contour and facial details, and enables a novel editing manner where users can customize their own manipulations highly efficiently.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
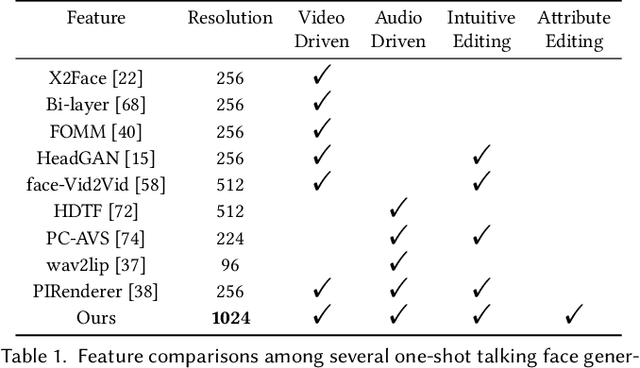

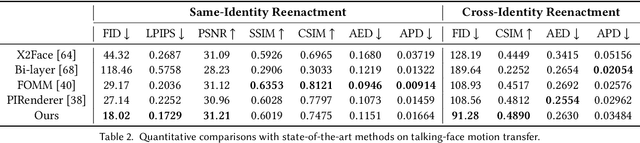
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.