 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialTree: How Spatial Abilities Branch Out in MLLMs
Dec 23, 2025Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.
SpatialTrackerV2: 3D Point Tracking Made Easy
Jul 16, 2025We present SpatialTrackerV2, a feed-forward 3D point tracking method for monocular videos. Going beyond modular pipelines built on off-the-shelf components for 3D tracking, our approach unifies the intrinsic connections between point tracking, monocular depth, and camera pose estimation into a high-performing and feedforward 3D point tracker. It decomposes world-space 3D motion into scene geometry, camera ego-motion, and pixel-wise object motion, with a fully differentiable and end-to-end architecture, allowing scalable training across a wide range of datasets, including synthetic sequences, posed RGB-D videos, and unlabeled in-the-wild footage. By learning geometry and motion jointly from such heterogeneous data, SpatialTrackerV2 outperforms existing 3D tracking methods by 30%, and matches the accuracy of leading dynamic 3D reconstruction approaches while running 50$\times$ faster.
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024



Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.
Volumetric Wireframe Parsing from Neural Attraction Fields
Jul 14, 2023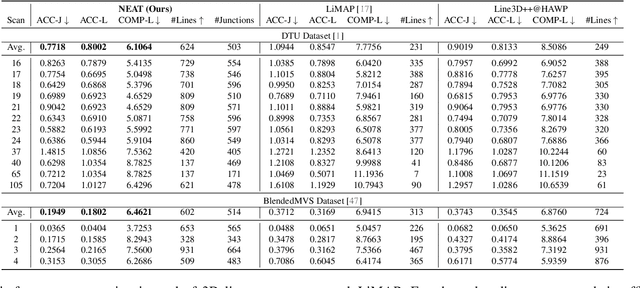
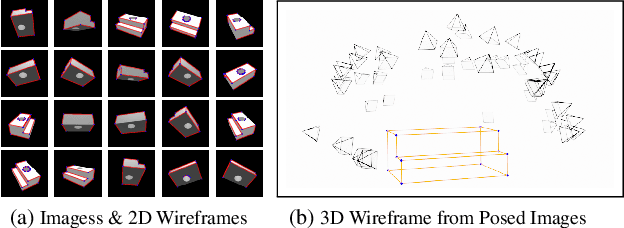
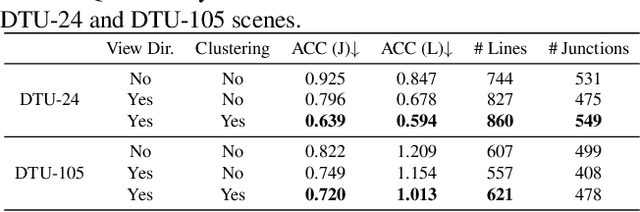
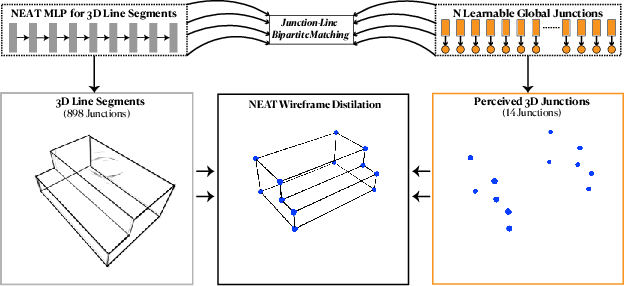
The primal sketch is a fundamental representation in Marr's vision theory, which allows for parsimonious image-level processing from 2D to 2.5D perception. This paper takes a further step by computing 3D primal sketch of wireframes from a set of images with known camera poses, in which we take the 2D wireframes in multi-view images as the basis to compute 3D wireframes in a volumetric rendering formulation. In our method, we first propose a NEural Attraction (NEAT) Fields that parameterizes the 3D line segments with coordinate Multi-Layer Perceptrons (MLPs), enabling us to learn the 3D line segments from 2D observation without incurring any explicit feature correspondences across views. We then present a novel Global Junction Perceiving (GJP) module to perceive meaningful 3D junctions from the NEAT Fields of 3D line segments by optimizing a randomly initialized high-dimensional latent array and a lightweight decoding MLP. Benefitting from our explicit modeling of 3D junctions, we finally compute the primal sketch of 3D wireframes by attracting the queried 3D line segments to the 3D junctions, significantly simplifying the computation paradigm of 3D wireframe parsing. In experiments, we evaluate our approach on the DTU and BlendedMVS datasets with promising performance obtained. As far as we know, our method is the first approach to achieve high-fidelity 3D wireframe parsing without requiring explicit matching.
Level-S$^2$fM: Structure from Motion on Neural Level Set of Implicit Surfaces
Nov 22, 2022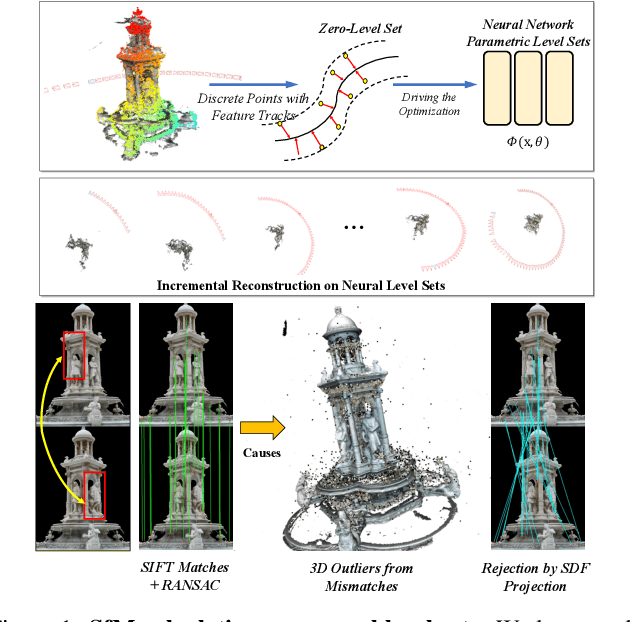
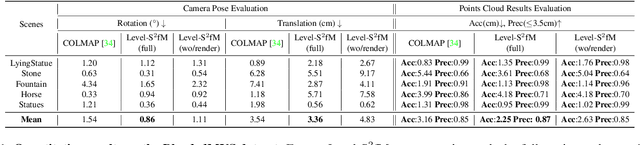
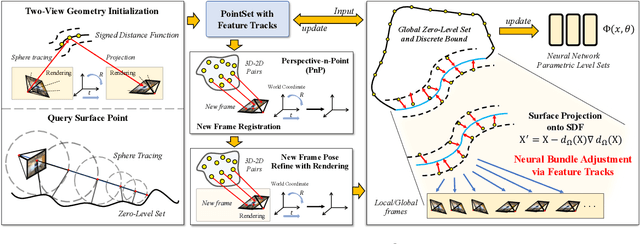
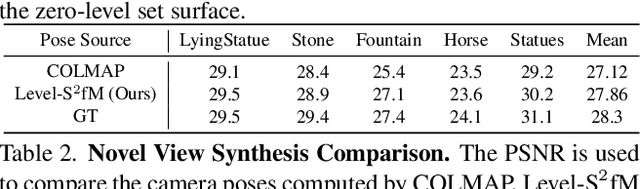
This paper presents a neural incremental Structure-from-Motion (SfM) approach, Level-S$^2$fM. In our formulation, we aim at simultaneously learning coordinate MLPs for the implicit surfaces and the radiance fields, and estimating the camera poses and scene geometry, which is mainly sourced from the established keypoint correspondences by SIFT. Our formulation would face some new challenges due to inevitable two-view and few-view configurations at the beginning of incremental SfM pipeline for the optimization of coordinate MLPs, but we found that the strong inductive biases conveying in the 2D correspondences are feasible and promising to avoid those challenges by exploiting the relationship between the ray sampling schemes used in volumetric rendering and the sphere tracing of finding the zero-level set of implicit surfaces. Based on this, we revisit the pipeline of incremental SfM and renew the key components of two-view geometry initialization, the camera pose registration, and the 3D points triangulation, as well as the Bundle Adjustment in a novel perspective of neural implicit surfaces. Because the coordinate MLPs unified the scene geometry in small MLP networks, our Level-S$^2$fM treats the zero-level set of the implicit surface as an informative top-down regularization to manage the reconstructed 3D points, reject the outlier of correspondences by querying SDF, adjust the estimated geometries by NBA (Neural BA), finally yielding promising results of 3D reconstruction. Furthermore, our Level-S$^2$fM alleviated the requirement of camera poses for neural 3D reconstruction.
DeepMLE: A Robust Deep Maximum Likelihood Estimator for Two-view Structure from Motion
Oct 11, 2022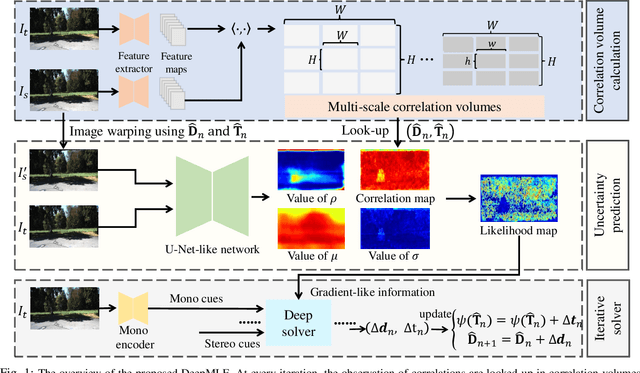
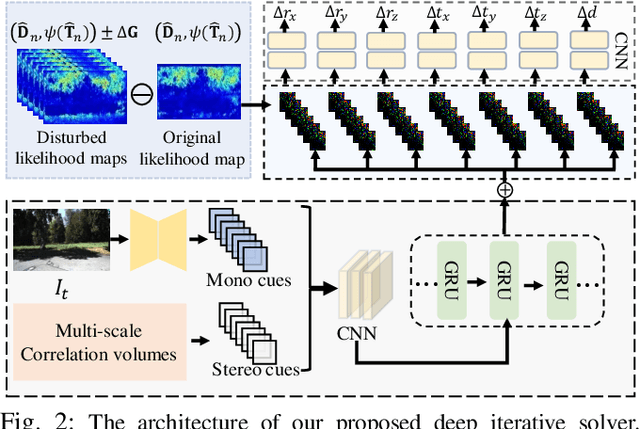

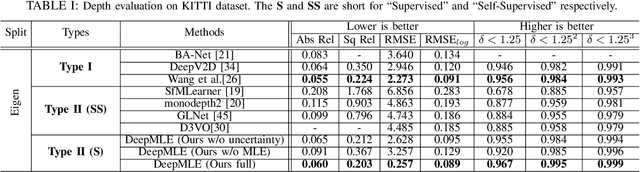
Two-view structure from motion (SfM) is the cornerstone of 3D reconstruction and visual SLAM (vSLAM). Many existing end-to-end learning-based methods usually formulate it as a brute regression problem. However, the inadequate utilization of traditional geometry model makes the model not robust in unseen environments. To improve the generalization capability and robustness of end-to-end two-view SfM network, we formulate the two-view SfM problem as a maximum likelihood estimation (MLE) and solve it with the proposed framework, denoted as DeepMLE. First, we propose to take the deep multi-scale correlation maps to depict the visual similarities of 2D image matches decided by ego-motion. In addition, in order to increase the robustness of our framework, we formulate the likelihood function of the correlations of 2D image matches as a Gaussian and Uniform mixture distribution which takes the uncertainty caused by illumination changes, image noise and moving objects into account. Meanwhile, an uncertainty prediction module is presented to predict the pixel-wise distribution parameters. Finally, we iteratively refine the depth and relative camera pose using the gradient-like information to maximize the likelihood function of the correlations. Extensive experimental results on several datasets prove that our method significantly outperforms the state-of-the-art end-to-end two-view SfM approaches in accuracy and generalization capability.