 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteracted Planes Reveal 3D Line Mapping
Feb 01, 20263D line mapping from multi-view RGB images provides a compact and structured visual representation of scenes. We study the problem from a physical and topological perspective: a 3D line most naturally emerges as the edge of a finite 3D planar patch. We present LiP-Map, a line-plane joint optimization framework that explicitly models learnable line and planar primitives. This coupling enables accurate and detailed 3D line mapping while maintaining strong efficiency (typically completing a reconstruction in 3 to 5 minutes per scene). LiP-Map pioneers the integration of planar topology into 3D line mapping, not by imposing pairwise coplanarity constraints but by explicitly constructing interactions between plane and line primitives, thus offering a principled route toward structured reconstruction in man-made environments. On more than 100 scenes from ScanNetV2, ScanNet++, Hypersim, 7Scenes, and Tanks\&Temple, LiP-Map improves both accuracy and completeness over state-of-the-art methods. Beyond line mapping quality, LiP-Map significantly advances line-assisted visual localization, establishing strong performance on 7Scenes. Our code is released at https://github.com/calmke/LiPMAP for reproducible research.
Masked Depth Modeling for Spatial Perception
Jan 25, 2026Spatial visual perception is a fundamental requirement in physical-world applications like autonomous driving and robotic manipulation, driven by the need to interact with 3D environments. Capturing pixel-aligned metric depth using RGB-D cameras would be the most viable way, yet it usually faces obstacles posed by hardware limitations and challenging imaging conditions, especially in the presence of specular or texture-less surfaces. In this work, we argue that the inaccuracies from depth sensors can be viewed as "masked" signals that inherently reflect underlying geometric ambiguities. Building on this motivation, we present LingBot-Depth, a depth completion model which leverages visual context to refine depth maps through masked depth modeling and incorporates an automated data curation pipeline for scalable training. It is encouraging to see that our model outperforms top-tier RGB-D cameras in terms of both depth precision and pixel coverage. Experimental results on a range of downstream tasks further suggest that LingBot-Depth offers an aligned latent representation across RGB and depth modalities. We release the code, checkpoint, and 3M RGB-depth pairs (including 2M real data and 1M simulated data) to the community of spatial perception.
PCR-CA: Parallel Codebook Representations with Contrastive Alignment for Multiple-Category App Recommendation
Aug 25, 2025Modern app store recommender systems struggle with multiple-category apps, as traditional taxonomies fail to capture overlapping semantics, leading to suboptimal personalization. We propose PCR-CA (Parallel Codebook Representations with Contrastive Alignment), an end-to-end framework for improved CTR prediction. PCR-CA first extracts compact multimodal embeddings from app text, then introduces a Parallel Codebook VQ-AE module that learns discrete semantic representations across multiple codebooks in parallel -- unlike hierarchical residual quantization (RQ-VAE). This design enables independent encoding of diverse aspects (e.g., gameplay, art style), better modeling multiple-category semantics. To bridge semantic and collaborative signals, we employ a contrastive alignment loss at both the user and item levels, enhancing representation learning for long-tail items. Additionally, a dual-attention fusion mechanism combines ID-based and semantic features to capture user interests, especially for long-tail apps. Experiments on a large-scale dataset show PCR-CA achieves a +0.76% AUC improvement over strong baselines, with +2.15% AUC gains for long-tail apps. Online A/B testing further validates our approach, showing a +10.52% lift in CTR and a +16.30% improvement in CVR, demonstrating PCR-CA's effectiveness in real-world deployment. The new framework has now been fully deployed on the Microsoft Store.
ScaleLSD: Scalable Deep Line Segment Detection Streamlined
Jun 11, 2025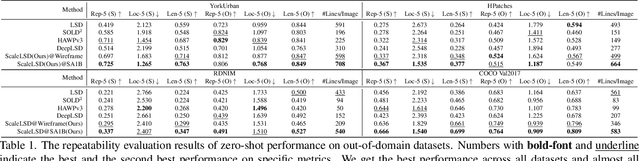

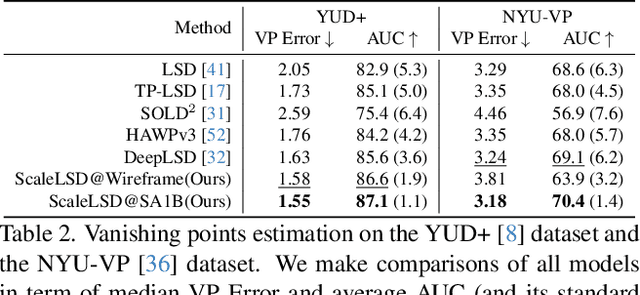

This paper studies the problem of Line Segment Detection (LSD) for the characterization of line geometry in images, with the aim of learning a domain-agnostic robust LSD model that works well for any natural images. With the focus of scalable self-supervised learning of LSD, we revisit and streamline the fundamental designs of (deep and non-deep) LSD approaches to have a high-performing and efficient LSD learner, dubbed as ScaleLSD, for the curation of line geometry at scale from over 10M unlabeled real-world images. Our ScaleLSD works very well to detect much more number of line segments from any natural images even than the pioneered non-deep LSD approach, having a more complete and accurate geometric characterization of images using line segments. Experimentally, our proposed ScaleLSD is comprehensively testified under zero-shot protocols in detection performance, single-view 3D geometry estimation, two-view line segment matching, and multiview 3D line mapping, all with excellent performance obtained. Based on the thorough evaluation, our ScaleLSD is observed to be the first deep approach that outperforms the pioneered non-deep LSD in all aspects we have tested, significantly expanding and reinforcing the versatility of the line geometry of images. Code and Models are available at https://github.com/ant-research/scalelsd
Seeing through Satellite Images at Street Views
May 22, 2025This paper studies the task of SatStreet-view synthesis, which aims to render photorealistic street-view panorama images and videos given any satellite image and specified camera positions or trajectories. We formulate to learn neural radiance field from paired images captured from satellite and street viewpoints, which comes to be a challenging learning problem due to the sparse-view natural and the extremely-large viewpoint changes between satellite and street-view images. We tackle the challenges based on a task-specific observation that street-view specific elements, including the sky and illumination effects are only visible in street-view panoramas, and present a novel approach Sat2Density++ to accomplish the goal of photo-realistic street-view panoramas rendering by modeling these street-view specific in neural networks. In the experiments, our method is testified on both urban and suburban scene datasets, demonstrating that Sat2Density++ is capable of rendering photorealistic street-view panoramas that are consistent across multiple views and faithful to the satellite image.
DepthLab: From Partial to Complete
Dec 24, 2024



Missing values remain a common challenge for depth data across its wide range of applications, stemming from various causes like incomplete data acquisition and perspective alteration. This work bridges this gap with DepthLab, a foundation depth inpainting model powered by image diffusion priors. Our model features two notable strengths: (1) it demonstrates resilience to depth-deficient regions, providing reliable completion for both continuous areas and isolated points, and (2) it faithfully preserves scale consistency with the conditioned known depth when filling in missing values. Drawing on these advantages, our approach proves its worth in various downstream tasks, including 3D scene inpainting, text-to-3D scene generation, sparse-view reconstruction with DUST3R, and LiDAR depth completion, exceeding current solutions in both numerical performance and visual quality. Our project page with source code is available at https://johanan528.github.io/depthlab_web/.
PlanarSplatting: Accurate Planar Surface Reconstruction in 3 Minutes
Dec 04, 2024
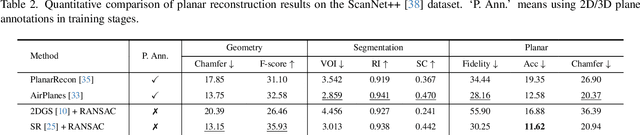
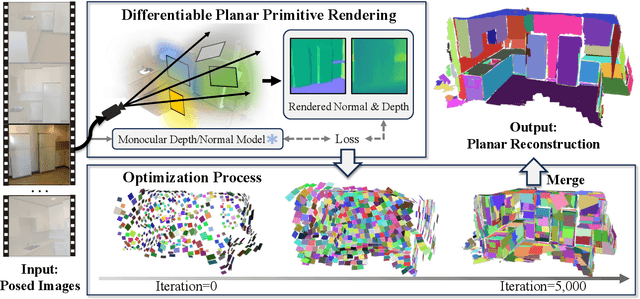
This paper presents PlanarSplatting, an ultra-fast and accurate surface reconstruction approach for multiview indoor images. We take the 3D planes as the main objective due to their compactness and structural expressiveness in indoor scenes, and develop an explicit optimization framework that learns to fit the expected surface of indoor scenes by splatting the 3D planes into 2.5D depth and normal maps. As our PlanarSplatting operates directly on the 3D plane primitives, it eliminates the dependencies on 2D/3D plane detection and plane matching and tracking for planar surface reconstruction. Furthermore, the essential merits of plane-based representation plus CUDA-based implementation of planar splatting functions, PlanarSplatting reconstructs an indoor scene in 3 minutes while having significantly better geometric accuracy. Thanks to our ultra-fast reconstruction speed, the largest quantitative evaluation on the ScanNet and ScanNet++ datasets over hundreds of scenes clearly demonstrated the advantages of our method. We believe that our accurate and ultrafast planar surface reconstruction method will be applied in the structured data curation for surface reconstruction in the future. The code of our CUDA implementation will be publicly available. Project page: https://icetttb.github.io/PlanarSplatting/
The Rise of Artificial Intelligence in Educational Measurement: Opportunities and Ethical Challenges
Jun 27, 2024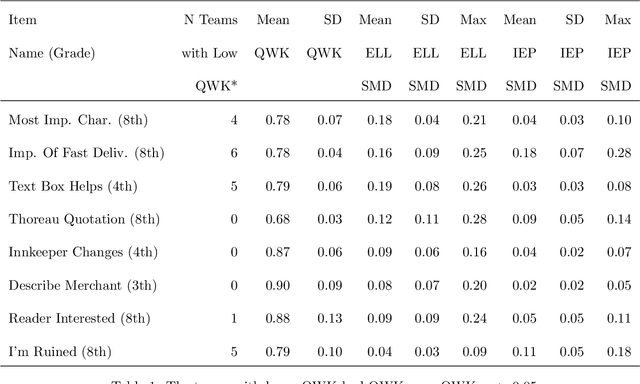
The integration of artificial intelligence (AI) in educational measurement has revolutionized assessment methods, enabling automated scoring, rapid content analysis, and personalized feedback through machine learning and natural language processing. These advancements provide timely, consistent feedback and valuable insights into student performance, thereby enhancing the assessment experience. However, the deployment of AI in education also raises significant ethical concerns regarding validity, reliability, transparency, fairness, and equity. Issues such as algorithmic bias and the opacity of AI decision-making processes pose risks of perpetuating inequalities and affecting assessment outcomes. Responding to these concerns, various stakeholders, including educators, policymakers, and organizations, have developed guidelines to ensure ethical AI use in education. The National Council of Measurement in Education's Special Interest Group on AI in Measurement and Education (AIME) also focuses on establishing ethical standards and advancing research in this area. In this paper, a diverse group of AIME members examines the ethical implications of AI-powered tools in educational measurement, explores significant challenges such as automation bias and environmental impact, and proposes solutions to ensure AI's responsible and effective use in education.
Volumetric Wireframe Parsing from Neural Attraction Fields
Jul 14, 2023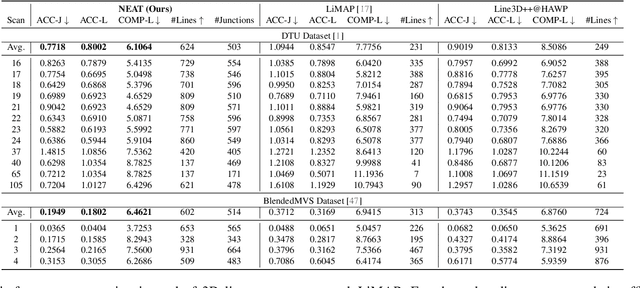
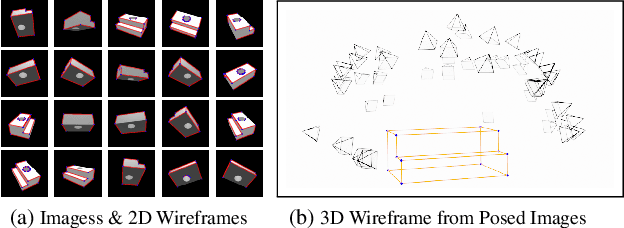
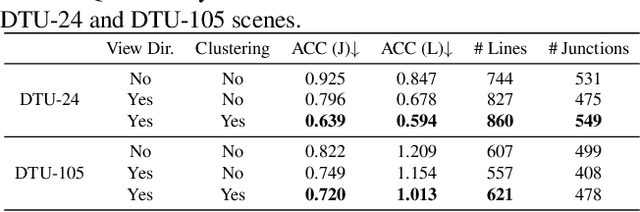
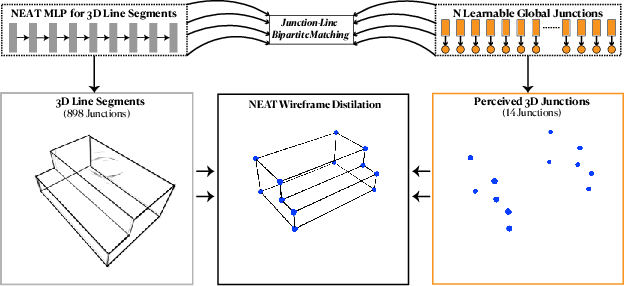
The primal sketch is a fundamental representation in Marr's vision theory, which allows for parsimonious image-level processing from 2D to 2.5D perception. This paper takes a further step by computing 3D primal sketch of wireframes from a set of images with known camera poses, in which we take the 2D wireframes in multi-view images as the basis to compute 3D wireframes in a volumetric rendering formulation. In our method, we first propose a NEural Attraction (NEAT) Fields that parameterizes the 3D line segments with coordinate Multi-Layer Perceptrons (MLPs), enabling us to learn the 3D line segments from 2D observation without incurring any explicit feature correspondences across views. We then present a novel Global Junction Perceiving (GJP) module to perceive meaningful 3D junctions from the NEAT Fields of 3D line segments by optimizing a randomly initialized high-dimensional latent array and a lightweight decoding MLP. Benefitting from our explicit modeling of 3D junctions, we finally compute the primal sketch of 3D wireframes by attracting the queried 3D line segments to the 3D junctions, significantly simplifying the computation paradigm of 3D wireframe parsing. In experiments, we evaluate our approach on the DTU and BlendedMVS datasets with promising performance obtained. As far as we know, our method is the first approach to achieve high-fidelity 3D wireframe parsing without requiring explicit matching.
NOPE-SAC: Neural One-Plane RANSAC for Sparse-View Planar 3D Reconstruction
Nov 30, 2022This paper studies the challenging two-view 3D reconstruction in a rigorous sparse-view configuration, which is suffering from insufficient correspondences in the input image pairs for camera pose estimation. We present a novel Neural One-PlanE RANSAC framework (termed NOPE-SAC in short) that exerts excellent capability to learn one-plane pose hypotheses from 3D plane correspondences. Building on the top of a siamese plane detection network, our NOPE-SAC first generates putative plane correspondences with a coarse initial pose. It then feeds the learned 3D plane parameters of correspondences into shared MLPs to estimate the one-plane camera pose hypotheses, which are subsequently reweighed in a RANSAC manner to obtain the final camera pose. Because the neural one-plane pose minimizes the number of plane correspondences for adaptive pose hypotheses generation, it enables stable pose voting and reliable pose refinement in a few plane correspondences for the sparse-view inputs. In the experiments, we demonstrate that our NOPE-SAC significantly improves the camera pose estimation for the two-view inputs with severe viewpoint changes, setting several new state-of-the-art performances on two challenging benchmarks, i.e., MatterPort3D and ScanNet, for sparse-view 3D reconstruction. The source code is released at https://github.com/IceTTTb/NopeSAC for reproducible research.