 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoW-3D: Holistic 3D Wireframe Perception from a Single Image
Paper and Code
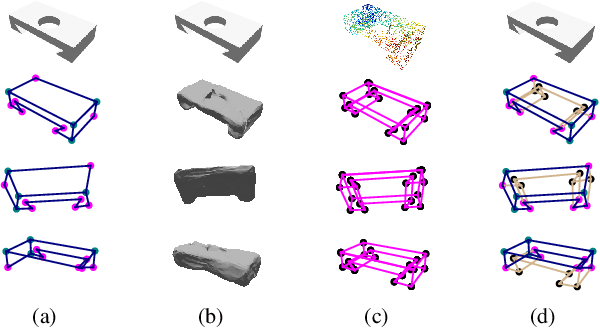

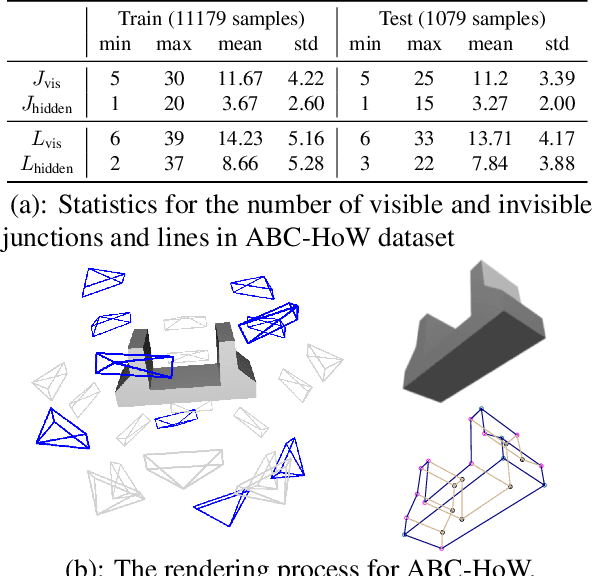
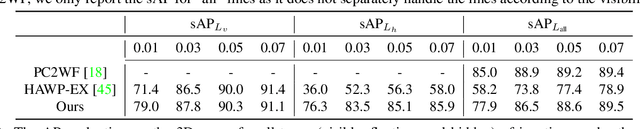
This paper studies the problem of holistic 3D wireframe perception (HoW-3D), a new task of perceiving both the visible 3D wireframes and the invisible ones from single-view 2D images. As the non-front surfaces of an object cannot be directly observed in a single view, estimating the non-line-of-sight (NLOS) geometries in HoW-3D is a fundamentally challenging problem and remains open in computer vision. We study the problem of HoW-3D by proposing an ABC-HoW benchmark, which is created on top of CAD models sourced from the ABC-dataset with 12k single-view images and the corresponding holistic 3D wireframe models. With our large-scale ABC-HoW benchmark available, we present a novel Deep Spatial Gestalt (DSG) model to learn the visible junctions and line segments as the basis and then infer the NLOS 3D structures from the visible cues by following the Gestalt principles of human vision systems. In our experiments, we demonstrate that our DSG model performs very well in inferring the holistic 3D wireframes from single-view images. Compared with the strong baseline methods, our DSG model outperforms the previous wireframe detectors in detecting the invisible line geometry in single-view images and is even very competitive with prior arts that take high-fidelity PointCloud as inputs on reconstructing 3D wireframes.