 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceal, Reconstruct, Jailbreak: Exploiting the Reconstruction-Concealment Tradeoff in MLLMs
May 07, 2026Intent-obfuscation-based jailbreak attacks on multimodal large language models (MLLMs) transform a harmful query into a concealed multimodal input to bypass safety mechanisms. We show that such attacks are governed by a \emph{reconstruction--concealment tradeoff}: the transformed input must hide harmful intent from safety filters while remaining recoverable enough for the victim model to reconstruct the original request. Through a reconstruction analysis of three representative black-box methods, we find that existing transformations struggle to balance this tradeoff, limiting their effectiveness. In contrast, we show that character-removed variants achieve a better balance. Building on this, we propose \emph{concealment-aware variant construction}, which greedily selects character-removed variants that are low in harmful-keyword alignment and mutually diverse, and instantiates them through five modality-aware prompting strategies. We further introduce \emph{keyword-related distractor images} that depict the harmful keyword in diverse contexts, providing more effective auxiliary visual context than generic distractor images. Experiments across closed-source and open-source MLLMs show the proposed strategies outperform strong baselines, revealing an underexplored vulnerability: a model's own reconstruction ability can be exploited to recover hidden harmful intent and produce unsafe responses.
ScaleLSD: Scalable Deep Line Segment Detection Streamlined
Jun 11, 2025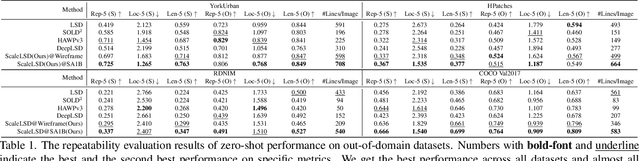

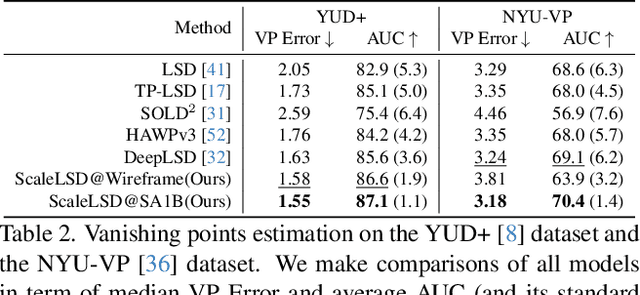

This paper studies the problem of Line Segment Detection (LSD) for the characterization of line geometry in images, with the aim of learning a domain-agnostic robust LSD model that works well for any natural images. With the focus of scalable self-supervised learning of LSD, we revisit and streamline the fundamental designs of (deep and non-deep) LSD approaches to have a high-performing and efficient LSD learner, dubbed as ScaleLSD, for the curation of line geometry at scale from over 10M unlabeled real-world images. Our ScaleLSD works very well to detect much more number of line segments from any natural images even than the pioneered non-deep LSD approach, having a more complete and accurate geometric characterization of images using line segments. Experimentally, our proposed ScaleLSD is comprehensively testified under zero-shot protocols in detection performance, single-view 3D geometry estimation, two-view line segment matching, and multiview 3D line mapping, all with excellent performance obtained. Based on the thorough evaluation, our ScaleLSD is observed to be the first deep approach that outperforms the pioneered non-deep LSD in all aspects we have tested, significantly expanding and reinforcing the versatility of the line geometry of images. Code and Models are available at https://github.com/ant-research/scalelsd
Design of a Formation Control System to Assist Human Operators in Flying a Swarm of Robotic Blimps
May 14, 2025Formation control is essential for swarm robotics, enabling coordinated behavior in complex environments. In this paper, we introduce a novel formation control system for an indoor blimp swarm using a specialized leader-follower approach enhanced with a dynamic leader-switching mechanism. This strategy allows any blimp to take on the leader role, distributing maneuvering demands across the swarm and enhancing overall formation stability. Only the leader blimp is manually controlled by a human operator, while follower blimps use onboard monocular cameras and a laser altimeter for relative position and altitude estimation. A leader-switching scheme is proposed to assist the human operator to maintain stability of the swarm, especially when a sharp turn is performed. Experimental results confirm that the leader-switching mechanism effectively maintains stable formations and adapts to dynamic indoor environments while assisting human operator.
H$^3$GNNs: Harmonizing Heterophily and Homophily in GNNs via Joint Structural Node Encoding and Self-Supervised Learning
Apr 16, 2025Graph Neural Networks (GNNs) struggle to balance heterophily and homophily in representation learning, a challenge further amplified in self-supervised settings. We propose H$^3$GNNs, an end-to-end self-supervised learning framework that harmonizes both structural properties through two key innovations: (i) Joint Structural Node Encoding. We embed nodes into a unified space combining linear and non-linear feature projections with K-hop structural representations via a Weighted Graph Convolution Network(WGCN). A cross-attention mechanism enhances awareness and adaptability to heterophily and homophily. (ii) Self-Supervised Learning Using Teacher-Student Predictive Architectures with Node-Difficulty Driven Dynamic Masking Strategies. We use a teacher-student model, the student sees the masked input graph and predicts node features inferred by the teacher that sees the full input graph in the joint encoding space. To enhance learning difficulty, we introduce two novel node-predictive-difficulty-based masking strategies. Experiments on seven benchmarks (four heterophily datasets and three homophily datasets) confirm the effectiveness and efficiency of H$^3$GNNs across diverse graph types. Our H$^3$GNNs achieves overall state-of-the-art performance on the four heterophily datasets, while retaining on-par performance to previous state-of-the-art methods on the three homophily datasets.
GSBA$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 18, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBA$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBA$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBA$^K$ in crafting $top$-$K$ adversarial examples.
GSBAK$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 17, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBAK$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBAK$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBAK$^K$ in crafting $top$-$K$ adversarial examples.
BEINGS: Bayesian Embodied Image-goal Navigation with Gaussian Splatting
Sep 16, 2024



Image-goal navigation enables a robot to reach the location where a target image was captured, using visual cues for guidance. However, current methods either rely heavily on data and computationally expensive learning-based approaches or lack efficiency in complex environments due to insufficient exploration strategies. To address these limitations, we propose Bayesian Embodied Image-goal Navigation Using Gaussian Splatting, a novel method that formulates ImageNav as an optimal control problem within a model predictive control framework. BEINGS leverages 3D Gaussian Splatting as a scene prior to predict future observations, enabling efficient, real-time navigation decisions grounded in the robot's sensory experiences. By integrating Bayesian updates, our method dynamically refines the robot's strategy without requiring extensive prior experience or data. Our algorithm is validated through extensive simulations and physical experiments, showcasing its potential for embodied robot systems in visually complex scenarios.
A Hybrid Controller Design for Human-Assistive Piloting of an Underactuated Blimp
Jun 15, 2024



This paper introduces a novel solution to the manual control challenge for indoor blimps. The problem's complexity arises from the conflicting demands of executing human commands while maintaining stability through automatic control for underactuated robots. To tackle this challenge, we introduced an assisted piloting hybrid controller with a preemptive mechanism, that seamlessly switches between executing human commands and activating automatic stabilization control. Our algorithm ensures that the automatic stabilization controller operates within the time delay between human observation and perception, providing assistance to the driver in a way that remains imperceptible.
A Pixel Is Worth More Than One 3D Gaussians in Single-View 3D Reconstruction
Jun 03, 2024



Learning 3D scene representation from a single-view image is a long-standing fundamental problem in computer vision, with the inherent ambiguity in predicting contents unseen from the input view. Built on the recently proposed 3D Gaussian Splatting (3DGS), the Splatter Image method has made promising progress on fast single-image novel view synthesis via learning a single 3D Gaussian for each pixel based on the U-Net feature map of an input image. However, it has limited expressive power to represent occluded components that are not observable in the input view. To address this problem, this paper presents a Hierarchical Splatter Image method in which a pixel is worth more than one 3D Gaussians. Specifically, each pixel is represented by a parent 3D Gaussian and a small number of child 3D Gaussians. Parent 3D Gaussians are learned as done in the vanilla Splatter Image. Child 3D Gaussians are learned via a lightweight Multi-Layer Perceptron (MLP) which takes as input the projected image features of a parent 3D Gaussian and the embedding of a target camera view. Both parent and child 3D Gaussians are learned end-to-end in a stage-wise way. The joint condition of input image features from eyes of the parent Gaussians and the target camera position facilitates learning to allocate child Gaussians to ``see the unseen'', recovering the occluded details that are often missed by parent Gaussians. In experiments, the proposed method is tested on the ShapeNet-SRN and CO3D datasets with state-of-the-art performance obtained, especially showing promising capabilities of reconstructing occluded contents in the input view.
NuRF: Nudging the Particle Filter in Radiance Fields for Robot Visual Localization
Jun 01, 2024



Can we localize a robot in radiance fields only using monocular vision? This study presents NuRF, a nudged particle filter framework for 6-DoF robot visual localization in radiance fields. NuRF sets anchors in SE(3) to leverage visual place recognition, which provides image comparisons to guide the sampling process. This guidance could improve the convergence and robustness of particle filters for robot localization. Additionally, an adaptive scheme is designed to enhance the performance of NuRF, thus enabling both global visual localization and local pose tracking. Real-world experiments are conducted with comprehensive tests to demonstrate the effectiveness of NuRF. The results showcase the advantages of NuRF in terms of accuracy and efficiency, including comparisons with alternative approaches. Furthermore, we report our findings for future studies and advancements in robot navigation in radiance fields.