 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pixel Is Worth More Than One 3D Gaussians in Single-View 3D Reconstruction
Jun 03, 2024



Learning 3D scene representation from a single-view image is a long-standing fundamental problem in computer vision, with the inherent ambiguity in predicting contents unseen from the input view. Built on the recently proposed 3D Gaussian Splatting (3DGS), the Splatter Image method has made promising progress on fast single-image novel view synthesis via learning a single 3D Gaussian for each pixel based on the U-Net feature map of an input image. However, it has limited expressive power to represent occluded components that are not observable in the input view. To address this problem, this paper presents a Hierarchical Splatter Image method in which a pixel is worth more than one 3D Gaussians. Specifically, each pixel is represented by a parent 3D Gaussian and a small number of child 3D Gaussians. Parent 3D Gaussians are learned as done in the vanilla Splatter Image. Child 3D Gaussians are learned via a lightweight Multi-Layer Perceptron (MLP) which takes as input the projected image features of a parent 3D Gaussian and the embedding of a target camera view. Both parent and child 3D Gaussians are learned end-to-end in a stage-wise way. The joint condition of input image features from eyes of the parent Gaussians and the target camera position facilitates learning to allocate child Gaussians to ``see the unseen'', recovering the occluded details that are often missed by parent Gaussians. In experiments, the proposed method is tested on the ShapeNet-SRN and CO3D datasets with state-of-the-art performance obtained, especially showing promising capabilities of reconstructing occluded contents in the input view.
Learning Inception Attention for Image Synthesis and Image Recognition
Dec 29, 2021

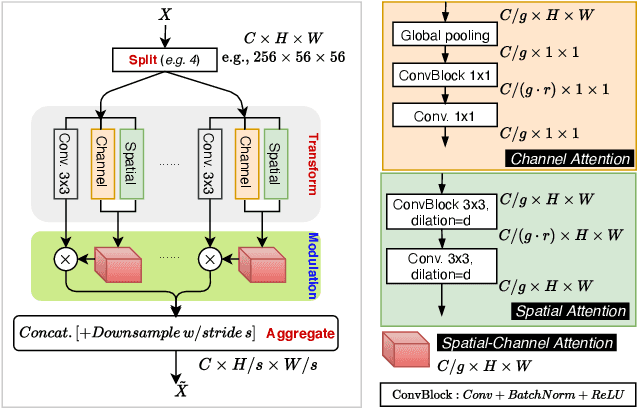

Image synthesis and image recognition have witnessed remarkable progress, but often at the expense of computationally expensive training and inference. Learning lightweight yet expressive deep model has emerged as an important and interesting direction. Inspired by the well-known split-transform-aggregate design heuristic in the Inception building block, this paper proposes a Skip-Layer Inception Module (SLIM) that facilitates efficient learning of image synthesis models, and a same-layer variant (dubbed as SLIM too) as a stronger alternative to the well-known ResNeXts for image recognition. In SLIM, the input feature map is first split into a number of groups (e.g., 4).Each group is then transformed to a latent style vector(via channel-wise attention) and a latent spatial mask (via spatial attention). The learned latent masks and latent style vectors are aggregated to modulate the target feature map. For generative learning, SLIM is built on a recently proposed lightweight Generative Adversarial Networks (i.e., FastGANs) which present a skip-layer excitation(SLE) module. For few-shot image synthesis tasks, the proposed SLIM achieves better performance than the SLE work and other related methods. For one-shot image synthesis tasks, it shows stronger capability of preserving images structures than prior arts such as the SinGANs. For image classification tasks, the proposed SLIM is used as a drop-in replacement for convolution layers in ResNets (resulting in ResNeXt-like models) and achieves better accuracy in theImageNet-1000 dataset, with significantly smaller model complexity
Growing Deep Forests Efficiently with Soft Routing and Learned Connectivity
Dec 29, 2020
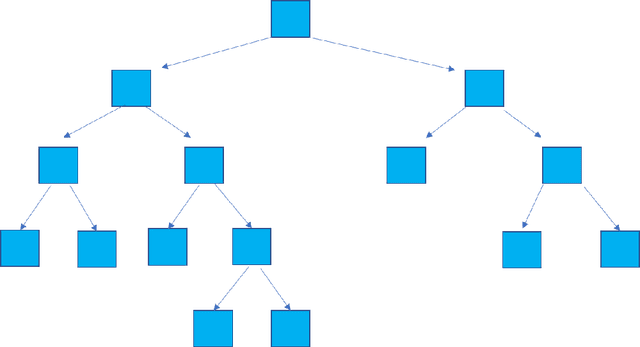

Despite the latest prevailing success of deep neural networks (DNNs), several concerns have been raised against their usage, including the lack of intepretability the gap between DNNs and other well-established machine learning models, and the growingly expensive computational costs. A number of recent works [1], [2], [3] explored the alternative to sequentially stacking decision tree/random forest building blocks in a purely feed-forward way, with no need of back propagation. Since decision trees enjoy inherent reasoning transparency, such deep forest models can also facilitate the understanding of the internaldecision making process. This paper further extends the deep forest idea in several important aspects. Firstly, we employ a probabilistic tree whose nodes make probabilistic routing decisions, a.k.a., soft routing, rather than hard binary decisions.Besides enhancing the flexibility, it also enables non-greedy optimization for each tree. Second, we propose an innovative topology learning strategy: every node in the ree now maintains a new learnable hyperparameter indicating the probability that it will be a leaf node. In that way, the tree will jointly optimize both its parameters and the tree topology during training. Experiments on the MNIST dataset demonstrate that our empowered deep forests can achieve better or comparable performance than [1],[3] , with dramatically reduced model complexity. For example,our model with only 1 layer of 15 trees can perform comparably with the model in [3] with 2 layers of 2000 trees each.
* ICDM workshop 2018
Fractional Skipping: Towards Finer-Grained Dynamic CNN Inference
Jan 03, 2020

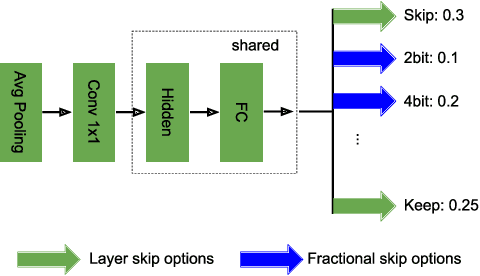
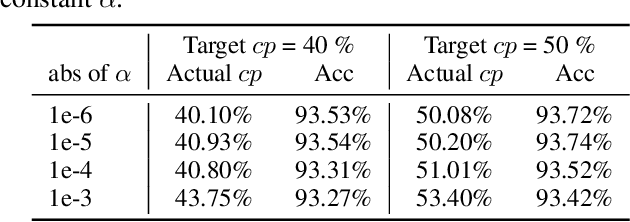
While increasingly deep networks are still in general desired for achieving state-of-the-art performance, for many specific inputs a simpler network might already suffice. Existing works exploited this observation by learning to skip convolutional layers in an input-dependent manner. However, we argue their binary decision scheme, i.e., either fully executing or completely bypassing one layer for a specific input, can be enhanced by introducing finer-grained, "softer" decisions. We therefore propose a Dynamic Fractional Skipping (DFS) framework. The core idea of DFS is to hypothesize layer-wise quantization (to different bitwidths) as intermediate "soft" choices to be made between fully utilizing and skipping a layer. For each input, DFS dynamically assigns a bitwidth to both weights and activations of each layer, where fully executing and skipping could be viewed as two "extremes" (i.e., full bitwidth and zero bitwidth). In this way, DFS can "fractionally" exploit a layer's expressive power during input-adaptive inference, enabling finer-grained accuracy-computational cost trade-offs. It presents a unified view to link input-adaptive layer skipping and input-adaptive hybrid quantization. Extensive experimental results demonstrate the superior tradeoff between computational cost and model expressive power (accuracy) achieved by DFS. More visualizations also indicate a smooth and consistent transition in the DFS behaviors, especially the learned choices between layer skipping and different quantizations when the total computational budgets vary, validating our hypothesis that layer quantization could be viewed as intermediate variants of layer skipping. Our source code and supplementary material are available at \link{https://github.com/Torment123/DFS}.
Dual Dynamic Inference: Enabling More Efficient, Adaptive and Controllable Deep Inference
Jul 17, 2019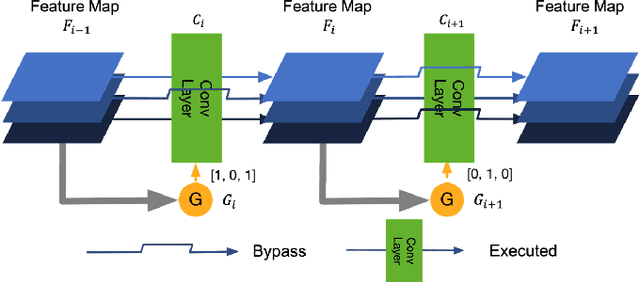
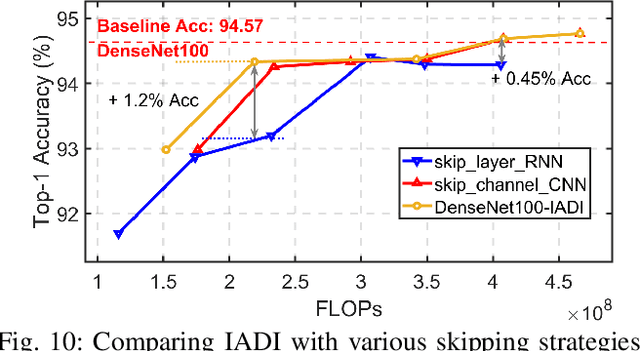
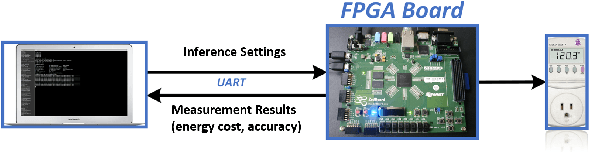
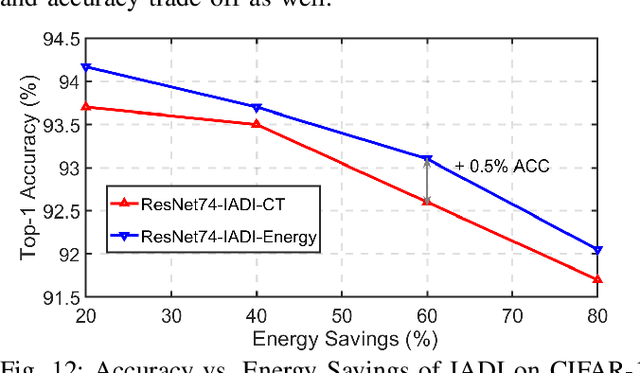
State-of-the-art convolutional neural networks (CNNs) yield record-breaking predictive performance, yet at the cost of high-energy-consumption inference, that prohibits their widely deployments in resource-constrained Internet of Things (IoT) applications. We propose a dual dynamic inference (DDI) framework that highlights the following aspects: 1) we integrate both input-dependent and resource-dependent dynamic inference mechanisms under a unified framework in order to fit the varying IoT resource requirements in practice. DDI is able to both constantly suppress unnecessary costs for easy samples, and to halt inference for all samples to meet hard resource constraints enforced; 2) we propose a flexible multi-grained learning to skip (MGL2S) approach for input-dependent inference which allows simultaneous layer-wise and channel-wise skipping; 3) we extend DDI to complex CNN backbones such as DenseNet and show that DDI can be applied towards optimizing any specific resource goals including inference latency or energy cost. Extensive experiments demonstrate the superior inference accuracy-resource trade-off achieved by DDI, as well as the flexibility to control such trade-offs compared to existing peer methods. Specifically, DDI can achieve up to 4 times computational savings with the same or even higher accuracy as compared to existing competitive baselines.