 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Learning to Optimize: Towards Interpretability and Scalability
Apr 02, 2022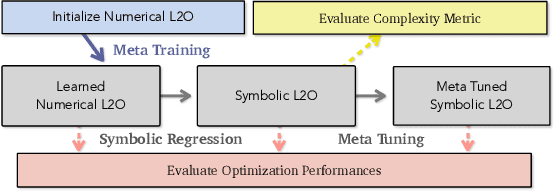


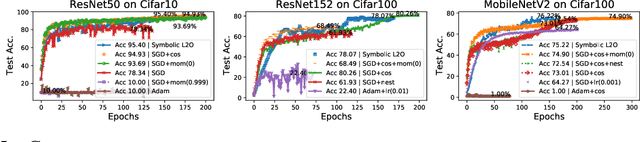
Recent studies on Learning to Optimize (L2O) suggest a promising path to automating and accelerating the optimization procedure for complicated tasks. Existing L2O models parameterize optimization rules by neural networks, and learn those numerical rules via meta-training. However, they face two common pitfalls: (1) scalability: the numerical rules represented by neural networks create extra memory overhead for applying L2O models, and limit their applicability to optimizing larger tasks; (2) interpretability: it is unclear what an L2O model has learned in its black-box optimization rule, nor is it straightforward to compare different L2O models in an explainable way. To avoid both pitfalls, this paper proves the concept that we can "kill two birds by one stone", by introducing the powerful tool of symbolic regression to L2O. In this paper, we establish a holistic symbolic representation and analysis framework for L2O, which yields a series of insights for learnable optimizers. Leveraging our findings, we further propose a lightweight L2O model that can be meta-trained on large-scale problems and outperformed human-designed and tuned optimizers. Our work is set to supply a brand-new perspective to L2O research. Codes are available at: https://github.com/VITA-Group/Symbolic-Learning-To-Optimize.
Scalable Perception-Action-Communication Loops with Convolutional and Graph Neural Networks
Jun 24, 2021In this paper, we present a perception-action-communication loop design using Vision-based Graph Aggregation and Inference (VGAI). This multi-agent decentralized learning-to-control framework maps raw visual observations to agent actions, aided by local communication among neighboring agents. Our framework is implemented by a cascade of a convolutional and a graph neural network (CNN / GNN), addressing agent-level visual perception and feature learning, as well as swarm-level communication, local information aggregation and agent action inference, respectively. By jointly training the CNN and GNN, image features and communication messages are learned in conjunction to better address the specific task. We use imitation learning to train the VGAI controller in an offline phase, relying on a centralized expert controller. This results in a learned VGAI controller that can be deployed in a distributed manner for online execution. Additionally, the controller exhibits good scaling properties, with training in smaller teams and application in larger teams. Through a multi-agent flocking application, we demonstrate that VGAI yields performance comparable to or better than other decentralized controllers, using only the visual input modality and without accessing precise location or motion state information.
Undistillable: Making A Nasty Teacher That CANNOT teach students
May 16, 2021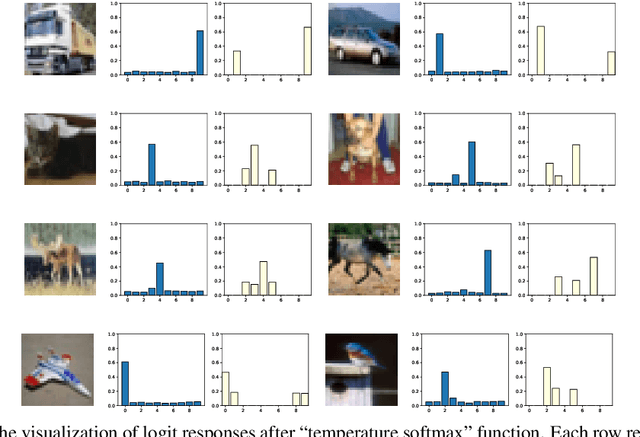
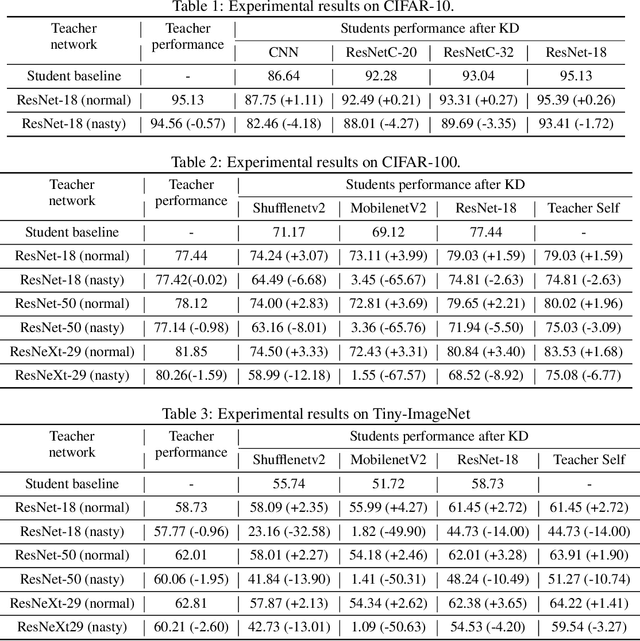
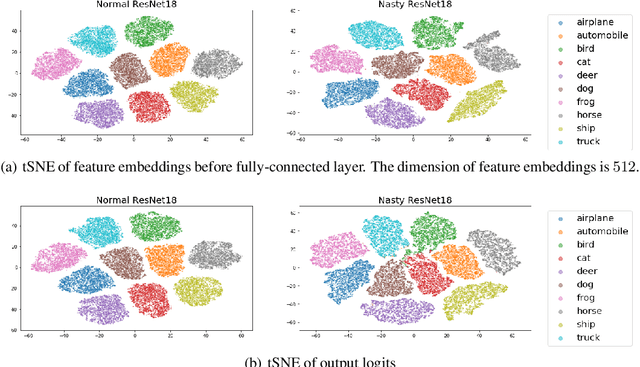
Knowledge Distillation (KD) is a widely used technique to transfer knowledge from pre-trained teacher models to (usually more lightweight) student models. However, in certain situations, this technique is more of a curse than a blessing. For instance, KD poses a potential risk of exposing intellectual properties (IPs): even if a trained machine learning model is released in 'black boxes' (e.g., as executable software or APIs without open-sourcing code), it can still be replicated by KD through imitating input-output behaviors. To prevent this unwanted effect of KD, this paper introduces and investigates a concept called Nasty Teacher: a specially trained teacher network that yields nearly the same performance as a normal one, but would significantly degrade the performance of student models learned by imitating it. We propose a simple yet effective algorithm to build the nasty teacher, called self-undermining knowledge distillation. Specifically, we aim to maximize the difference between the output of the nasty teacher and a normal pre-trained network. Extensive experiments on several datasets demonstrate that our method is effective on both standard KD and data-free KD, providing the desirable KD-immunity to model owners for the first time. We hope our preliminary study can draw more awareness and interest in this new practical problem of both social and legal importance.
* ICLR 2021(Spotlight). Code is available at https://github.com/VITA-Group/Nasty-Teacher
Good Students Play Big Lottery Better
Jan 18, 2021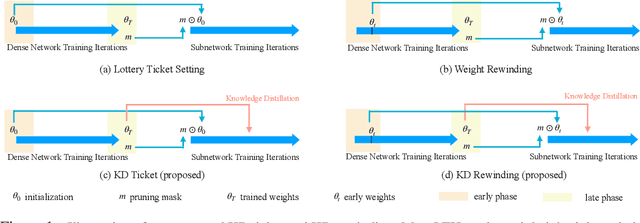

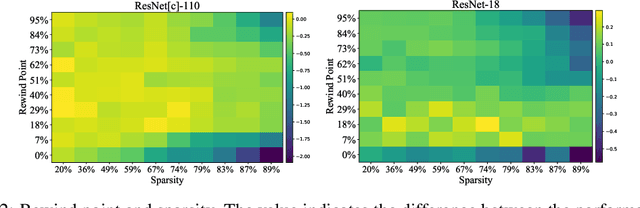
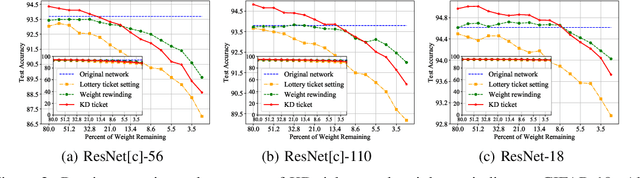
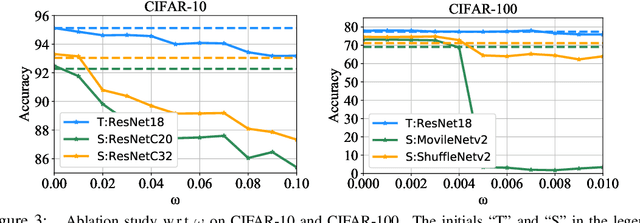
Lottery ticket hypothesis suggests that a dense neural network contains a sparse sub-network that can match the test accuracy of the original dense net when trained in isolation from (the same) random initialization. However, the hypothesis failed to generalize to larger dense networks such as ResNet-50. As a remedy, recent studies demonstrate that a sparse sub-network can still be obtained by using a rewinding technique, which is to re-train it from early-phase training weights or learning rates of the dense model, rather than from random initialization. Is rewinding the only or the best way to scale up lottery tickets? This paper proposes a new, simpler and yet powerful technique for re-training the sub-network, called "Knowledge Distillation ticket" (KD ticket). Rewinding exploits the value of inheriting knowledge from the early training phase to improve lottery tickets in large networks. In comparison, KD ticket addresses a complementary possibility - inheriting useful knowledge from the late training phase of the dense model. It is achieved by leveraging the soft labels generated by the trained dense model to re-train the sub-network, instead of the hard labels. Extensive experiments are conducted using several large deep networks (e.g ResNet-50 and ResNet-110) on CIFAR-10 and ImageNet datasets. Without bells and whistles, when applied by itself, KD ticket performs on par or better than rewinding, while being nearly free of hyperparameters or ad-hoc selection. KD ticket can be further applied together with rewinding, yielding state-of-the-art results for large-scale lottery tickets.
Once-for-All Adversarial Training: In-Situ Tradeoff between Robustness and Accuracy for Free
Nov 10, 2020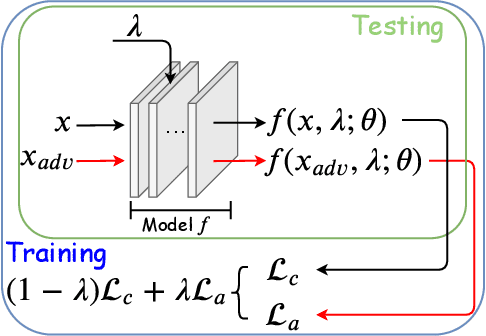
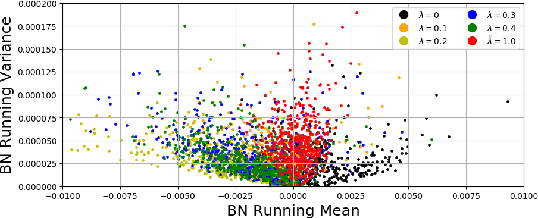
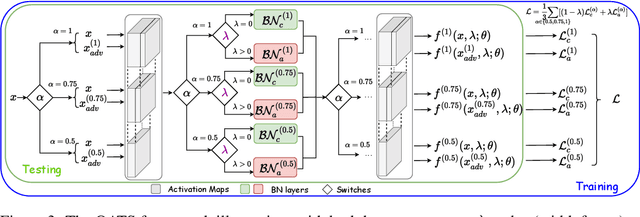
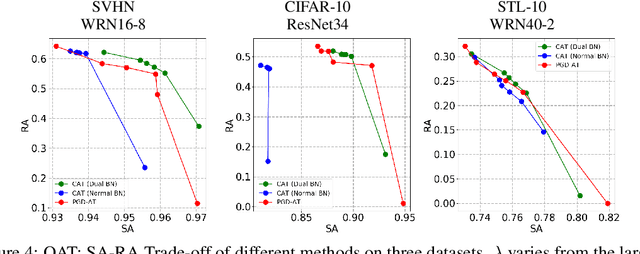
Adversarial training and its many variants substantially improve deep network robustness, yet at the cost of compromising standard accuracy. Moreover, the training process is heavy and hence it becomes impractical to thoroughly explore the trade-off between accuracy and robustness. This paper asks this new question: how to quickly calibrate a trained model in-situ, to examine the achievable trade-offs between its standard and robust accuracies, without (re-)training it many times? Our proposed framework, Once-for-all Adversarial Training (OAT), is built on an innovative model-conditional training framework, with a controlling hyper-parameter as the input. The trained model could be adjusted among different standard and robust accuracies "for free" at testing time. As an important knob, we exploit dual batch normalization to separate standard and adversarial feature statistics, so that they can be learned in one model without degrading performance. We further extend OAT to a Once-for-all Adversarial Training and Slimming (OATS) framework, that allows for the joint trade-off among accuracy, robustness and runtime efficiency. Experiments show that, without any re-training nor ensembling, OAT/OATS achieve similar or even superior performance compared to dedicatedly trained models at various configurations. Our codes and pretrained models are available at: https://github.com/VITA-Group/Once-for-All-Adversarial-Training.
Triple Wins: Boosting Accuracy, Robustness and Efficiency Together by Enabling Input-Adaptive Inference
Feb 25, 2020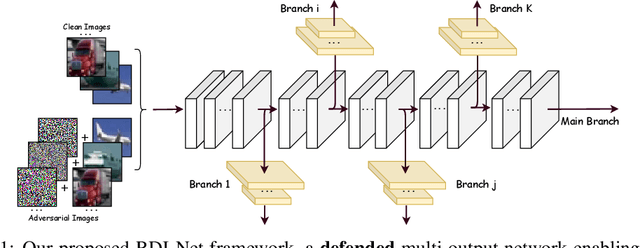

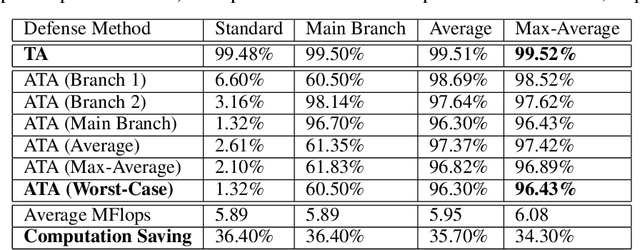
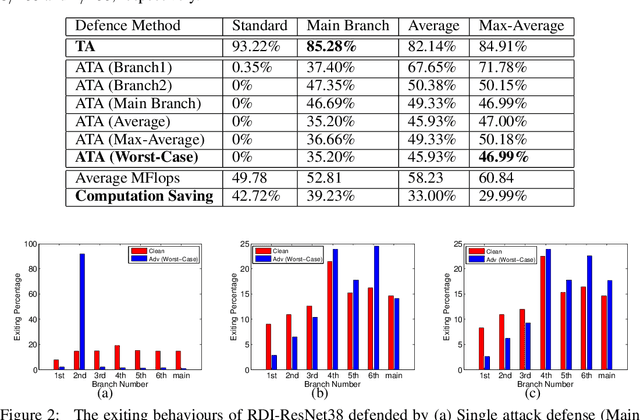
Deep networks were recently suggested to face the odds between accuracy (on clean natural images) and robustness (on adversarially perturbed images) (Tsipras et al., 2019). Such a dilemma is shown to be rooted in the inherently higher sample complexity (Schmidt et al., 2018) and/or model capacity (Nakkiran, 2019), for learning a high-accuracy and robust classifier. In view of that, give a classification task, growing the model capacity appears to help draw a win-win between accuracy and robustness, yet at the expense of model size and latency, therefore posing challenges for resource-constrained applications. Is it possible to co-design model accuracy, robustness and efficiency to achieve their triple wins? This paper studies multi-exit networks associated with input-adaptive efficient inference, showing their strong promise in achieving a "sweet point" in cooptimizing model accuracy, robustness and efficiency. Our proposed solution, dubbed Robust Dynamic Inference Networks (RDI-Nets), allows for each input (either clean or adversarial) to adaptively choose one of the multiple output layers (early branches or the final one) to output its prediction. That multi-loss adaptivity adds new variations and flexibility to adversarial attacks and defenses, on which we present a systematical investigation. We show experimentally that by equipping existing backbones with such robust adaptive inference, the resulting RDI-Nets can achieve better accuracy and robustness, yet with over 30% computational savings, compared to the defended original models.
VGAI: A Vision-Based Decentralized Controller Learning Framework for Robot Swarms
Feb 06, 2020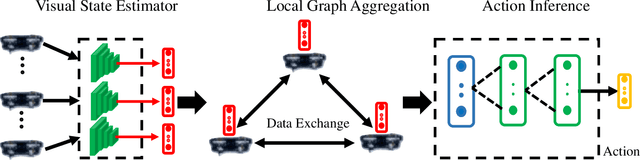
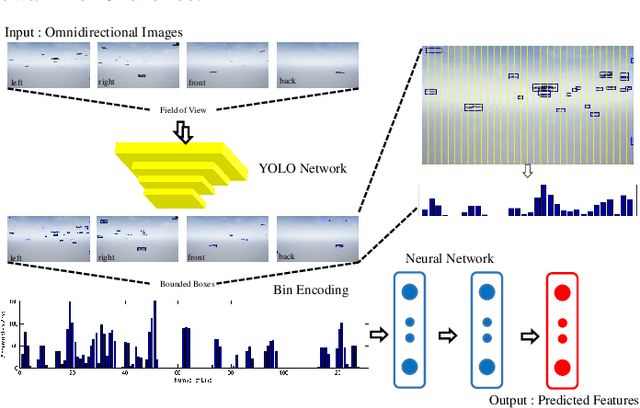
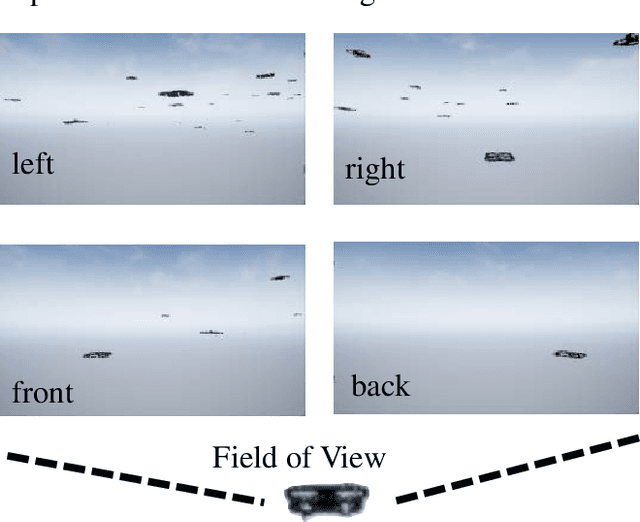
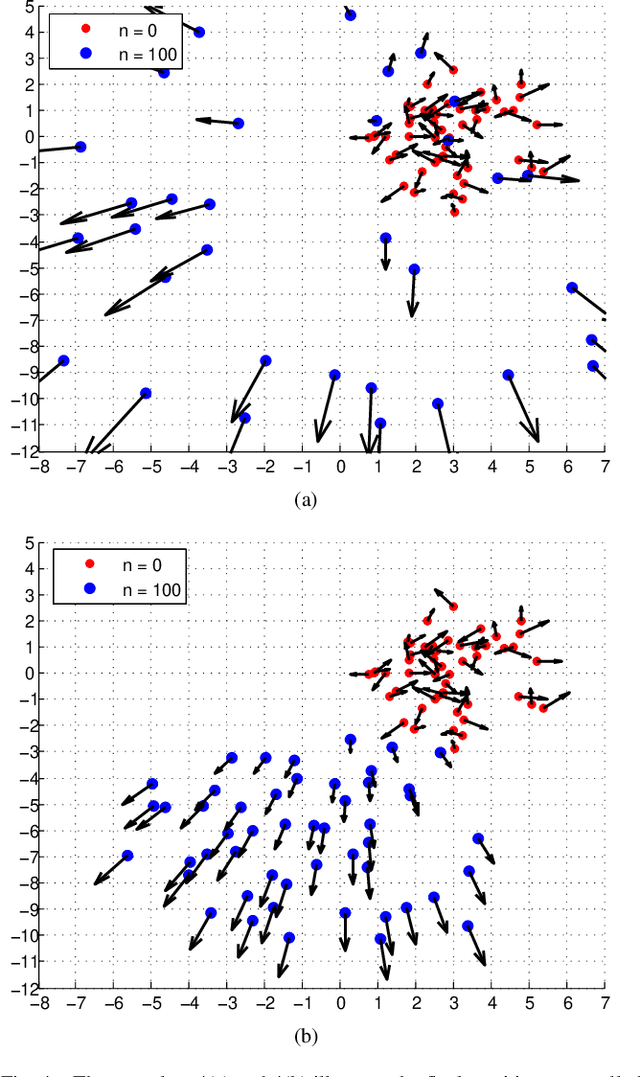
Despite the popularity of decentralized controller learning, very few successes have been demonstrated on learning to control large robot swarms using raw visual observations. To fill in this gap, we present Vision-based Graph Aggregation and Inference (VGAI), a decentralized learning-to-control framework that directly maps raw visual observations to agent actions, aided by sparse local communication among only neighboring agents. Our framework is implemented by an innovative cascade of convolutional neural networks (CNNs) and one graph neural network (GNN), addressing agent-level visual perception and feature learning, as well as swarm-level local information aggregation and agent action inference, respectively. Using the application example of drone flocking, we show that VGAI yields comparable or more competitive performance with other decentralized controllers, and even the centralized controller that learns from global information. Especially, it shows substantial scalability to learn over large swarms (e.g., 50 agents), thanks to the integration between visual perception and local communication.
Dual Dynamic Inference: Enabling More Efficient, Adaptive and Controllable Deep Inference
Jul 17, 2019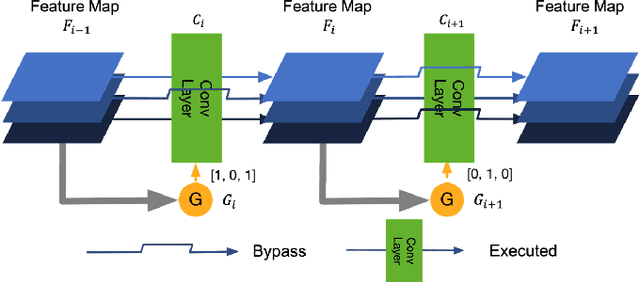
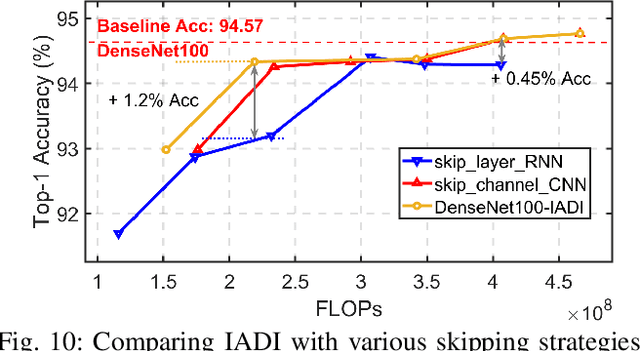
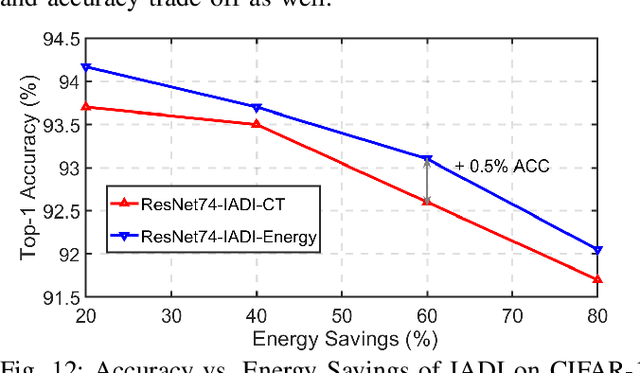
State-of-the-art convolutional neural networks (CNNs) yield record-breaking predictive performance, yet at the cost of high-energy-consumption inference, that prohibits their widely deployments in resource-constrained Internet of Things (IoT) applications. We propose a dual dynamic inference (DDI) framework that highlights the following aspects: 1) we integrate both input-dependent and resource-dependent dynamic inference mechanisms under a unified framework in order to fit the varying IoT resource requirements in practice. DDI is able to both constantly suppress unnecessary costs for easy samples, and to halt inference for all samples to meet hard resource constraints enforced; 2) we propose a flexible multi-grained learning to skip (MGL2S) approach for input-dependent inference which allows simultaneous layer-wise and channel-wise skipping; 3) we extend DDI to complex CNN backbones such as DenseNet and show that DDI can be applied towards optimizing any specific resource goals including inference latency or energy cost. Extensive experiments demonstrate the superior inference accuracy-resource trade-off achieved by DDI, as well as the flexibility to control such trade-offs compared to existing peer methods. Specifically, DDI can achieve up to 4 times computational savings with the same or even higher accuracy as compared to existing competitive baselines.