 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Students Play Big Lottery Better
Paper and Code
Jan 18, 2021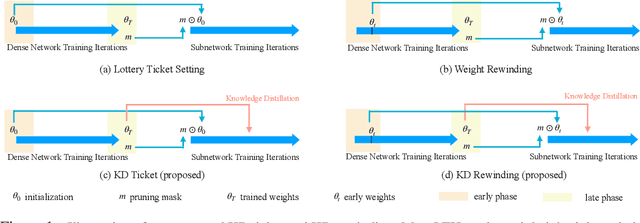

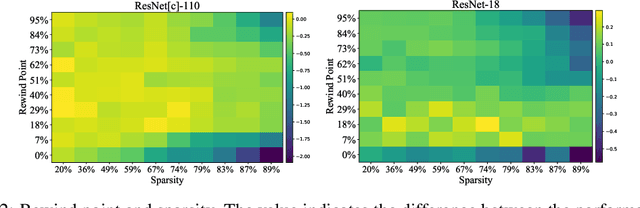
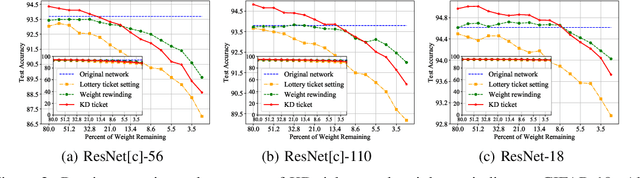
Lottery ticket hypothesis suggests that a dense neural network contains a sparse sub-network that can match the test accuracy of the original dense net when trained in isolation from (the same) random initialization. However, the hypothesis failed to generalize to larger dense networks such as ResNet-50. As a remedy, recent studies demonstrate that a sparse sub-network can still be obtained by using a rewinding technique, which is to re-train it from early-phase training weights or learning rates of the dense model, rather than from random initialization. Is rewinding the only or the best way to scale up lottery tickets? This paper proposes a new, simpler and yet powerful technique for re-training the sub-network, called "Knowledge Distillation ticket" (KD ticket). Rewinding exploits the value of inheriting knowledge from the early training phase to improve lottery tickets in large networks. In comparison, KD ticket addresses a complementary possibility - inheriting useful knowledge from the late training phase of the dense model. It is achieved by leveraging the soft labels generated by the trained dense model to re-train the sub-network, instead of the hard labels. Extensive experiments are conducted using several large deep networks (e.g ResNet-50 and ResNet-110) on CIFAR-10 and ImageNet datasets. Without bells and whistles, when applied by itself, KD ticket performs on par or better than rewinding, while being nearly free of hyperparameters or ad-hoc selection. KD ticket can be further applied together with rewinding, yielding state-of-the-art results for large-scale lottery tickets.