 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnce-for-All Adversarial Training: In-Situ Tradeoff between Robustness and Accuracy for Free
Nov 10, 2020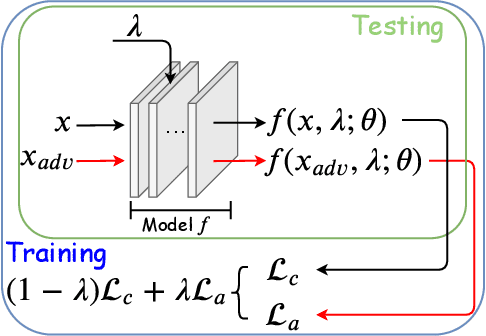
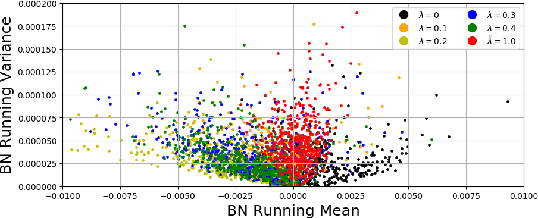
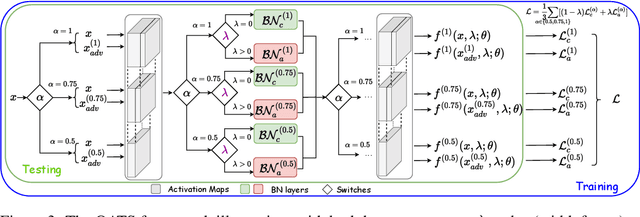
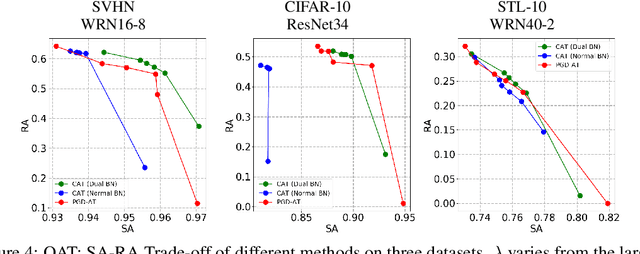
Adversarial training and its many variants substantially improve deep network robustness, yet at the cost of compromising standard accuracy. Moreover, the training process is heavy and hence it becomes impractical to thoroughly explore the trade-off between accuracy and robustness. This paper asks this new question: how to quickly calibrate a trained model in-situ, to examine the achievable trade-offs between its standard and robust accuracies, without (re-)training it many times? Our proposed framework, Once-for-all Adversarial Training (OAT), is built on an innovative model-conditional training framework, with a controlling hyper-parameter as the input. The trained model could be adjusted among different standard and robust accuracies "for free" at testing time. As an important knob, we exploit dual batch normalization to separate standard and adversarial feature statistics, so that they can be learned in one model without degrading performance. We further extend OAT to a Once-for-all Adversarial Training and Slimming (OATS) framework, that allows for the joint trade-off among accuracy, robustness and runtime efficiency. Experiments show that, without any re-training nor ensembling, OAT/OATS achieve similar or even superior performance compared to dedicatedly trained models at various configurations. Our codes and pretrained models are available at: https://github.com/VITA-Group/Once-for-All-Adversarial-Training.
GAN Slimming: All-in-One GAN Compression by A Unified Optimization Framework
Aug 25, 2020

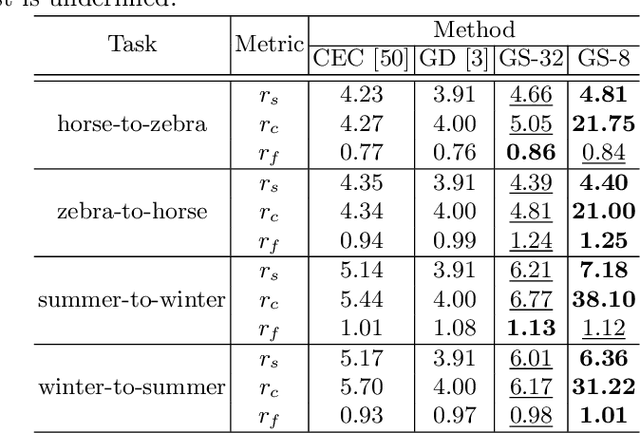

Generative adversarial networks (GANs) have gained increasing popularity in various computer vision applications, and recently start to be deployed to resource-constrained mobile devices. Similar to other deep models, state-of-the-art GANs suffer from high parameter complexities. That has recently motivated the exploration of compressing GANs (usually generators). Compared to the vast literature and prevailing success in compressing deep classifiers, the study of GAN compression remains in its infancy, so far leveraging individual compression techniques instead of more sophisticated combinations. We observe that due to the notorious instability of training GANs, heuristically stacking different compression techniques will result in unsatisfactory results. To this end, we propose the first unified optimization framework combining multiple compression means for GAN compression, dubbed GAN Slimming (GS). GS seamlessly integrates three mainstream compression techniques: model distillation, channel pruning and quantization, together with the GAN minimax objective, into one unified optimization form, that can be efficiently optimized from end to end. Without bells and whistles, GS largely outperforms existing options in compressing image-to-image translation GANs. Specifically, we apply GS to compress CartoonGAN, a state-of-the-art style transfer network, by up to 47 times, with minimal visual quality degradation. Codes and pre-trained models can be found at https://github.com/TAMU-VITA/GAN-Slimming.
ATZSL: Defensive Zero-Shot Recognition in the Presence of Adversaries
Oct 24, 2019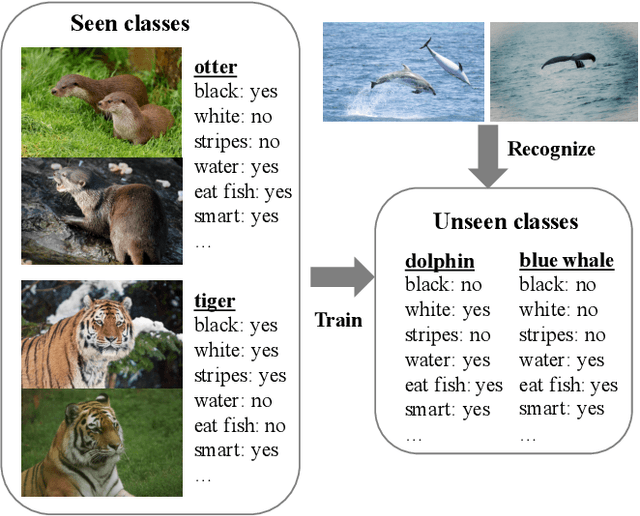
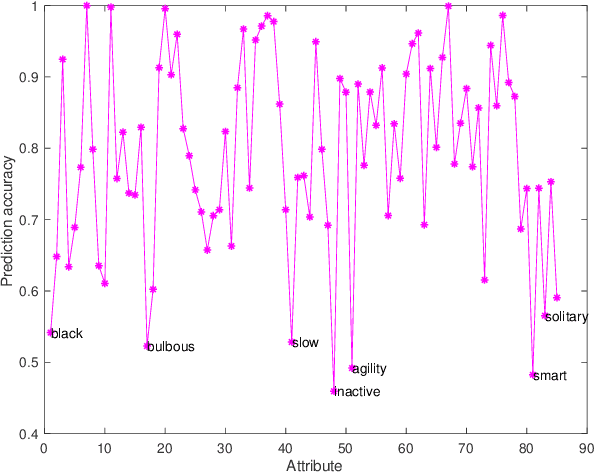
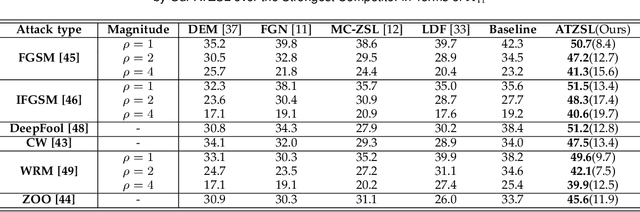
Zero-shot learning (ZSL) has received extensive attention recently especially in areas of fine-grained object recognition, retrieval, and image captioning. Due to the complete lack of training samples and high requirement of defense transferability, the ZSL model learned is particularly vulnerable against adversarial attacks. Recent work also showed adversarially robust generalization requires more data. This may significantly affect the robustness of ZSL. However, very few efforts have been devoted towards this direction. In this paper, we take an initial attempt, and propose a generic formulation to provide a systematical solution (named ATZSL) for learning a robust ZSL model. It is capable of achieving better generalization on various adversarial objects recognition while only losing a negligible performance on clean images for unseen classes, by casting ZSL into a min-max optimization problem. To address it, we design a defensive relation prediction network, which can bridge the seen and unseen class domains via attributes to generalize prediction and defense strategy. Additionally, our framework can be extended to deal with the poisoned scenario of unseen class attributes. An extensive group of experiments are then presented, demonstrating that ATZSL obtains remarkably more favorable trade-off between model transferability and robustness, over currently available alternatives under various settings.
Hierarchical Prototype Learning for Zero-Shot Recognition
Oct 24, 2019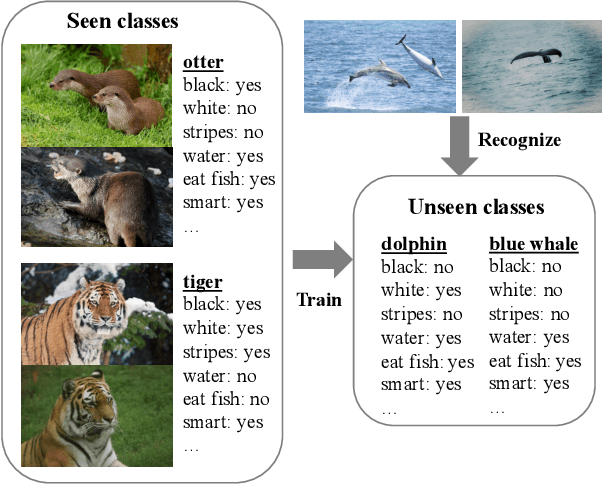

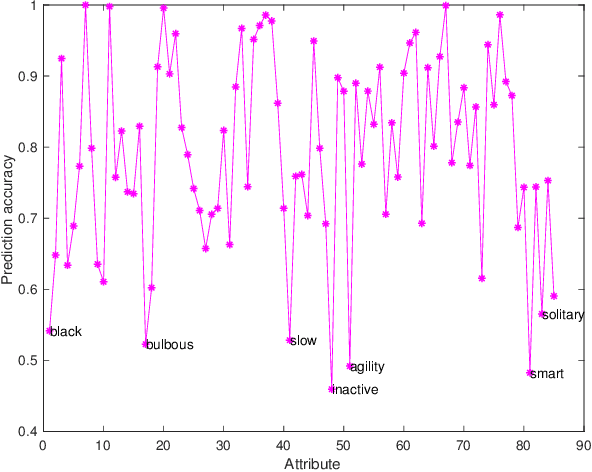
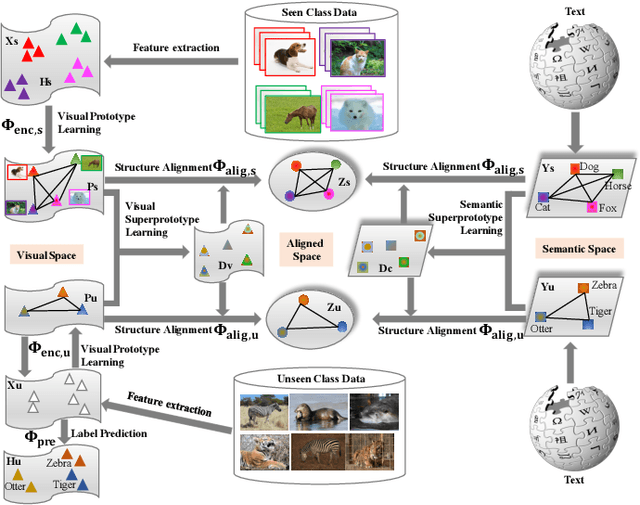
Zero-Shot Learning (ZSL) has received extensive attention and successes in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. Key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary semantic prototypes (e.g., word or attribute vectors). However, the popularly learned projection functions in previous works cannot generalize well due to non-visual components included in semantic prototypes. Besides, the incompleteness of provided prototypes and captured images has less been considered by the state-of-the-art approaches in ZSL. In this paper, we propose a hierarchical prototype learning formulation to provide a systematical solution (named HPL) for zero-shot recognition. Specifically, HPL is able to obtain discriminability on both seen and unseen class domains by learning visual prototypes respectively under the transductive setting. To narrow the gap of two domains, we further learn the interpretable super-prototypes in both visual and semantic spaces. Meanwhile, the two spaces are further bridged by maximizing their structural consistency. This not only facilitates the representativeness of visual prototypes, but also alleviates the loss of information of semantic prototypes. An extensive group of experiments are then carefully designed and presented, demonstrating that HPL obtains remarkably more favorable efficiency and effectiveness, over currently available alternatives under various settings.
Learning Sparsity and Quantization Jointly and Automatically for Neural Network Compression via Constrained Optimization
Oct 17, 2019
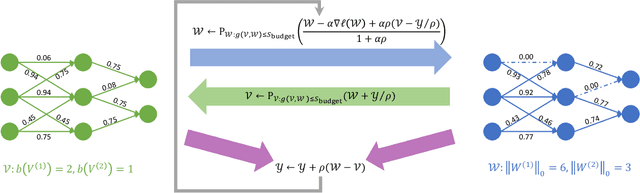
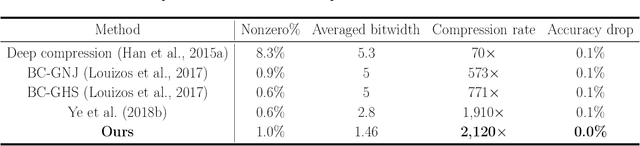

Deep Neural Networks (DNNs) are widely applied in a wide range of usecases. There is an increased demand for deploying DNNs on devices that do not have abundant resources such as memory and computation units. Recently, network compression through a variety of techniques such as pruning and quantization have been proposed to reduce the resource requirement. A key parameter that all existing compression techniques are sensitive to is the compression ratio (e.g., pruning sparsity, quantization bitwidth) of each layer. Traditional solutions treat the compression ratios of each layer as hyper-parameters, and tune them using human heuristic. Recent researchers start using black-box hyper-parameter optimizations, but they will introduce new hyper-parameters and have efficiency issue. In this paper, we propose a framework to jointly prune and quantize the DNNs automatically according to a target model size without using any hyper-parameters to manually set the compression ratio for each layer. In the experiments, we show that our framework can compress the weights data of ResNet-50 to be 836x smaller without accuracy loss on CIFAR-10, and compress AlexNet to be 205x smaller without accuracy loss on ImageNet classification.
PINE: Universal Deep Embedding for Graph Nodes via Partial Permutation Invariant Set Functions
Sep 25, 2019
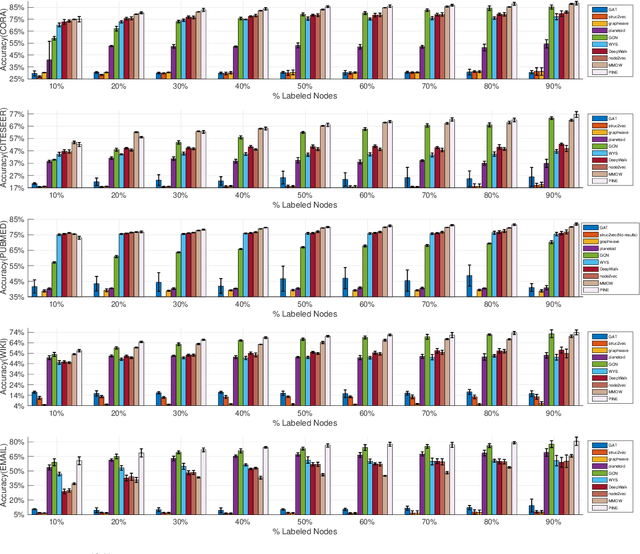
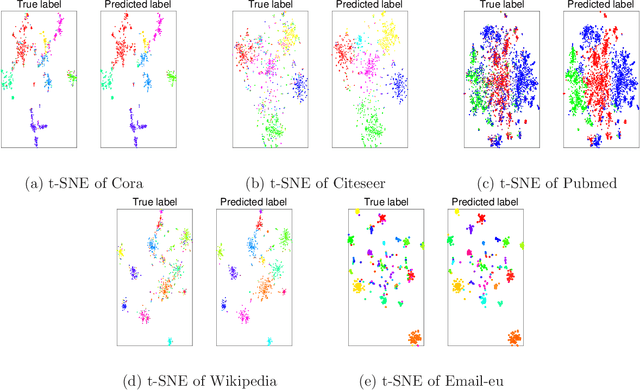

Graph node embedding aims at learning a vector representation for all nodes given a graph. It is a central problem in many machine learning tasks (e.g., node classification, recommendation, community detection). The key problem in graph node embedding lies in how to define the dependence to neighbors. Existing approaches specify (either explicitly or implicitly) certain dependencies on neighbors, which may lead to loss of subtle but important structural information within the graph and other dependencies among neighbors. This intrigues us to ask the question: can we design a model to give the maximal flexibility of dependencies to each node's neighborhood. In this paper, we propose a novel graph node embedding (named PINE) via a novel notion of partial permutation invariant set function, to capture any possible dependence. Our method 1) can learn an arbitrary form of the representation function from the neighborhood, withour losing any potential dependence structures, and 2) is applicable to both homogeneous and heterogeneous graph embedding, the latter of which is challenged by the diversity of node types. Furthermore, we provide theoretical guarantee for the representation capability of our method for general homogeneous and heterogeneous graphs. Empirical evaluation results on benchmark data sets show that our proposed PINE method outperforms the state-of-the-art approaches on producing node vectors for various learning tasks of both homogeneous and heterogeneous graphs.
Adversarially Trained Model Compression: When Robustness Meets Efficiency
Feb 10, 2019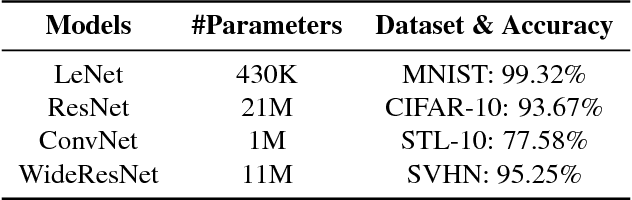
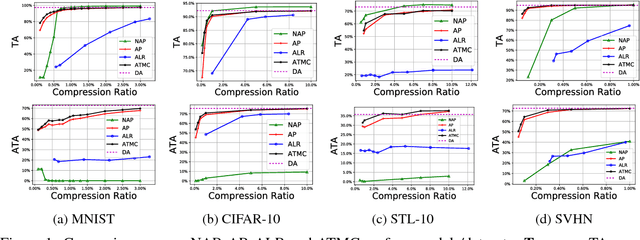
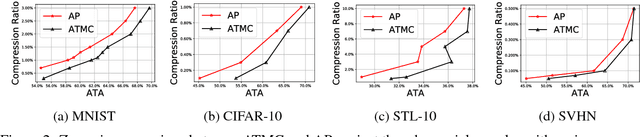
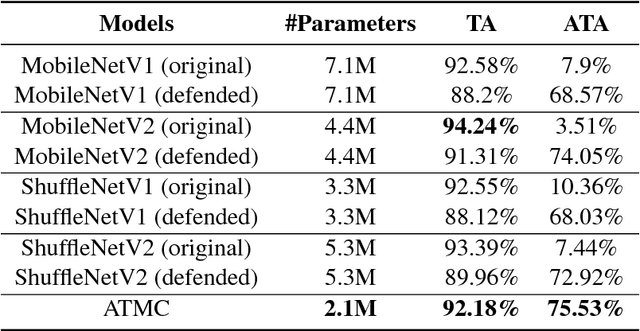
The robustness of deep models to adversarial attacks has gained significant attention in recent years, so has the model compactness and efficiency: yet the two have been mostly studied separately, with few relationships drawn between each other. This paper is concerned with: how can we combine the best of both worlds, obtaining a robust and compact network? The answer is not as straightforward as it may seem, since the two goals of model robustness and compactness may contradict from time to time. We formally study this new question, by proposing a novel Adversarially Trained Model Compression (ATMC) framework. A unified constrained optimization formulation is designed, with an efficient algorithm developed. An extensive group of experiments are then carefully designed and presented, demonstrating that ATMC obtains remarkably more favorable trade-off among model size, accuracy and robustness, over currently available alternatives in various settings.
GESF: A Universal Discriminative Mapping Mechanism for Graph Representation Learning
Jun 05, 2018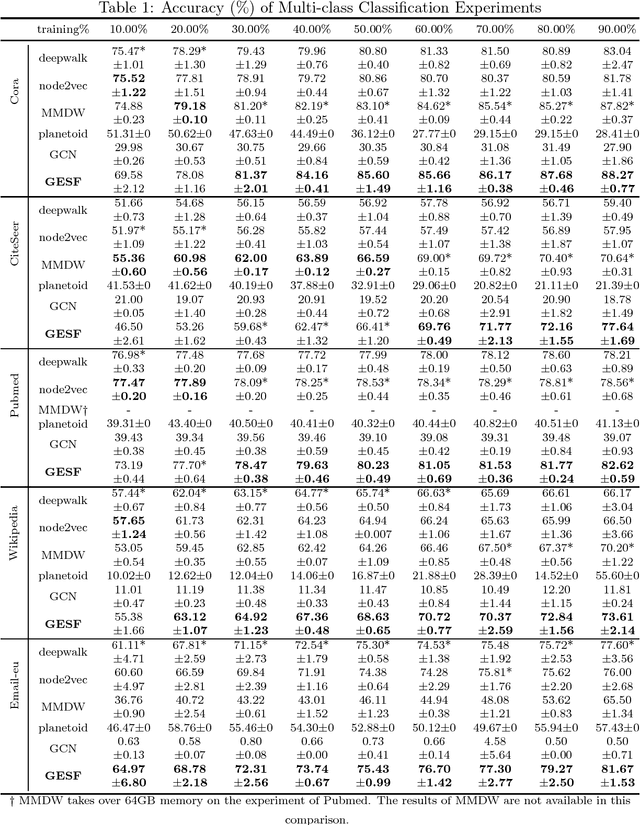
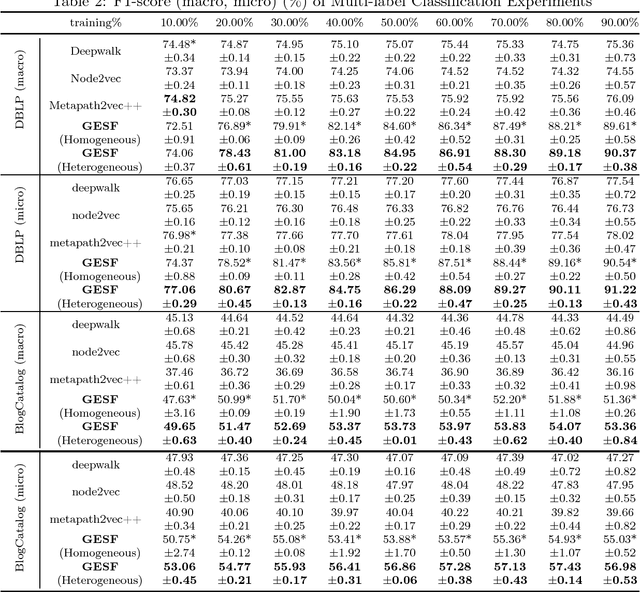
Graph embedding is a central problem in social network analysis and many other applications, aiming to learn the vector representation for each node. While most existing approaches need to specify the neighborhood and the dependence form to the neighborhood, which may significantly degrades the flexibility of representation, we propose a novel graph node embedding method (namely GESF) via the set function technique. Our method can 1) learn an arbitrary form of representation function from neighborhood, 2) automatically decide the significance of neighbors at different distances, and 3) be applied to heterogeneous graph embedding, which may contain multiple types of nodes. Theoretical guarantee for the representation capability of our method has been proved for general homogeneous and heterogeneous graphs and evaluation results on benchmark data sets show that the proposed GESF outperforms the state-of-the-art approaches on producing node vectors for classification tasks.
On The Projection Operator to A Three-view Cardinality Constrained Set
Jun 14, 2017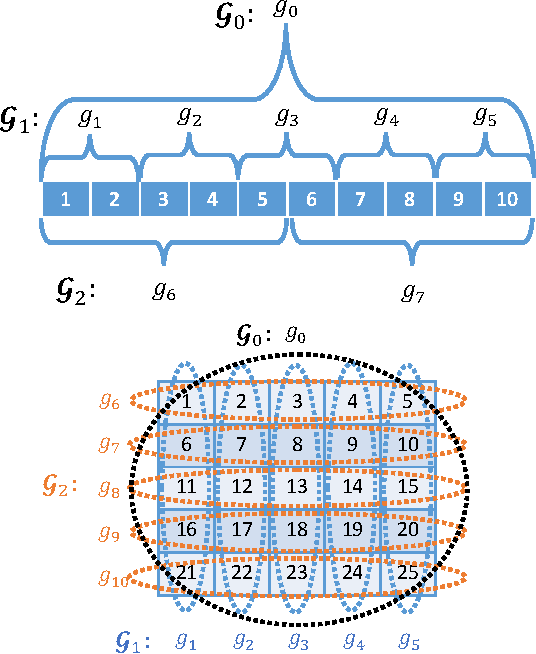

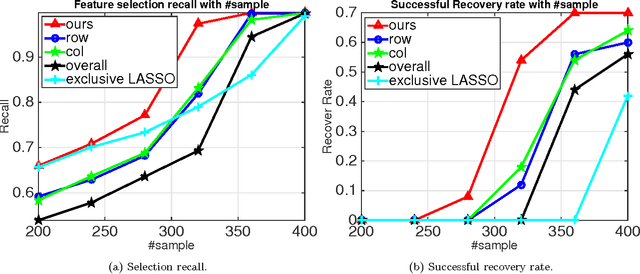
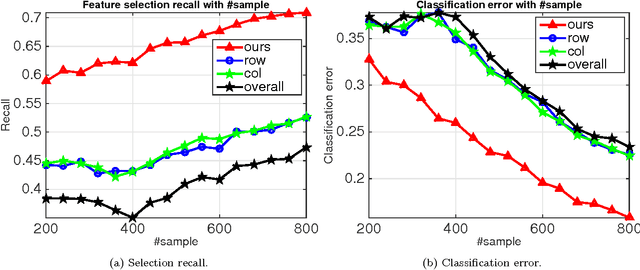
The cardinality constraint is an intrinsic way to restrict the solution structure in many domains, for example, sparse learning, feature selection, and compressed sensing. To solve a cardinality constrained problem, the key challenge is to solve the projection onto the cardinality constraint set, which is NP-hard in general when there exist multiple overlapped cardinality constraints. In this paper, we consider the scenario where the overlapped cardinality constraints satisfy a Three-view Cardinality Structure (TVCS), which reflects the natural restriction in many applications, such as identification of gene regulatory networks and task-worker assignment problem. We cast the projection into a linear programming, and show that for TVCS, the vertex solution of this linear programming is the solution for the original projection problem. We further prove that such solution can be found with the complexity proportional to the number of variables and constraints. We finally use synthetic experiments and two interesting applications in bioinformatics and crowdsourcing to validate the proposed TVCS model and method.