 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Images Speak Louder than Words? Investigating the Effect of Textual Misinformation in VLMs
Jan 27, 2026Vision-Language Models (VLMs) have shown strong multimodal reasoning capabilities on Visual-Question-Answering (VQA) benchmarks. However, their robustness against textual misinformation remains under-explored. While existing research has studied the effect of misinformation in text-only domains, it is not clear how VLMs arbitrate between contradictory information from different modalities. To bridge the gap, we first propose the CONTEXT-VQA (i.e., Conflicting Text) dataset, consisting of image-question pairs together with systematically generated persuasive prompts that deliberately conflict with visual evidence. Then, a thorough evaluation framework is designed and executed to benchmark the susceptibility of various models to these conflicting multimodal inputs. Comprehensive experiments over 11 state-of-the-art VLMs reveal that these models are indeed vulnerable to misleading textual prompts, often overriding clear visual evidence in favor of the conflicting text, and show an average performance drop of over 48.2% after only one round of persuasive conversation. Our findings highlight a critical limitation in current VLMs and underscore the need for improved robustness against textual manipulation.
From Indoor to Open World: Revealing the Spatial Reasoning Gap in MLLMs
Dec 22, 2025

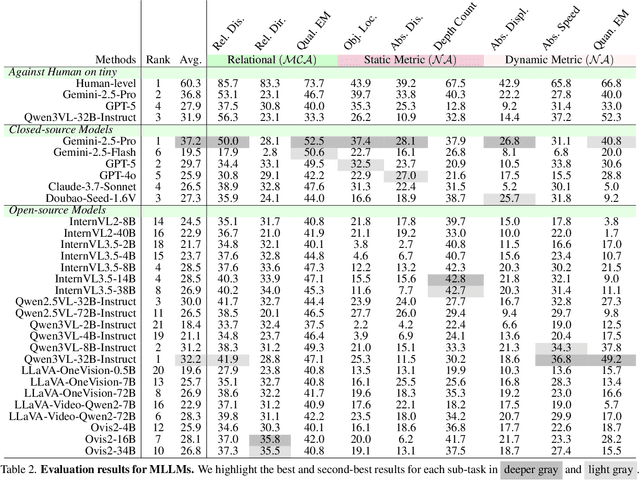
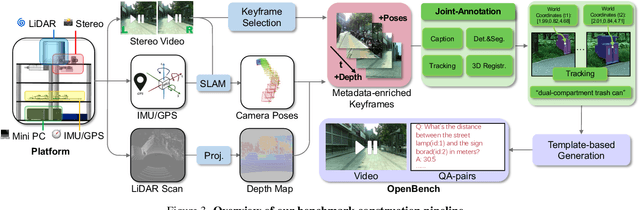
While Multimodal Large Language Models (MLLMs) have achieved impressive performance on semantic tasks, their spatial intelligence--crucial for robust and grounded AI systems--remains underdeveloped. Existing benchmarks fall short of diagnosing this limitation: they either focus on overly simplified qualitative reasoning or rely on domain-specific indoor data, constrained by the lack of outdoor datasets with verifiable metric ground truth. To bridge this gap, we introduce a large-scale benchmark built from pedestrian-perspective videos captured with synchronized stereo cameras, LiDAR, and IMU/GPS sensors. This dataset provides metrically precise 3D information, enabling the automatic generation of spatial reasoning questions that span a hierarchical spectrum--from qualitative relational reasoning to quantitative metric and kinematic understanding. Evaluations reveal that the performance gains observed in structured indoor benchmarks vanish in open-world settings. Further analysis using synthetic abnormal scenes and blinding tests confirms that current MLLMs depend heavily on linguistic priors instead of grounded visual reasoning. Our benchmark thus provides a principled platform for diagnosing these limitations and advancing physically grounded spatial intelligence.
PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
Sep 04, 2025Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
Param$Δ$ for Direct Weight Mixing: Post-Train Large Language Model at Zero Cost
Apr 23, 2025The post-training phase of large language models is essential for enhancing capabilities such as instruction-following, reasoning, and alignment with human preferences. However, it demands extensive high-quality data and poses risks like overfitting, alongside significant computational costs due to repeated post-training and evaluation after each base model update. This paper introduces $Param\Delta$, a novel method that streamlines post-training by transferring knowledge from an existing post-trained model to a newly updated base model with ZERO additional training. By computing the difference between post-trained model weights ($\Theta_\text{post}$) and base model weights ($\Theta_\text{base}$), and adding this to the updated base model ($\Theta'_\text{base}$), we define $Param\Delta$ Model as: $\Theta_{\text{Param}\Delta} = \Theta_\text{post} - \Theta_\text{base} + \Theta'_\text{base}$. This approach surprisingly equips the new base model with post-trained capabilities, achieving performance comparable to direct post-training. We did analysis on LLama3, Llama3.1, Qwen, and DeepSeek-distilled models. Results indicate $Param\Delta$ Model effectively replicates traditional post-training. For example, the $Param\Delta$ Model obtained from 70B Llama3-inst, Llama3-base, Llama3.1-base models attains approximately 95\% of Llama3.1-inst model's performance on average. $Param\Delta$ brings a new perspective on how to fully leverage models in the open-weight community, where checkpoints for base and instruct models are readily available and frequently updated, by providing a cost-free framework to accelerate the iterative cycle of model development.
* Published as a conference paper at ICLR 2025
Vision Calorimeter for Anti-neutron Reconstruction: A Baseline
Aug 20, 2024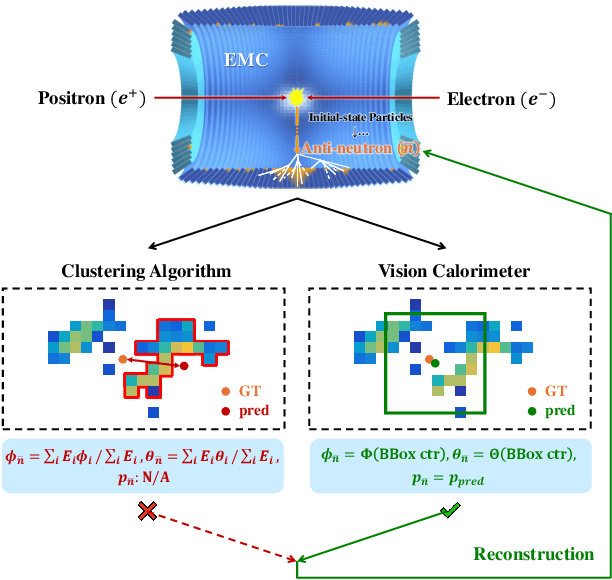



In high-energy physics, anti-neutrons ($\bar{n}$) are fundamental particles that frequently appear as final-state particles, and the reconstruction of their kinematic properties provides an important probe for understanding the governing principles. However, this confronts significant challenges instrumentally with the electromagnetic calorimeter (EMC), a typical experimental sensor but recovering the information of incident $\bar{n}$ insufficiently. In this study, we introduce Vision Calorimeter (ViC), a baseline method for anti-neutron reconstruction that leverages deep learning detectors to analyze the implicit relationships between EMC responses and incident $\bar{n}$ characteristics. Our motivation lies in that energy distributions of $\bar{n}$ samples deposited in the EMC cell arrays embody rich contextual information. Converted to 2-D images, such contextual energy distributions can be used to predict the status of $\bar{n}$ ($i.e.$, incident position and momentum) through a deep learning detector along with pseudo bounding boxes and a specified training objective. Experimental results demonstrate that ViC substantially outperforms the conventional reconstruction approach, reducing the prediction error of incident position by 42.81% (from 17.31$^{\circ}$ to 9.90$^{\circ}$). More importantly, this study for the first time realizes the measurement of incident $\bar{n}$ momentum, underscoring the potential of deep learning detectors for particle reconstruction. Code is available at https://github.com/yuhongtian17/ViC.
TraDiffusion: Trajectory-Based Training-Free Image Generation
Aug 19, 2024



In this work, we propose a training-free, trajectory-based controllable T2I approach, termed TraDiffusion. This novel method allows users to effortlessly guide image generation via mouse trajectories. To achieve precise control, we design a distance awareness energy function to effectively guide latent variables, ensuring that the focus of generation is within the areas defined by the trajectory. The energy function encompasses a control function to draw the generation closer to the specified trajectory and a movement function to diminish activity in areas distant from the trajectory. Through extensive experiments and qualitative assessments on the COCO dataset, the results reveal that TraDiffusion facilitates simpler, more natural image control. Moreover, it showcases the ability to manipulate salient regions, attributes, and relationships within the generated images, alongside visual input based on arbitrary or enhanced trajectories.
ControlMLLM: Training-Free Visual Prompt Learning for Multimodal Large Language Models
Jul 31, 2024In this work, we propose a training-free method to inject visual referring into Multimodal Large Language Models (MLLMs) through learnable visual token optimization. We observe the relationship between text prompt tokens and visual tokens in MLLMs, where attention layers model the connection between them. Our approach involves adjusting visual tokens from the MLP output during inference, controlling which text prompt tokens attend to which visual tokens. We optimize a learnable visual token based on an energy function, enhancing the strength of referential regions in the attention map. This enables detailed region description and reasoning without the need for substantial training costs or model retraining. Our method offers a promising direction for integrating referential abilities into MLLMs. Our method support referring with box, mask, scribble and point. The results demonstrate that our method exhibits controllability and interpretability.
Evaluating and Analyzing Relationship Hallucinations in LVLMs
Jun 24, 2024



The issue of hallucinations is a prevalent concern in existing Large Vision-Language Models (LVLMs). Previous efforts have primarily focused on investigating object hallucinations, which can be easily alleviated by introducing object detectors. However, these efforts neglect hallucinations in inter-object relationships, which is essential for visual comprehension. In this work, we introduce R-Bench, a novel benchmark for evaluating Vision Relationship Hallucination. R-Bench features image-level questions that focus on the existence of relationships and instance-level questions that assess local visual comprehension. We identify three types of relationship co-occurrences that lead to hallucinations: relationship-relationship, subject-relationship, and relationship-object. The visual instruction tuning dataset's long-tail distribution significantly impacts LVLMs' understanding of visual relationships. Furthermore, our analysis reveals that current LVLMs tend to disregard visual content and overly rely on the common sense knowledge of Large Language Models. They also struggle with reasoning about spatial relationships based on contextual information.