 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking Human Process: Text Representation via Latent Semantic Clustering for Classification
Jun 18, 2019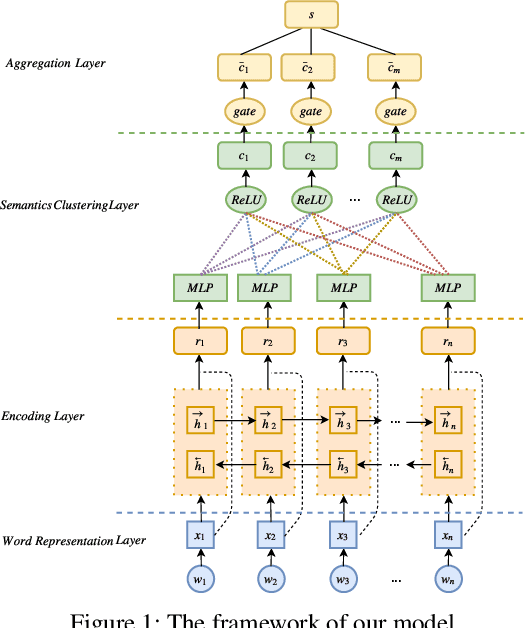
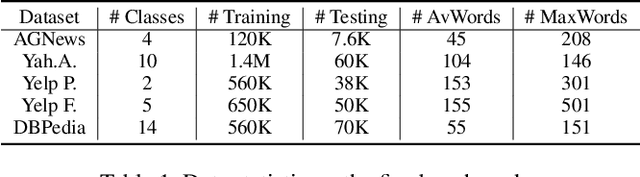
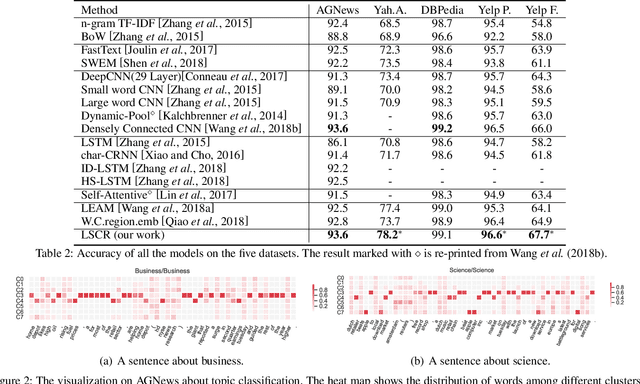
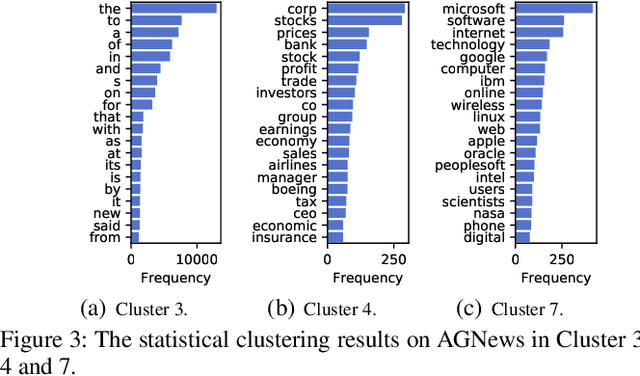
Considering that words with different characteristic in the text have different importance for classification, grouping them together separately can strengthen the semantic expression of each part. Thus we propose a new text representation scheme by clustering words according to their latent semantics and composing them together to get a set of cluster vectors, which are then concatenated as the final text representation. Evaluation on five classification benchmarks proves the effectiveness of our method. We further conduct visualization analysis showing statistical clustering results and verifying the validity of our motivation.
Style Transfer in Text: Exploration and Evaluation
Nov 27, 2017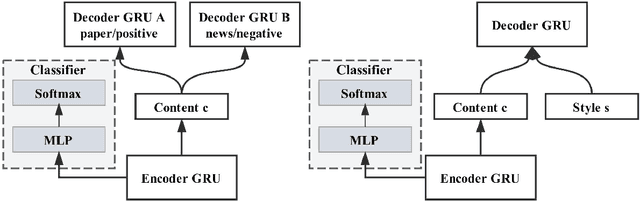
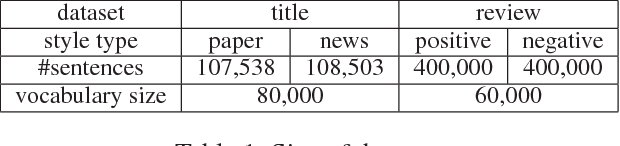
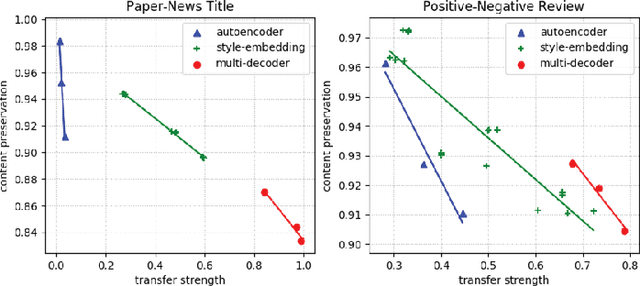

Style transfer is an important problem in natural language processing (NLP). However, the progress in language style transfer is lagged behind other domains, such as computer vision, mainly because of the lack of parallel data and principle evaluation metrics. In this paper, we propose to learn style transfer with non-parallel data. We explore two models to achieve this goal, and the key idea behind the proposed models is to learn separate content representations and style representations using adversarial networks. We also propose novel evaluation metrics which measure two aspects of style transfer: transfer strength and content preservation. We access our models and the evaluation metrics on two tasks: paper-news title transfer, and positive-negative review transfer. Results show that the proposed content preservation metric is highly correlate to human judgments, and the proposed models are able to generate sentences with higher style transfer strength and similar content preservation score comparing to auto-encoder.