 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-bag Matching with Mutual Coverage for Information-seeking Conversations in E-commerce
Nov 07, 2019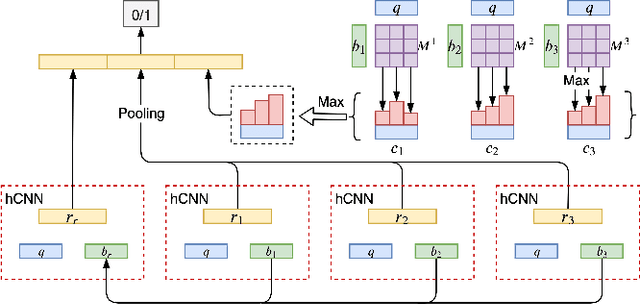
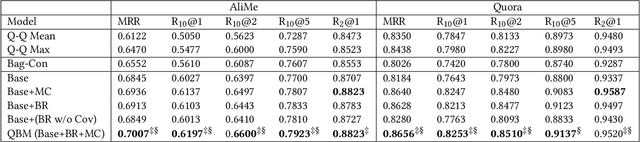
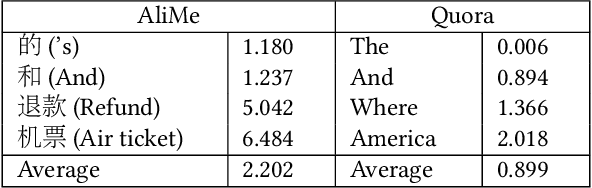
Information-seeking conversation system aims at satisfying the information needs of users through conversations. Text matching between a user query and a pre-collected question is an important part of the information-seeking conversation in E-commerce. In the practical scenario, a sort of questions always correspond to a same answer. Naturally, these questions can form a bag. Learning the matching between user query and bag directly may improve the conversation performance, denoted as query-bag matching. Inspired by such opinion, we propose a query-bag matching model which mainly utilizes the mutual coverage between query and bag and measures the degree of the content in the query mentioned by the bag, and vice verse. In addition, the learned bag representation in word level helps find the main points of a bag in a fine grade and promotes the query-bag matching performance. Experiments on two datasets show the effectiveness of our model.
Multilingual Dialogue Generation with Shared-Private Memory
Oct 06, 2019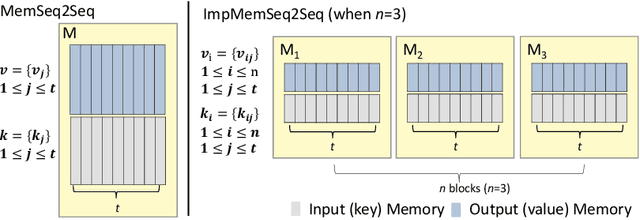


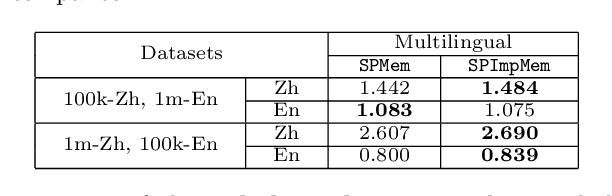
Existing dialog systems are all monolingual, where features shared among different languages are rarely explored. In this paper, we introduce a novel multilingual dialogue system. Specifically, we augment the sequence to sequence framework with improved shared-private memory. The shared memory learns common features among different languages and facilitates a cross-lingual transfer to boost dialogue systems, while the private memory is owned by each separate language to capture its unique feature. Experiments conducted on Chinese and English conversation corpora of different scales show that our proposed architecture outperforms the individually learned model with the help of the other language, where the improvement is particularly distinct when the training data is limited.
Semi-supervised Text Style Transfer: Cross Projection in Latent Space
Sep 25, 2019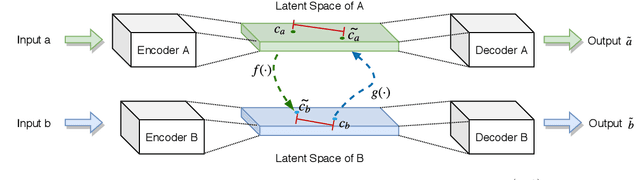
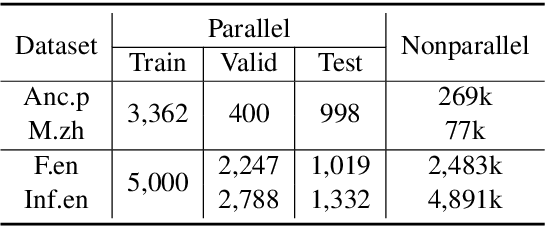
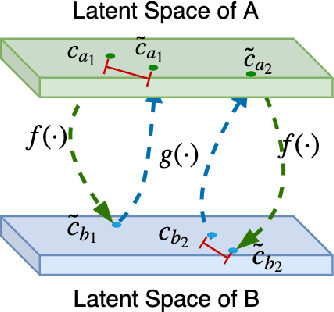

Text style transfer task requires the model to transfer a sentence of one style to another style while retaining its original content meaning, which is a challenging problem that has long suffered from the shortage of parallel data. In this paper, we first propose a semi-supervised text style transfer model that combines the small-scale parallel data with the large-scale nonparallel data. With these two types of training data, we introduce a projection function between the latent space of different styles and design two constraints to train it. We also introduce two other simple but effective semi-supervised methods to compare with. To evaluate the performance of the proposed methods, we build and release a novel style transfer dataset that alters sentences between the style of ancient Chinese poem and the modern Chinese.
Find a Reasonable Ending for Stories: Does Logic Relation Help the Story Cloze Test?
Dec 13, 2018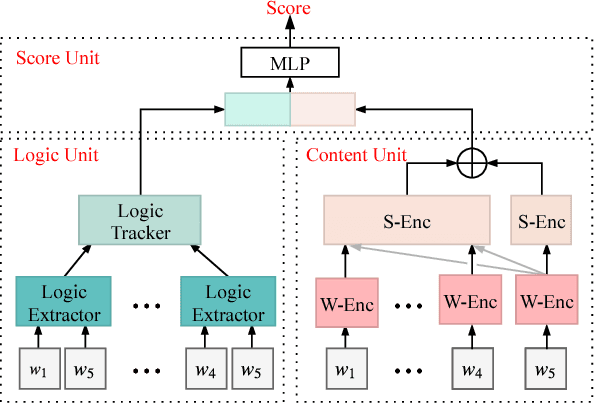
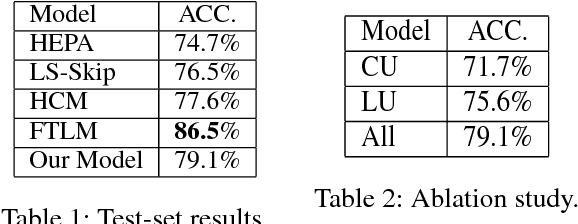

Natural language understanding is a challenging problem that covers a wide range of tasks. While previous methods generally train each task separately, we consider combining the cross-task features to enhance the task performance. In this paper, we incorporate the logic information with the help of the Natural Language Inference (NLI) task to the Story Cloze Test (SCT). Previous work on SCT considered various semantic information, such as sentiment and topic, but lack the logic information between sentences which is an essential element of stories. Thus we propose to extract the logic information during the course of the story to improve the understanding of the whole story. The logic information is modeled with the help of the NLI task. Experimental results prove the strength of the logic information.
One "Ruler" for All Languages: Multi-Lingual Dialogue Evaluation with Adversarial Multi-Task Learning
May 08, 2018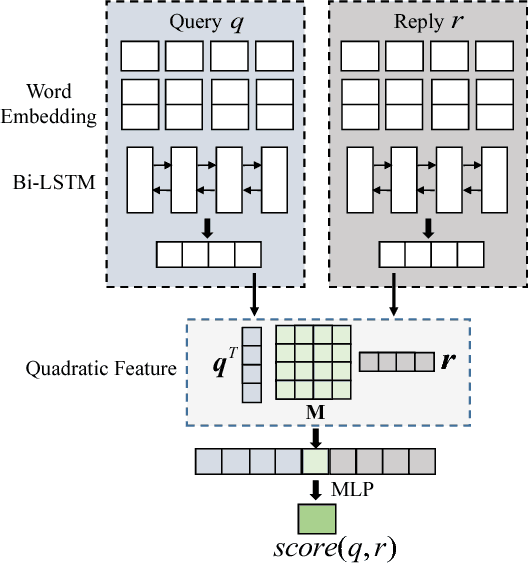
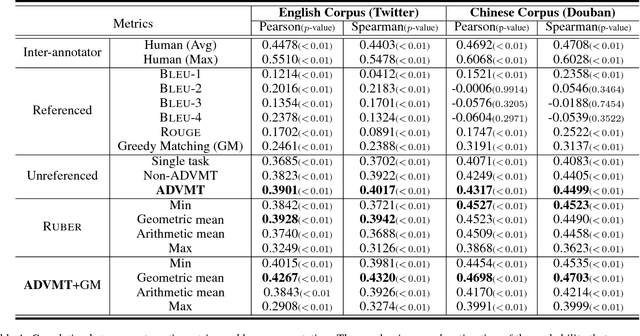
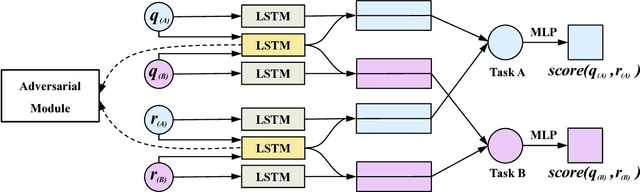

Automatic evaluating the performance of Open-domain dialogue system is a challenging problem. Recent work in neural network-based metrics has shown promising opportunities for automatic dialogue evaluation. However, existing methods mainly focus on monolingual evaluation, in which the trained metric is not flexible enough to transfer across different languages. To address this issue, we propose an adversarial multi-task neural metric (ADVMT) for multi-lingual dialogue evaluation, with shared feature extraction across languages. We evaluate the proposed model in two different languages. Experiments show that the adversarial multi-task neural metric achieves a high correlation with human annotation, which yields better performance than monolingual ones and various existing metrics.
Style Transfer in Text: Exploration and Evaluation
Nov 27, 2017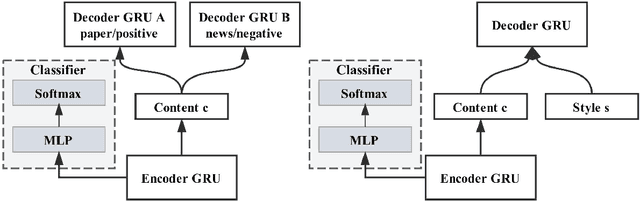
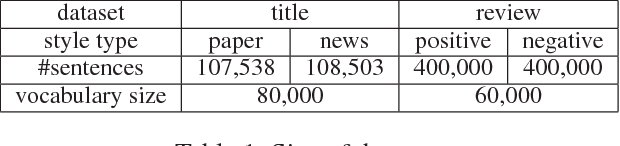
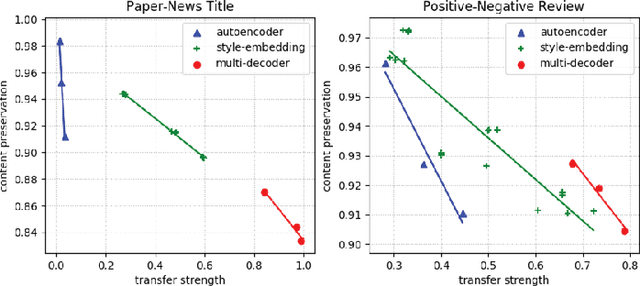

Style transfer is an important problem in natural language processing (NLP). However, the progress in language style transfer is lagged behind other domains, such as computer vision, mainly because of the lack of parallel data and principle evaluation metrics. In this paper, we propose to learn style transfer with non-parallel data. We explore two models to achieve this goal, and the key idea behind the proposed models is to learn separate content representations and style representations using adversarial networks. We also propose novel evaluation metrics which measure two aspects of style transfer: transfer strength and content preservation. We access our models and the evaluation metrics on two tasks: paper-news title transfer, and positive-negative review transfer. Results show that the proposed content preservation metric is highly correlate to human judgments, and the proposed models are able to generate sentences with higher style transfer strength and similar content preservation score comparing to auto-encoder.