 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Code Preference via Synthetic Evolution
Oct 04, 2024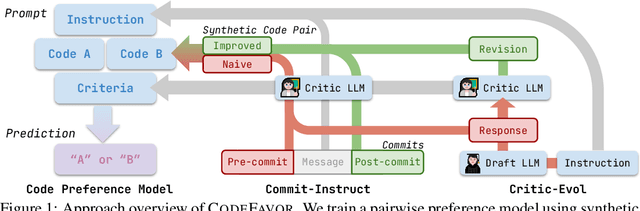

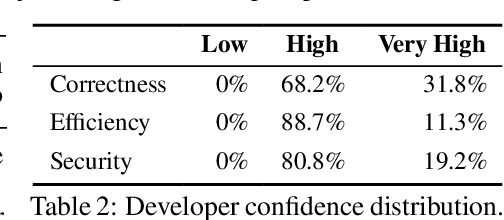
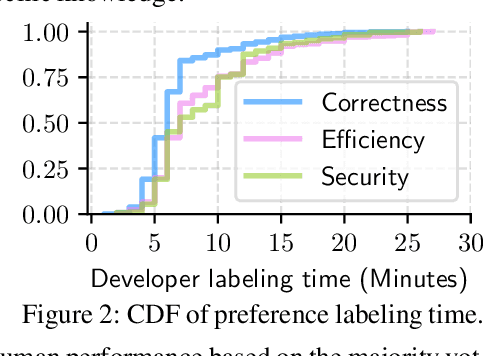
Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.
BASS: Batched Attention-optimized Speculative Sampling
Apr 24, 2024



Speculative decoding has emerged as a powerful method to improve latency and throughput in hosting large language models. However, most existing implementations focus on generating a single sequence. Real-world generative AI applications often require multiple responses and how to perform speculative decoding in a batched setting while preserving its latency benefits poses non-trivial challenges. This paper describes a system of batched speculative decoding that sets a new state of the art in multi-sequence generation latency and that demonstrates superior GPU utilization as well as quality of generations within a time budget. For example, for a 7.8B-size model on a single A100 GPU and with a batch size of 8, each sequence is generated at an average speed of 5.8ms per token, the overall throughput being 1.1K tokens per second. These results represent state-of-the-art latency and a 2.15X speed-up over optimized regular decoding. Within a time budget that regular decoding does not finish, our system is able to generate sequences with HumanEval Pass@First of 43% and Pass@All of 61%, far exceeding what's feasible with single-sequence speculative decoding. Our peak GPU utilization during decoding reaches as high as 15.8%, more than 3X the highest of that of regular decoding and around 10X of single-sequence speculative decoding.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024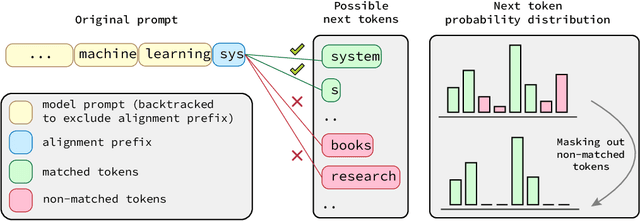



Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
Code-Aware Prompting: A study of Coverage Guided Test Generation in Regression Setting using LLM
Jan 31, 2024
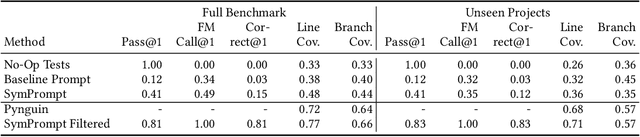
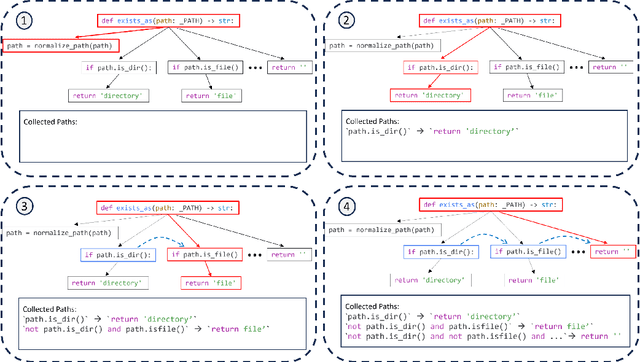

Testing plays a pivotal role in ensuring software quality, yet conventional Search Based Software Testing (SBST) methods often struggle with complex software units, achieving suboptimal test coverage. Recent work using large language models (LLMs) for test generation have focused on improving generation quality through optimizing the test generation context and correcting errors in model outputs, but use fixed prompting strategies that prompt the model to generate tests without additional guidance. As a result LLM-generated test suites still suffer from low coverage. In this paper, we present SymPrompt, a code-aware prompting strategy for LLMs in test generation. SymPrompt's approach is based on recent work that demonstrates LLMs can solve more complex logical problems when prompted to reason about the problem in a multi-step fashion. We apply this methodology to test generation by deconstructing the testsuite generation process into a multi-stage sequence, each of which is driven by a specific prompt aligned with the execution paths of the method under test, and exposing relevant type and dependency focal context to the model. Our approach enables pretrained LLMs to generate more complete test cases without any additional training. We implement SymPrompt using the TreeSitter parsing framework and evaluate on a benchmark challenging methods from open source Python projects. SymPrompt enhances correct test generations by a factor of 5 and bolsters relative coverage by 26% for CodeGen2. Notably, when applied to GPT-4, symbolic path prompts improve coverage by over 2x compared to baseline prompting strategies.
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning
Aug 10, 2023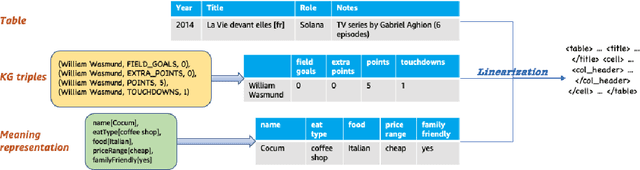



We present a novel approach for structured data-to-text generation that addresses the limitations of existing methods that primarily focus on specific types of structured data. Our proposed method aims to improve performance in multi-task training, zero-shot and few-shot scenarios by providing a unified representation that can handle various forms of structured data such as tables, knowledge graph triples, and meaning representations. We demonstrate that our proposed approach can effectively adapt to new structured forms, and can improve performance in comparison to current methods. For example, our method resulted in a 66% improvement in zero-shot BLEU scores when transferring models trained on table inputs to a knowledge graph dataset. Our proposed method is an important step towards a more general data-to-text generation framework.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023
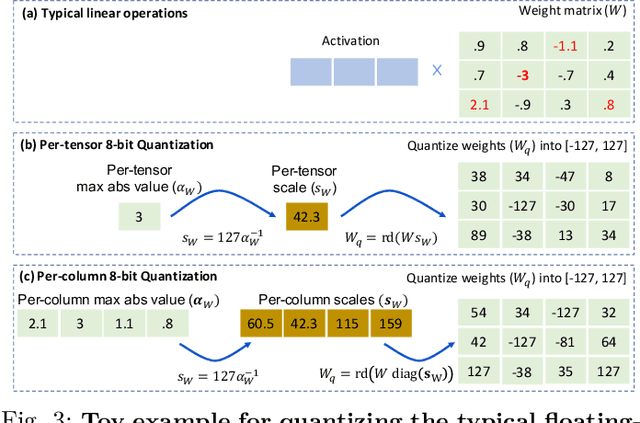
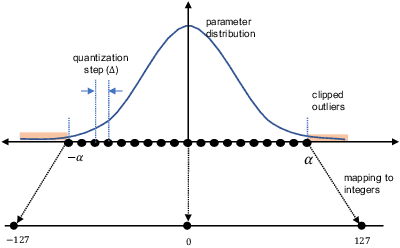
ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022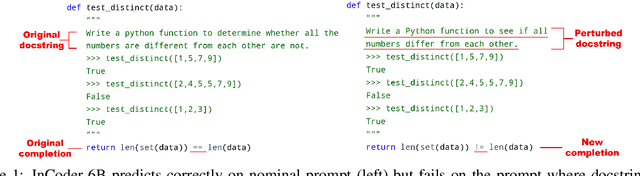

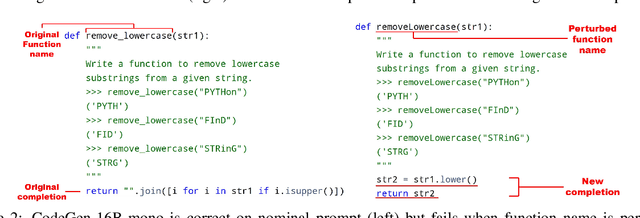

Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022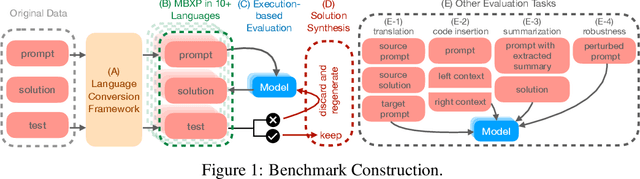
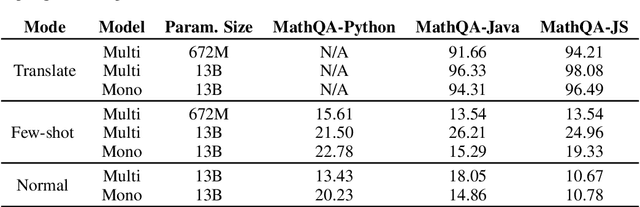


We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
Ape210K: A Large-Scale and Template-Rich Dataset of Math Word Problems
Oct 09, 2020


Automatic math word problem solving has attracted growing attention in recent years. The evaluation datasets used by previous works have serious limitations in terms of scale and diversity. In this paper, we release a new large-scale and template-rich math word problem dataset named Ape210K. It consists of 210K Chinese elementary school-level math problems, which is 9 times the size of the largest public dataset Math23K. Each problem contains both the gold answer and the equations needed to derive the answer. Ape210K is also of greater diversity with 56K templates, which is 25 times more than Math23K. Our analysis shows that solving Ape210K requires not only natural language understanding but also commonsense knowledge. We expect Ape210K to be a benchmark for math word problem solving systems. Experiments indicate that state-of-the-art models on the Math23K dataset perform poorly on Ape210K. We propose a copy-augmented and feature-enriched sequence to sequence (seq2seq) model, which outperforms existing models by 3.2% on the Math23K dataset and serves as a strong baseline of the Ape210K dataset. The gap is still significant between human and our baseline model, calling for further research efforts. We make Ape210K dataset publicly available at https://github.com/yuantiku/ape210k
Semi-supervised Text Style Transfer: Cross Projection in Latent Space
Sep 25, 2019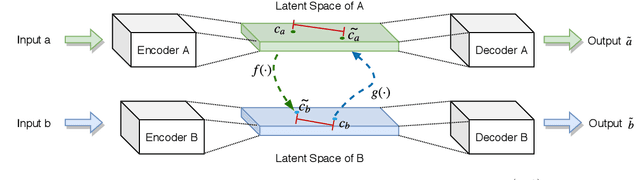
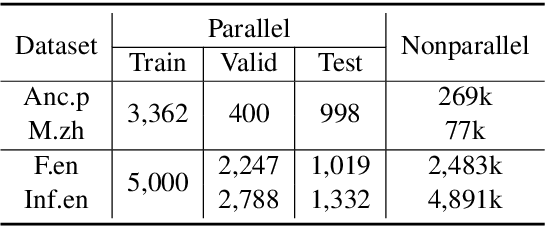
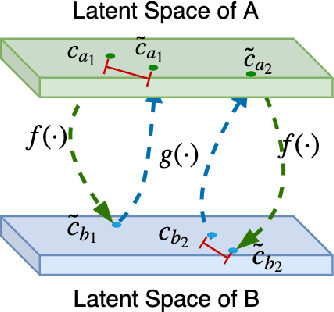

Text style transfer task requires the model to transfer a sentence of one style to another style while retaining its original content meaning, which is a challenging problem that has long suffered from the shortage of parallel data. In this paper, we first propose a semi-supervised text style transfer model that combines the small-scale parallel data with the large-scale nonparallel data. With these two types of training data, we introduce a projection function between the latent space of different styles and design two constraints to train it. We also introduce two other simple but effective semi-supervised methods to compare with. To evaluate the performance of the proposed methods, we build and release a novel style transfer dataset that alters sentences between the style of ancient Chinese poem and the modern Chinese.