 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gray Literature Study on Fairness Requirements in AI-enabled Software Engineering
Dec 08, 2025Today, with the growing obsession with applying Artificial Intelligence (AI), particularly Machine Learning (ML), to software across various contexts, much of the focus has been on the effectiveness of AI models, often measured through common metrics such as F1- score, while fairness receives relatively little attention. This paper presents a review of existing gray literature, examining fairness requirements in AI context, with a focus on how they are defined across various application domains, managed throughout the Software Development Life Cycle (SDLC), and the causes, as well as the corresponding consequences of their violation by AI models. Our gray literature investigation shows various definitions of fairness requirements in AI systems, commonly emphasizing non-discrimination and equal treatment across different demographic and social attributes. Fairness requirement management practices vary across the SDLC, particularly in model training and bias mitigation, fairness monitoring and evaluation, and data handling practices. Fairness requirement violations are frequently linked, but not limited, to data representation bias, algorithmic and model design bias, human judgment, and evaluation and transparency gaps. The corresponding consequences include harm in a broad sense, encompassing specific professional and societal impacts as key examples, stereotype reinforcement, data and privacy risks, and loss of trust and legitimacy in AI-supported decisions. These findings emphasize the need for consistent frameworks and practices to integrate fairness into AI software, paying as much attention to fairness as to effectiveness.
Accurate Crop Yield Estimation of Blueberries using Deep Learning and Smart Drones
Jan 04, 2025



We present an AI pipeline that involves using smart drones equipped with computer vision to obtain a more accurate fruit count and yield estimation of the number of blueberries in a field. The core components are two object-detection models based on the YOLO deep learning architecture: a Bush Model that is able to detect blueberry bushes from images captured at low altitudes and at different angles, and a Berry Model that can detect individual berries that are visible on a bush. Together, both models allow for more accurate crop yield estimation by allowing intelligent control of the drone's position and camera to safely capture side-view images of bushes up close. In addition to providing experimental results for our models, which show good accuracy in terms of precision and recall when captured images are cropped around the foreground center bush, we also describe how to deploy our models to map out blueberry fields using different sampling strategies, and discuss the challenges of annotating very small objects (blueberries) and difficulties in evaluating the effectiveness of our models.
QSM-RimDS: A highly sensitive paramagnetic rim lesion detection and segmentation tool for multiple sclerosis lesions
Dec 13, 2024



Paramagnetic rim lesions (PRLs) are imaging biomarker of the innate immune response in MS lesions. QSM-RimNet, a state-of-the-art tool for PRLs detection on QSM, can identify PRLs but requires precise QSM lesion mask and does not provide rim segmentation. Therefore, the aims of this study are to develop QSM-RimDS algorithm to detect PRLs using the readily available FLAIR lesion mask and to provide rim segmentation for microglial quantification. QSM-RimDS, a deep-learning based tool for joint PRL rim segmentation and PRL detection has been developed. QSM-RimDS has obtained state-of-the art performance in PRL detection and therefore has the potential to be used in clinical practice as a tool to assist human readers for the time-consuming PRL detection and segmentation task. QSM-RimDS is made publicly available [https://github.com/kennyha85/QSM_RimDS]
Learning Code Preference via Synthetic Evolution
Oct 04, 2024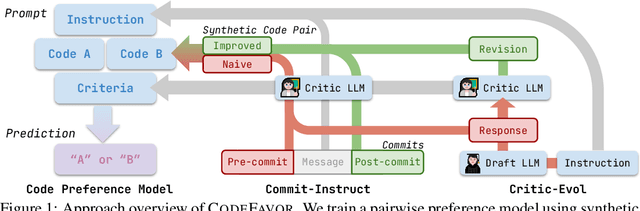

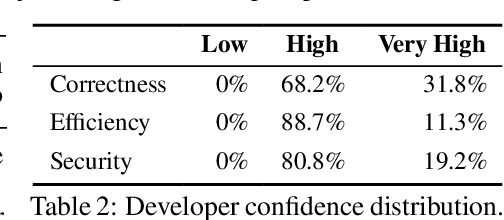
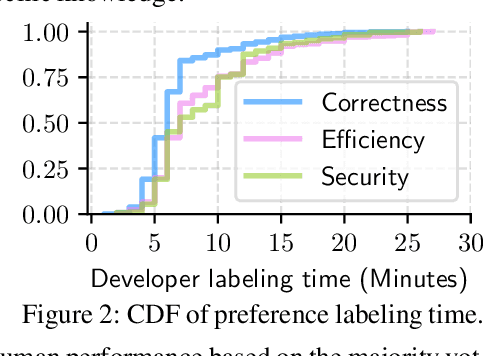
Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.
Mitigating Adversarial Perturbations for Deep Reinforcement Learning via Vector Quantization
Oct 04, 2024



Recent studies reveal that well-performing reinforcement learning (RL) agents in training often lack resilience against adversarial perturbations during deployment. This highlights the importance of building a robust agent before deploying it in the real world. Most prior works focus on developing robust training-based procedures to tackle this problem, including enhancing the robustness of the deep neural network component itself or adversarially training the agent on strong attacks. In this work, we instead study an input transformation-based defense for RL. Specifically, we propose using a variant of vector quantization (VQ) as a transformation for input observations, which is then used to reduce the space of adversarial attacks during testing, resulting in the transformed observations being less affected by attacks. Our method is computationally efficient and seamlessly integrates with adversarial training, further enhancing the robustness of RL agents against adversarial attacks. Through extensive experiments in multiple environments, we demonstrate that using VQ as the input transformation effectively defends against adversarial attacks on the agent's observations.
On the Perturbed States for Transformed Input-robust Reinforcement Learning
Aug 02, 2024Reinforcement Learning (RL) agents demonstrating proficiency in a training environment exhibit vulnerability to adversarial perturbations in input observations during deployment. This underscores the importance of building a robust agent before its real-world deployment. To alleviate the challenging point, prior works focus on developing robust training-based procedures, encompassing efforts to fortify the deep neural network component's robustness or subject the agent to adversarial training against potent attacks. In this work, we propose a novel method referred to as Transformed Input-robust RL (TIRL), which explores another avenue to mitigate the impact of adversaries by employing input transformation-based defenses. Specifically, we introduce two principles for applying transformation-based defenses in learning robust RL agents: (1) autoencoder-styled denoising to reconstruct the original state and (2) bounded transformations (bit-depth reduction and vector quantization (VQ)) to achieve close transformed inputs. The transformations are applied to the state before feeding it into the policy network. Extensive experiments on multiple MuJoCo environments demonstrate that input transformation-based defenses, i.e., VQ, defend against several adversaries in the state observations. The official code is available at https://github.com/tunglm2203/tirl
Active Learning for Fair and Stable Online Allocations
Jun 20, 2024We explore an active learning approach for dynamic fair resource allocation problems. Unlike previous work that assumes full feedback from all agents on their allocations, we consider feedback from a select subset of agents at each epoch of the online resource allocation process. Despite this restriction, our proposed algorithms provide regret bounds that are sub-linear in number of time-periods for various measures that include fairness metrics commonly used in resource allocation problems and stability considerations in matching mechanisms. The key insight of our algorithms lies in adaptively identifying the most informative feedback using dueling upper and lower confidence bounds. With this strategy, we show that efficient decision-making does not require extensive feedback and produces efficient outcomes for a variety of problem classes.
Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
May 18, 2024



Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
Sep 21, 2023Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
LAD: A Hybrid Deep Learning System for Benign Paroxysmal Positional Vertigo Disorders Diagnostic
Oct 15, 2022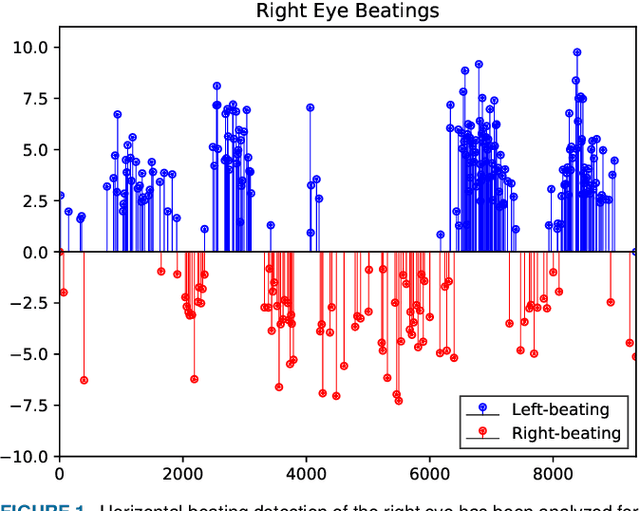
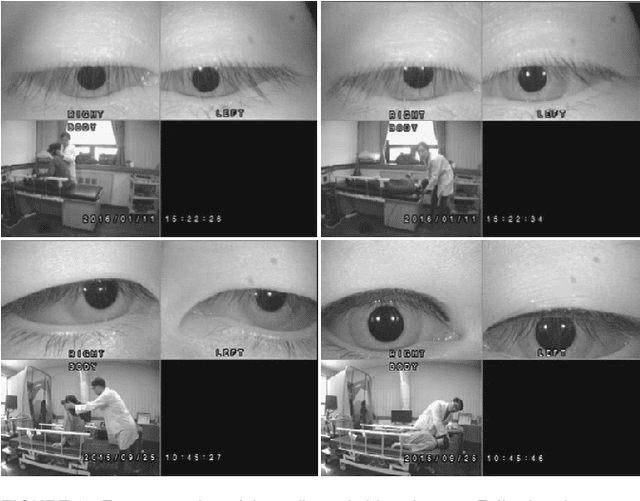
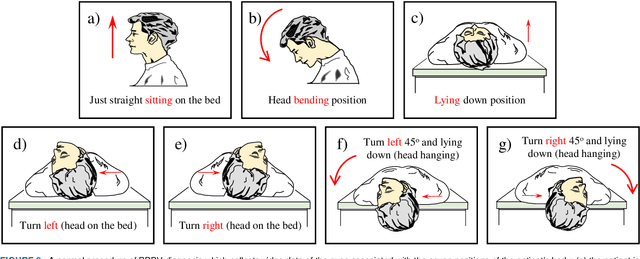

Herein, we introduce "Look and Diagnose" (LAD), a hybrid deep learning-based system that aims to support doctors in the medical field in diagnosing effectively the Benign Paroxysmal Positional Vertigo (BPPV) disorder. Given the body postures of the patient in the Dix-Hallpike and lateral head turns test, the visual information of both eyes is captured and fed into LAD for analyzing and classifying into one of six possible disorders the patient might be suffering from. The proposed system consists of two streams: (1) an RNN-based stream that takes raw RGB images of both eyes to extract visual features and optical flow of each eye followed by ternary classification to determine left/right posterior canal (PC) or other; and (2) pupil detector stream that detects the pupil when it is classified as Non-PC and classifies the direction and strength of the beating to categorize the Non-PC types into the remaining four classes: Geotropic BPPV (left and right) and Apogeotropic BPPV (left and right). Experimental results show that with the patient's body postures, the system can accurately classify given BPPV disorder into the six types of disorders with an accuracy of 91% on the validation set. The proposed method can successfully classify disorders with an accuracy of 93% for the Posterior Canal disorder and 95% for the Geotropic and Apogeotropic disorder, paving a potential direction for research with the medical data.