 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
Sep 21, 2023



Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
Improving Low-Resource Question Answering using Active Learning in Multiple Stages
Nov 27, 2022



Neural approaches have become very popular in the domain of Question Answering, however they require a large amount of annotated data. Furthermore, they often yield very good performance but only in the domain they were trained on. In this work we propose a novel approach that combines data augmentation via question-answer generation with Active Learning to improve performance in low resource settings, where the target domains are diverse in terms of difficulty and similarity to the source domain. We also investigate Active Learning for question answering in different stages, overall reducing the annotation effort of humans. For this purpose, we consider target domains in realistic settings, with an extremely low amount of annotated samples but with many unlabeled documents, which we assume can be obtained with little effort. Additionally, we assume sufficient amount of labeled data from the source domain is available. We perform extensive experiments to find the best setup for incorporating domain experts. Our findings show that our novel approach, where humans are incorporated as early as possible in the process, boosts performance in the low-resource, domain-specific setting, allowing for low-labeling-effort question answering systems in new, specialized domains. They further demonstrate how human annotation affects the performance of QA depending on the stage it is performed.
SoftGroup++: Scalable 3D Instance Segmentation with Octree Pyramid Grouping
Sep 17, 2022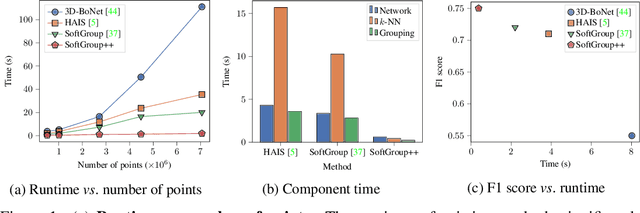
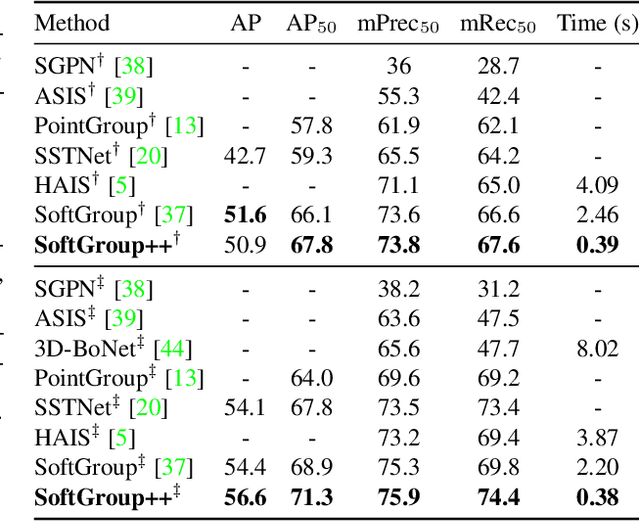
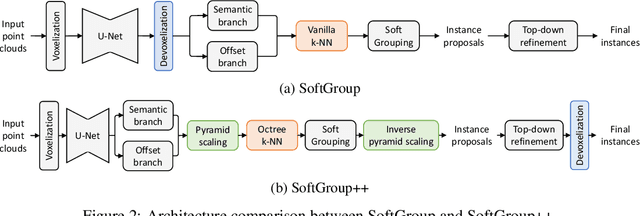

Existing state-of-the-art 3D point cloud instance segmentation methods rely on a grouping-based approach that groups points to obtain object instances. Despite improvement in producing accurate segmentation results, these methods lack scalability and commonly require dividing large input into multiple parts. To process a scene with millions of points, the existing fastest method SoftGroup \cite{vu2022softgroup} requires tens of seconds, which is under satisfaction. Our finding is that $k$-Nearest Neighbor ($k$-NN), which serves as the prerequisite of grouping, is a computational bottleneck. This bottleneck severely worsens the inference time in the scene with a large number of points. This paper proposes SoftGroup++ to address this computational bottleneck and further optimize the inference speed of the whole network. SoftGroup++ is built upon SoftGroup, which differs in three important aspects: (1) performs octree $k$-NN instead of vanilla $k$-NN to reduce time complexity from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$, (2) performs pyramid scaling that adaptively downsamples backbone outputs to reduce search space for $k$-NN and grouping, and (3) performs late devoxelization that delays the conversion from voxels to points towards the end of the model such that intermediate components operate at a low computational cost. Extensive experiments on various indoor and outdoor datasets demonstrate the efficacy of the proposed SoftGroup++. Notably, SoftGroup++ processes large scenes of millions of points by a single forward without dividing the input into multiple parts, thus enriching contextual information. Especially, SoftGroup++ achieves 2.4 points AP$_{50}$ improvement while nearly $6\times$ faster than the existing fastest method on S3DIS dataset. The code and trained models will be made publicly available.
Learning Imbalanced Datasets with Maximum Margin Loss
Jun 11, 2022
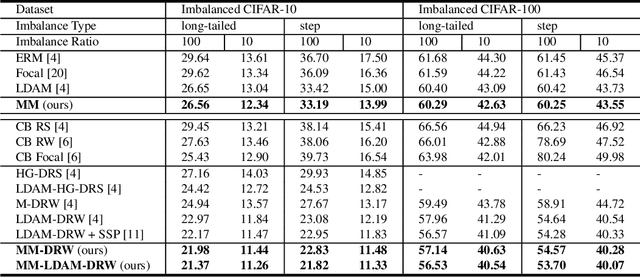
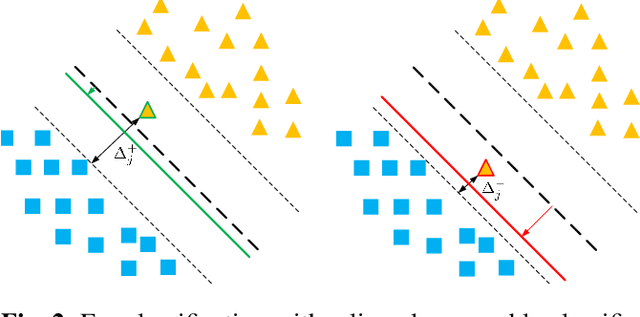
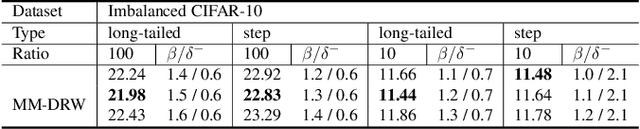
A learning algorithm referred to as Maximum Margin (MM) is proposed for considering the class-imbalance data learning issue: the trained model tends to predict the majority of classes rather than the minority ones. That is, underfitting for minority classes seems to be one of the challenges of generalization. For a good generalization of the minority classes, we design a new Maximum Margin (MM) loss function, motivated by minimizing a margin-based generalization bound through the shifting decision bound. The theoretically-principled label-distribution-aware margin (LDAM) loss was successfully applied with prior strategies such as re-weighting or re-sampling along with the effective training schedule. However, they did not investigate the maximum margin loss function yet. In this study, we investigate the performances of two types of hard maximum margin-based decision boundary shift with LDAM's training schedule on artificially imbalanced CIFAR-10/100 for fair comparisons and effectiveness.
SoftGroup for 3D Instance Segmentation on Point Clouds
Mar 03, 2022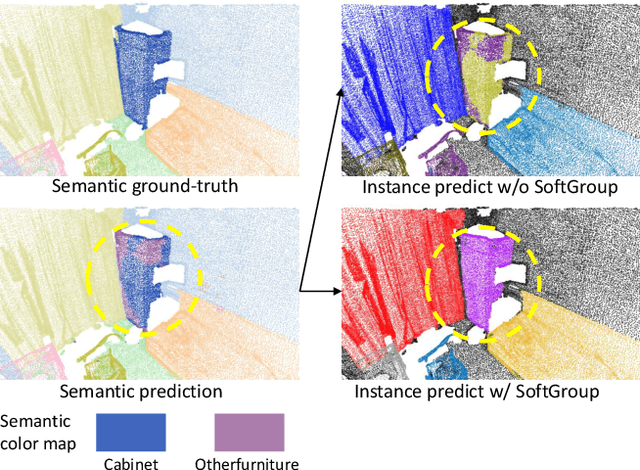
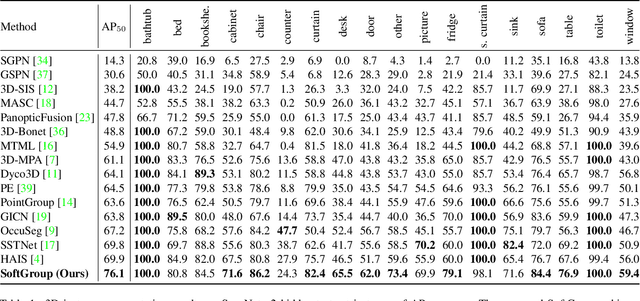
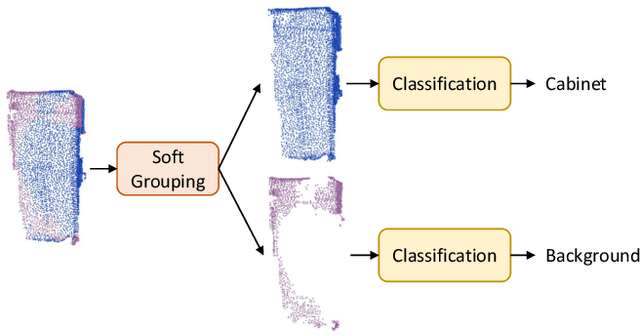
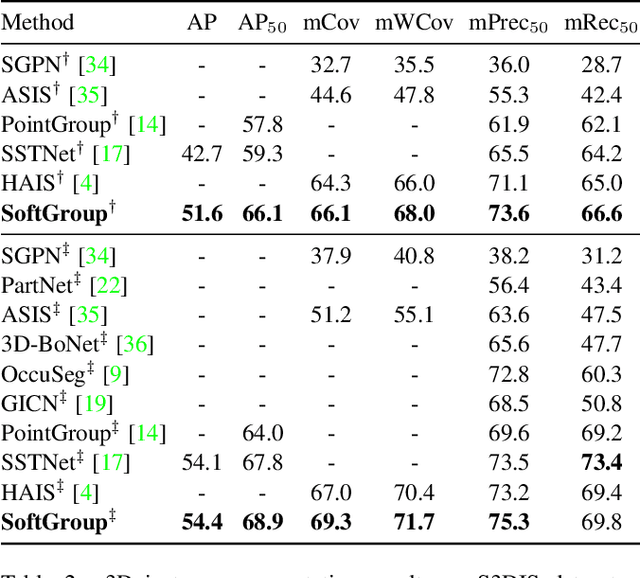
Existing state-of-the-art 3D instance segmentation methods perform semantic segmentation followed by grouping. The hard predictions are made when performing semantic segmentation such that each point is associated with a single class. However, the errors stemming from hard decision propagate into grouping that results in (1) low overlaps between the predicted instance with the ground truth and (2) substantial false positives. To address the aforementioned problems, this paper proposes a 3D instance segmentation method referred to as SoftGroup by performing bottom-up soft grouping followed by top-down refinement. SoftGroup allows each point to be associated with multiple classes to mitigate the problems stemming from semantic prediction errors and suppresses false positive instances by learning to categorize them as background. Experimental results on different datasets and multiple evaluation metrics demonstrate the efficacy of SoftGroup. Its performance surpasses the strongest prior method by a significant margin of +6.2% on the ScanNet v2 hidden test set and +6.8% on S3DIS Area 5 in terms of AP_50. SoftGroup is also fast, running at 345ms per scan with a single Titan X on ScanNet v2 dataset. The source code and trained models for both datasets are available at \url{https://github.com/thangvubk/SoftGroup.git}.
Sample-efficient Reinforcement Learning Representation Learning with Curiosity Contrastive Forward Dynamics Model
Mar 15, 2021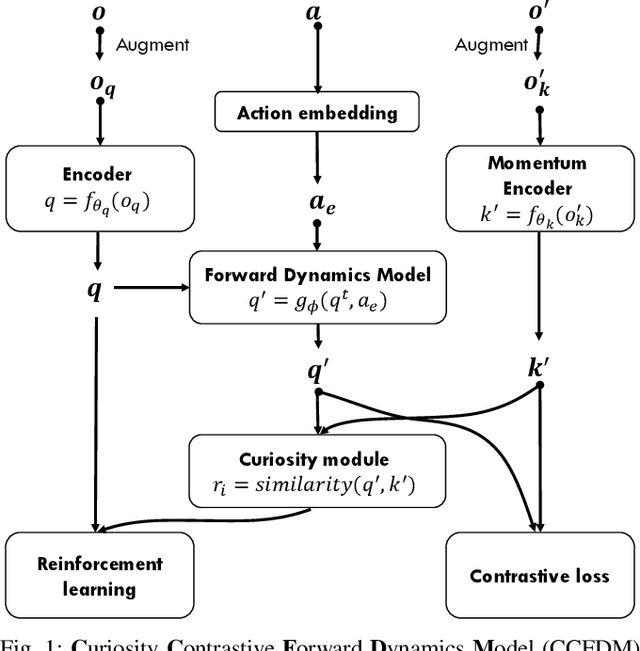
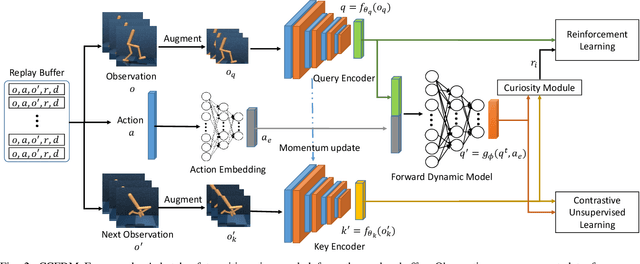
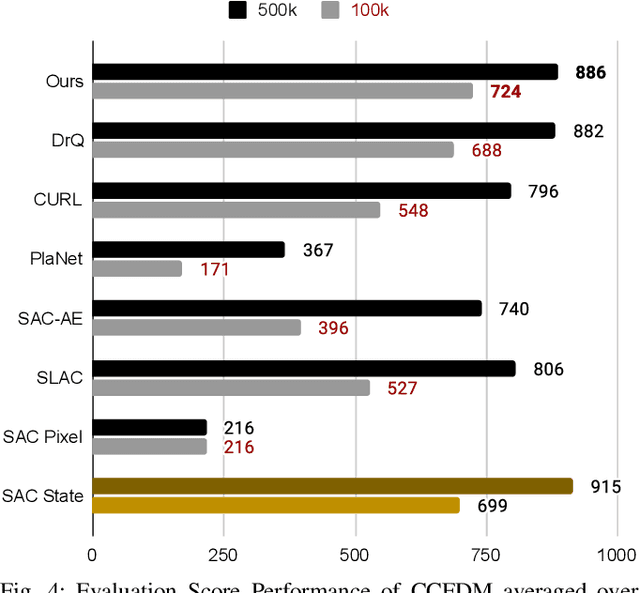
Developing an agent in reinforcement learning (RL) that is capable of performing complex control tasks directly from high-dimensional observation such as raw pixels is yet a challenge as efforts are made towards improving sample efficiency and generalization. This paper considers a learning framework for Curiosity Contrastive Forward Dynamics Model (CCFDM) in achieving a more sample-efficient RL based directly on raw pixels. CCFDM incorporates a forward dynamics model (FDM) and performs contrastive learning to train its deep convolutional neural network-based image encoder (IE) to extract conducive spatial and temporal information for achieving a more sample efficiency for RL. In addition, during training, CCFDM provides intrinsic rewards, produced based on FDM prediction error, encourages the curiosity of the RL agent to improve exploration. The diverge and less-repetitive observations provide by both our exploration strategy and data augmentation available in contrastive learning improve not only the sample efficiency but also the generalization. Performance of existing model-free RL methods such as Soft Actor-Critic built on top of CCFDM outperforms prior state-of-the-art pixel-based RL methods on the DeepMind Control Suite benchmark.
SCNet: Training Inference Sample Consistency for Instance Segmentation
Dec 18, 2020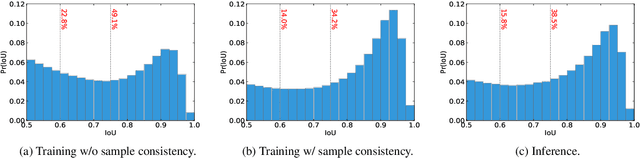
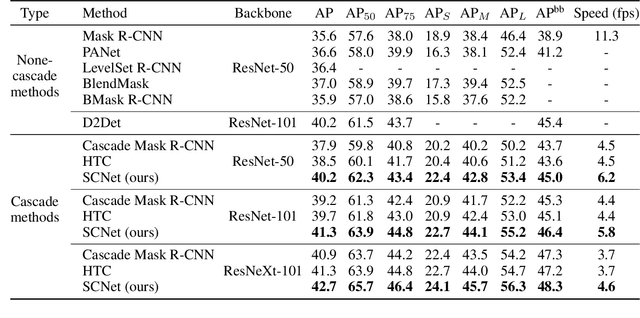
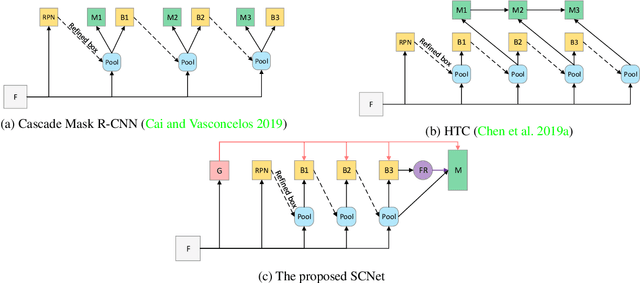

Cascaded architectures have brought significant performance improvement in object detection and instance segmentation. However, there are lingering issues regarding the disparity in the Intersection-over-Union (IoU) distribution of the samples between training and inference. This disparity can potentially exacerbate detection accuracy. This paper proposes an architecture referred to as Sample Consistency Network (SCNet) to ensure that the IoU distribution of the samples at training time is close to that at inference time. Furthermore, SCNet incorporates feature relay and utilizes global contextual information to further reinforce the reciprocal relationships among classifying, detecting, and segmenting sub-tasks. Extensive experiments on the standard COCO dataset reveal the effectiveness of the proposed method over multiple evaluation metrics, including box AP, mask AP, and inference speed. In particular, while running 38\% faster, the proposed SCNet improves the AP of the box and mask predictions by respectively 1.3 and 2.3 points compared to the strong Cascade Mask R-CNN baseline. Code is available at \url{https://github.com/thangvubk/SCNet}.
Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution
Sep 15, 2019

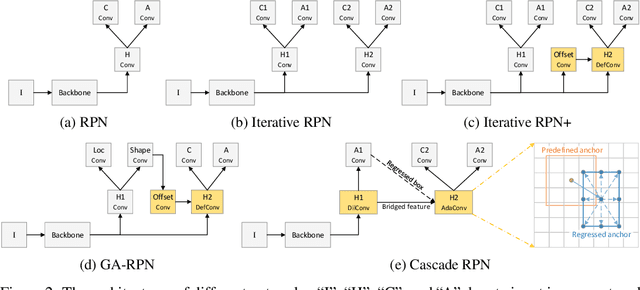
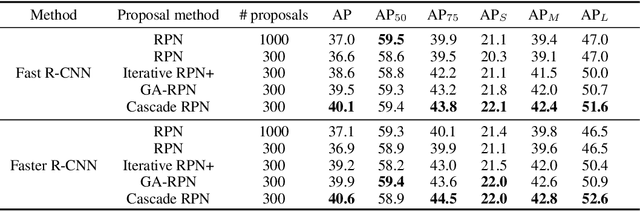
This paper considers an architecture referred to as Cascade Region Proposal Network (Cascade RPN) for improving the region-proposal quality and detection performance by \textit{systematically} addressing the limitation of the conventional RPN that \textit{heuristically defines} the anchors and \textit{aligns} the features to the anchors. First, instead of using multiple anchors with predefined scales and aspect ratios, Cascade RPN relies on a \textit{single anchor} per location and performs multi-stage refinement. Each stage is progressively more stringent in defining positive samples by starting out with an anchor-free metric followed by anchor-based metrics in the ensuing stages. Second, to attain alignment between the features and the anchors throughout the stages, \textit{adaptive convolution} is proposed that takes the anchors in addition to the image features as its input and learns the sampled features guided by the anchors. A simple implementation of a two-stage Cascade RPN achieves AR 13.4 points higher than that of the conventional RPN, surpassing any existing region proposal methods. When adopting to Fast R-CNN and Faster R-CNN, Cascade RPN can improve the detection mAP by 3.1 and 3.5 points, respectively. The code is made publicly available at \url{https://github.com/thangvubk/Cascade-RPN.git}.