 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIT-CXR: End-to-End Transformer for Chest X-Ray Report Generation
Jan 05, 2025



Medical imaging is crucial for diagnosing, monitoring, and treating medical conditions. The medical reports of radiology images are the primary medium through which medical professionals attest their findings, but their writing is time consuming and requires specialized clinical expertise. The automated generation of radiography reports has thus the potential to improve and standardize patient care and significantly reduce clinicians workload. Through our work, we have designed and evaluated an end-to-end transformer-based method to generate accurate and factually complete radiology reports for X-ray images. Additionally, we are the first to introduce curriculum learning for end-to-end transformers in medical imaging and demonstrate its impact in obtaining improved performance. The experiments have been conducted using the MIMIC-CXR-JPG database, the largest available chest X-ray dataset. The results obtained are comparable with the current state-of-the-art on the natural language generation (NLG) metrics BLEU and ROUGE-L, while setting new state-of-the-art results on F1 examples-averaged, F1-macro and F1-micro metrics for clinical accuracy and on the METEOR metric widely used for NLG.
Towards Foundation Models for Critical Care Time Series
Nov 25, 2024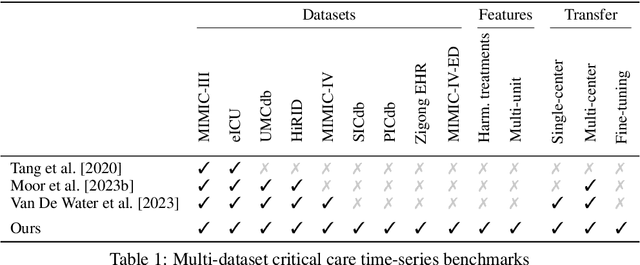
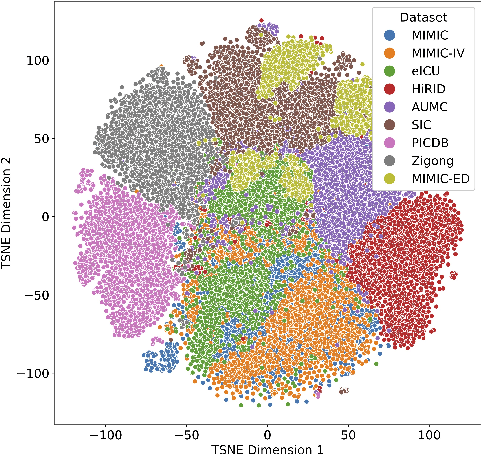
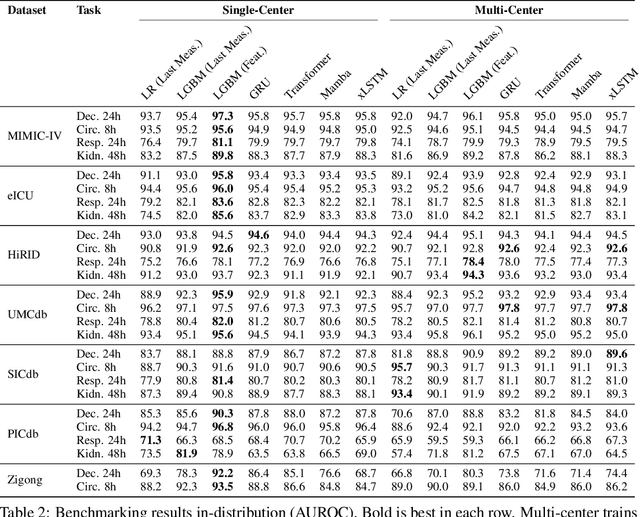
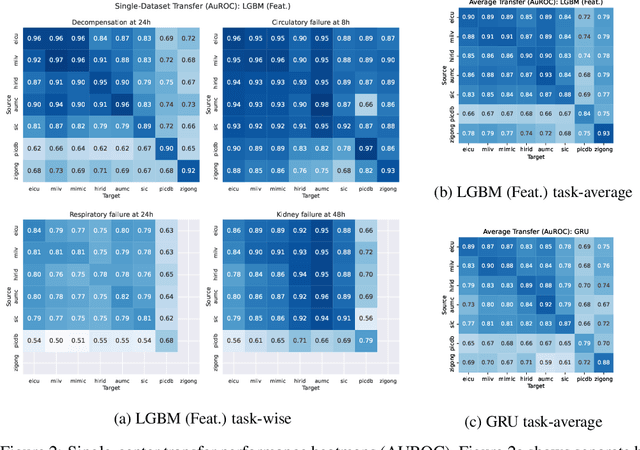
Notable progress has been made in generalist medical large language models across various healthcare areas. However, large-scale modeling of in-hospital time series data - such as vital signs, lab results, and treatments in critical care - remains underexplored. Existing datasets are relatively small, but combining them can enhance patient diversity and improve model robustness. To effectively utilize these combined datasets for large-scale modeling, it is essential to address the distribution shifts caused by varying treatment policies, necessitating the harmonization of treatment variables across the different datasets. This work aims to establish a foundation for training large-scale multi-variate time series models on critical care data and to provide a benchmark for machine learning models in transfer learning across hospitals to study and address distribution shift challenges. We introduce a harmonized dataset for sequence modeling and transfer learning research, representing the first large-scale collection to include core treatment variables. Future plans involve expanding this dataset to support further advancements in transfer learning and the development of scalable, generalizable models for critical healthcare applications.
Improving Low-Resource Question Answering using Active Learning in Multiple Stages
Nov 27, 2022



Neural approaches have become very popular in the domain of Question Answering, however they require a large amount of annotated data. Furthermore, they often yield very good performance but only in the domain they were trained on. In this work we propose a novel approach that combines data augmentation via question-answer generation with Active Learning to improve performance in low resource settings, where the target domains are diverse in terms of difficulty and similarity to the source domain. We also investigate Active Learning for question answering in different stages, overall reducing the annotation effort of humans. For this purpose, we consider target domains in realistic settings, with an extremely low amount of annotated samples but with many unlabeled documents, which we assume can be obtained with little effort. Additionally, we assume sufficient amount of labeled data from the source domain is available. We perform extensive experiments to find the best setup for incorporating domain experts. Our findings show that our novel approach, where humans are incorporated as early as possible in the process, boosts performance in the low-resource, domain-specific setting, allowing for low-labeling-effort question answering systems in new, specialized domains. They further demonstrate how human annotation affects the performance of QA depending on the stage it is performed.
SQALER: Scaling Question Answering by Decoupling Multi-Hop and Logical Reasoning
Oct 27, 2021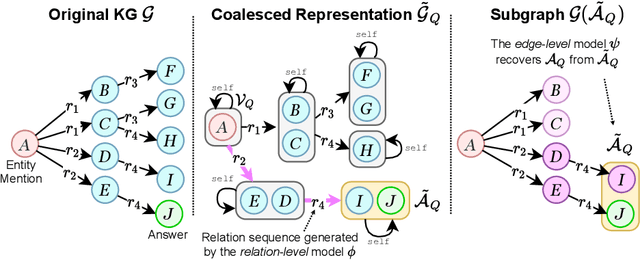
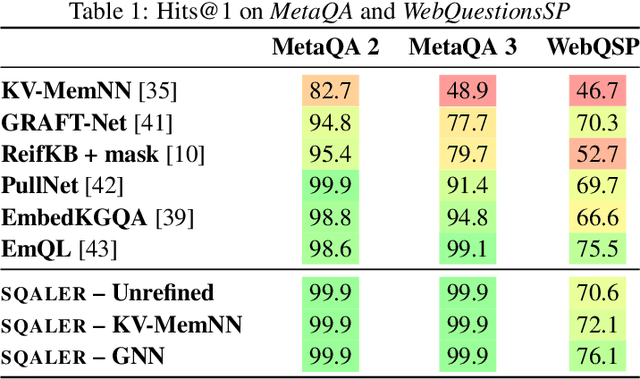
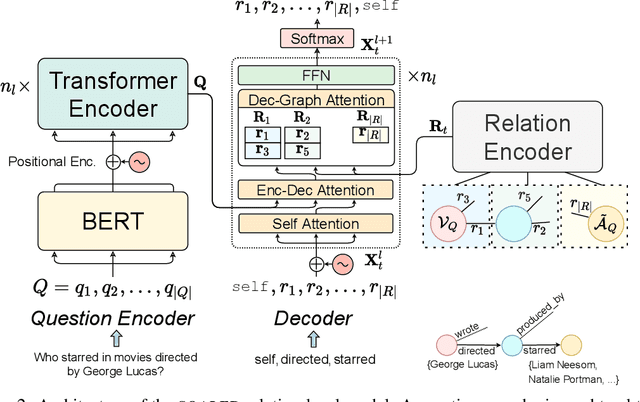
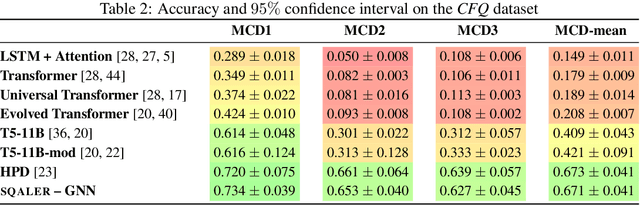
State-of-the-art approaches to reasoning and question answering over knowledge graphs (KGs) usually scale with the number of edges and can only be applied effectively on small instance-dependent subgraphs. In this paper, we address this issue by showing that multi-hop and more complex logical reasoning can be accomplished separately without losing expressive power. Motivated by this insight, we propose an approach to multi-hop reasoning that scales linearly with the number of relation types in the graph, which is usually significantly smaller than the number of edges or nodes. This produces a set of candidate solutions that can be provably refined to recover the solution to the original problem. Our experiments on knowledge-based question answering show that our approach solves the multi-hop MetaQA dataset, achieves a new state-of-the-art on the more challenging WebQuestionsSP, is orders of magnitude more scalable than competitive approaches, and can achieve compositional generalization out of the training distribution.