 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Discovery of Feature Groups in Clinical Time Series
Nov 11, 2025Clinical time series data are critical for patient monitoring and predictive modeling. These time series are typically multivariate and often comprise hundreds of heterogeneous features from different data sources. The grouping of features based on similarity and relevance to the prediction task has been shown to enhance the performance of deep learning architectures. However, defining these groups a priori using only semantic knowledge is challenging, even for domain experts. To address this, we propose a novel method that learns feature groups by clustering weights of feature-wise embedding layers. This approach seamlessly integrates into standard supervised training and discovers the groups that directly improve downstream performance on clinically relevant tasks. We demonstrate that our method outperforms static clustering approaches on synthetic data and achieves performance comparable to expert-defined groups on real-world medical data. Moreover, the learned feature groups are clinically interpretable, enabling data-driven discovery of task-relevant relationships between variables.
Towards Foundation Models for Critical Care Time Series
Nov 25, 2024
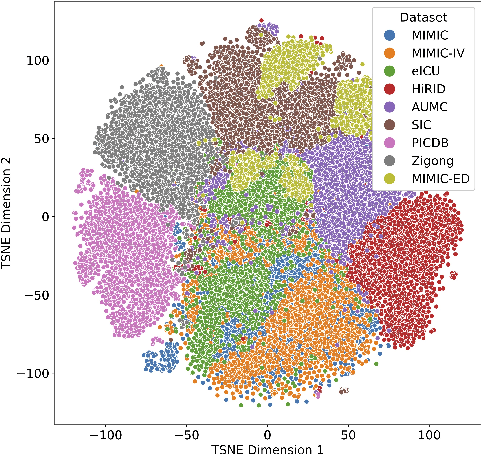
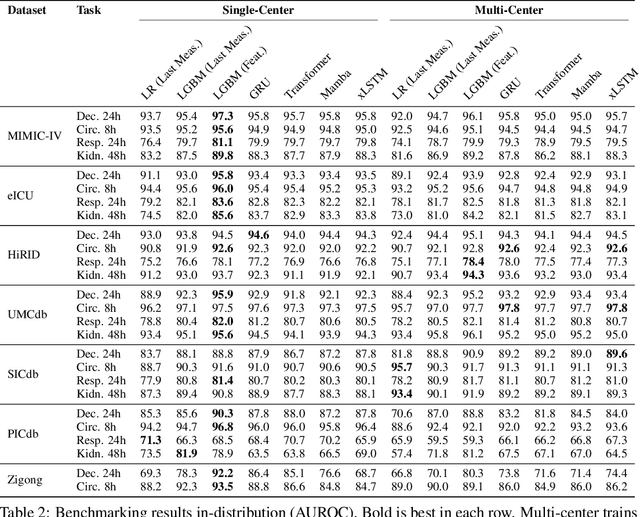
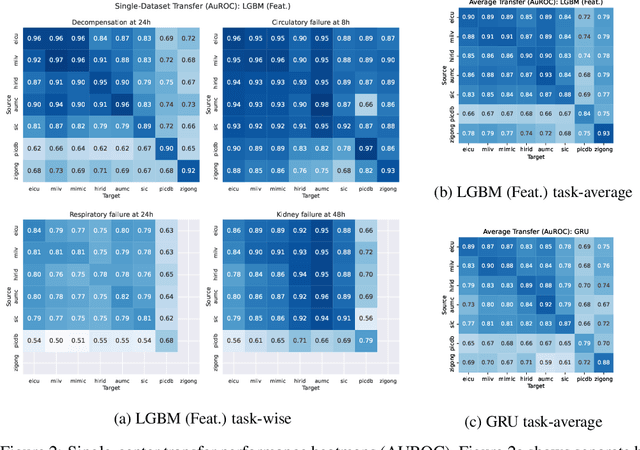
Notable progress has been made in generalist medical large language models across various healthcare areas. However, large-scale modeling of in-hospital time series data - such as vital signs, lab results, and treatments in critical care - remains underexplored. Existing datasets are relatively small, but combining them can enhance patient diversity and improve model robustness. To effectively utilize these combined datasets for large-scale modeling, it is essential to address the distribution shifts caused by varying treatment policies, necessitating the harmonization of treatment variables across the different datasets. This work aims to establish a foundation for training large-scale multi-variate time series models on critical care data and to provide a benchmark for machine learning models in transfer learning across hospitals to study and address distribution shift challenges. We introduce a harmonized dataset for sequence modeling and transfer learning research, representing the first large-scale collection to include core treatment variables. Future plans involve expanding this dataset to support further advancements in transfer learning and the development of scalable, generalizable models for critical healthcare applications.
Towards Dynamic Feature Acquisition on Medical Time Series by Maximizing Conditional Mutual Information
Jul 18, 2024



Knowing which features of a multivariate time series to measure and when is a key task in medicine, wearables, and robotics. Better acquisition policies can reduce costs while maintaining or even improving the performance of downstream predictors. Inspired by the maximization of conditional mutual information, we propose an approach to train acquirers end-to-end using only the downstream loss. We show that our method outperforms random acquisition policy, matches a model with an unrestrained budget, but does not yet overtake a static acquisition strategy. We highlight the assumptions and outline avenues for future work.