 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization and Adaptation in Intensive Care with Anchor Regression
Jul 29, 2025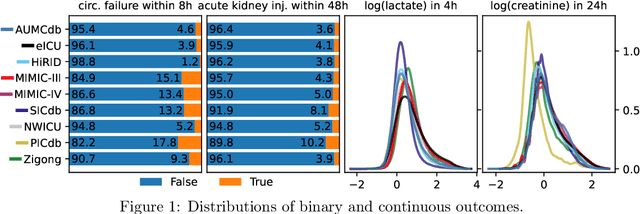

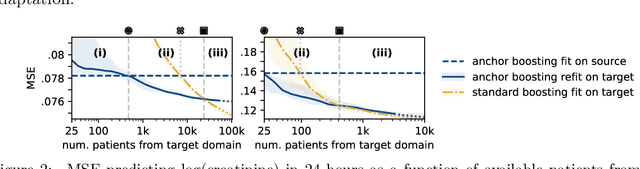
The performance of predictive models in clinical settings often degrades when deployed in new hospitals due to distribution shifts. This paper presents a large-scale study of causality-inspired domain generalization on heterogeneous multi-center intensive care unit (ICU) data. We apply anchor regression and introduce anchor boosting, a novel, tree-based nonlinear extension, to a large dataset comprising 400,000 patients from nine distinct ICU databases. The anchor regularization consistently improves out-of-distribution performance, particularly for the most dissimilar target domains. The methods appear robust to violations of theoretical assumptions, such as anchor exogeneity. Furthermore, we propose a novel conceptual framework to quantify the utility of large external data datasets. By evaluating performance as a function of available target-domain data, we identify three regimes: (i) a domain generalization regime, where only the external model should be used, (ii) a domain adaptation regime, where refitting the external model is optimal, and (iii) a data-rich regime, where external data provides no additional value.
Towards Foundation Models for Critical Care Time Series
Nov 25, 2024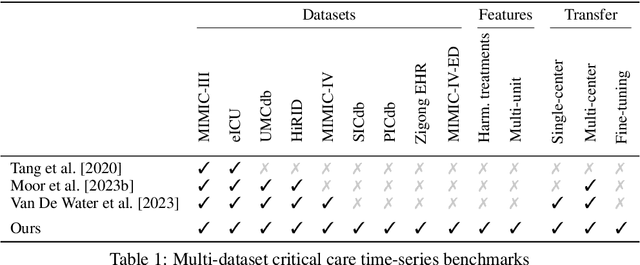
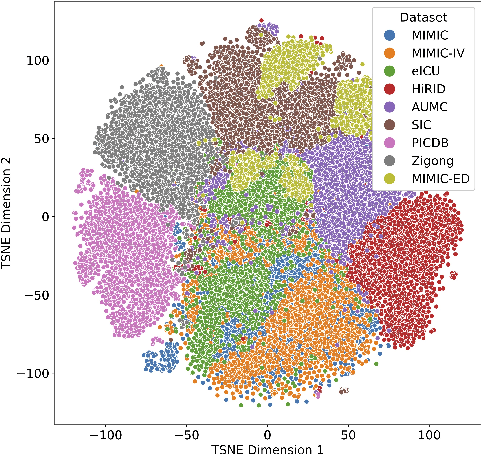
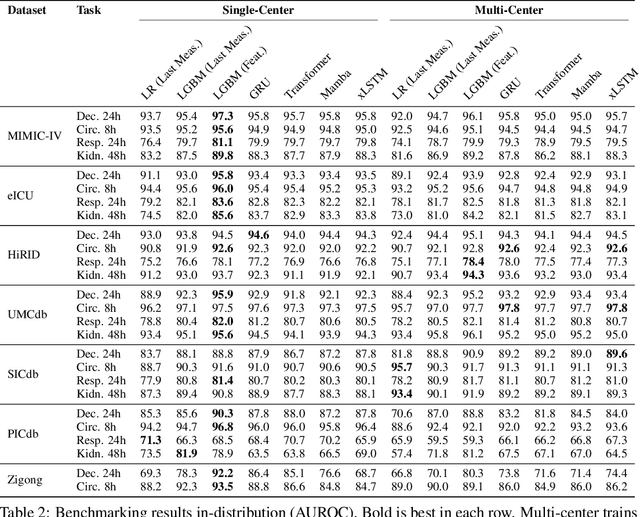
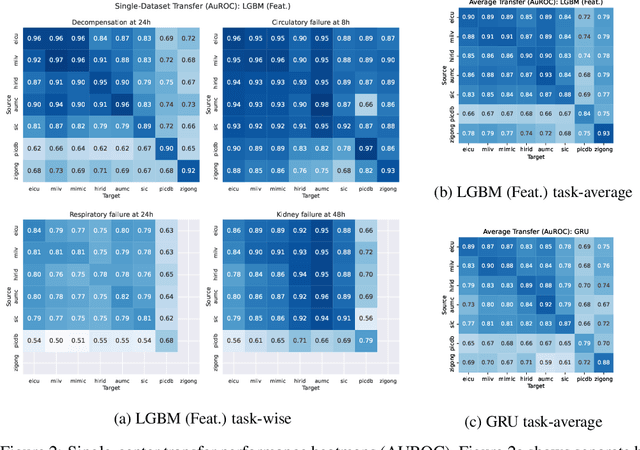
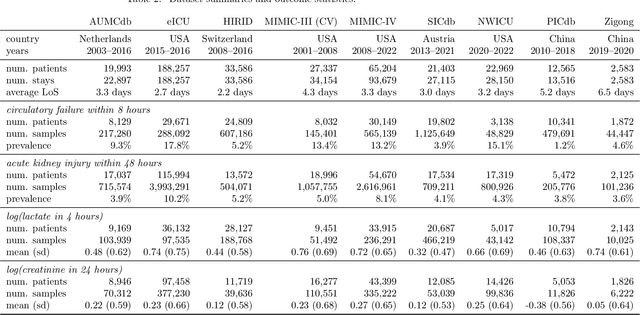
Notable progress has been made in generalist medical large language models across various healthcare areas. However, large-scale modeling of in-hospital time series data - such as vital signs, lab results, and treatments in critical care - remains underexplored. Existing datasets are relatively small, but combining them can enhance patient diversity and improve model robustness. To effectively utilize these combined datasets for large-scale modeling, it is essential to address the distribution shifts caused by varying treatment policies, necessitating the harmonization of treatment variables across the different datasets. This work aims to establish a foundation for training large-scale multi-variate time series models on critical care data and to provide a benchmark for machine learning models in transfer learning across hospitals to study and address distribution shift challenges. We introduce a harmonized dataset for sequence modeling and transfer learning research, representing the first large-scale collection to include core treatment variables. Future plans involve expanding this dataset to support further advancements in transfer learning and the development of scalable, generalizable models for critical healthcare applications.
Random Forests for Change Point Detection
May 10, 2022
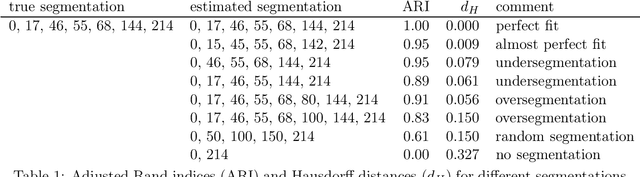

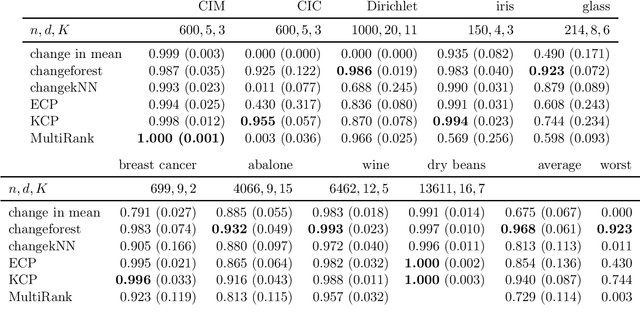
We propose a novel multivariate nonparametric multiple change point detection method using classifiers. We construct a classifier log-likelihood ratio that uses class probability predictions to compare different change point configurations. We propose a computationally feasible search method that is particularly well suited for random forests, denoted by changeforest. However, the method can be paired with any classifier that yields class probability predictions, which we illustrate by also using a k-nearest neighbor classifier. We provide theoretical results motivating our choices. In a large simulation study, our proposed changeforest method achieves improved empirical performance compared to existing multivariate nonparametric change point detection methods. An efficient implementation of our method is made available for R, Python, and Rust users in the changeforest software package.
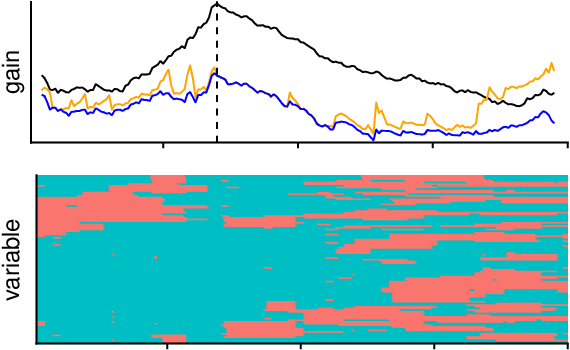
Change point detection for graphical models in presence of missing values
Jul 11, 2019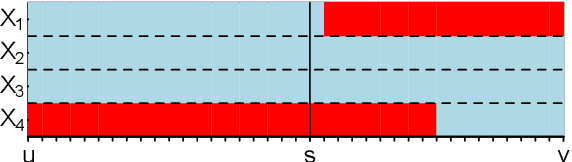


We propose estimation methods for change points in high-dimensional covariance structures with an emphasis on challenging scenarios with missing values. We advocate three imputation like methods and investigate their implications on common losses used for change point detection. We also discuss how model selection methods have to be adapted to the setting of incomplete data. The methods are compared in a simulation study and applied to real data examples from environmental monitoring systems as well as financial time series.