 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-based code embeddings
Jan 01, 2026This paper presents a generic method for transforming the source code of various algorithms to numerical embeddings, by dynamically analysing the behaviour of computer programs against different inputs and by tailoring multiple generic complexity functions for the analysed metrics. The used algorithms embeddings are based on r-Complexity . Using the proposed code embeddings, we present an implementation of the XGBoost algorithm that achieves an average F1-score on a multi-label dataset with 11 classes, built using real-world code snippets submitted for programming competitions on the Codeforces platform.
Semi-Supervised Learning for Large Language Models Safety and Content Moderation
Dec 24, 2025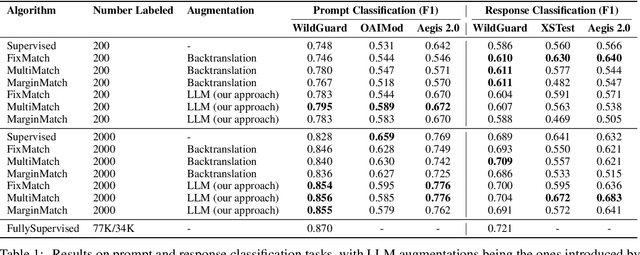
Safety for Large Language Models (LLMs) has been an ongoing research focus since their emergence and is even more relevant nowadays with the increasing capacity of those models. Currently, there are several guardrails in place for all public LLMs and multiple proposed datasets for training safety classifiers. However, training these safety classifiers relies on large quantities of labeled data, which can be problematic to acquire, prone to labeling errors, or often include synthetic data. To address these issues, we suggest a different approach: utilizing semi-supervised learning techniques, which leverage both labeled and unlabeled data, to improve the performance on the safety task. We analyze the improvements that these techniques can offer for both prompts given to Large Language Models and the responses to those requests. Moreover, since augmentation is the central part of semi-supervised algorithms, we demonstrate the importance of using task-specific augmentations, which significantly increase the performance when compared to general-purpose augmentation techniques.
Pluralistic Behavior Suite: Stress-Testing Multi-Turn Adherence to Custom Behavioral Policies
Nov 07, 2025Large language models (LLMs) are typically aligned to a universal set of safety and usage principles intended for broad public acceptability. Yet, real-world applications of LLMs often take place within organizational ecosystems shaped by distinctive corporate policies, regulatory requirements, use cases, brand guidelines, and ethical commitments. This reality highlights the need for rigorous and comprehensive evaluation of LLMs with pluralistic alignment goals, an alignment paradigm that emphasizes adaptability to diverse user values and needs. In this work, we present PLURALISTIC BEHAVIOR SUITE (PBSUITE), a dynamic evaluation suite designed to systematically assess LLMs' capacity to adhere to pluralistic alignment specifications in multi-turn, interactive conversations. PBSUITE consists of (1) a diverse dataset of 300 realistic LLM behavioral policies, grounded in 30 industries; and (2) a dynamic evaluation framework for stress-testing model compliance with custom behavioral specifications under adversarial conditions. Using PBSUITE, We find that leading open- and closed-source LLMs maintain robust adherence to behavioral policies in single-turn settings (less than 4% failure rates), but their compliance weakens substantially in multi-turn adversarial interactions (up to 84% failure rates). These findings highlight that existing model alignment and safety moderation methods fall short in coherently enforcing pluralistic behavioral policies in real-world LLM interactions. Our work contributes both the dataset and analytical framework to support future research toward robust and context-aware pluralistic alignment techniques.
Meta-learning how to Share Credit among Macro-Actions
Jun 16, 2025One proposed mechanism to improve exploration in reinforcement learning is through the use of macro-actions. Paradoxically though, in many scenarios the naive addition of macro-actions does not lead to better exploration, but rather the opposite. It has been argued that this was caused by adding non-useful macros and multiple works have focused on mechanisms to discover effectively environment-specific useful macros. In this work, we take a slightly different perspective. We argue that the difficulty stems from the trade-offs between reducing the average number of decisions per episode versus increasing the size of the action space. Namely, one typically treats each potential macro-action as independent and atomic, hence strictly increasing the search space and making typical exploration strategies inefficient. To address this problem we propose a novel regularization term that exploits the relationship between actions and macro-actions to improve the credit assignment mechanism by reducing the effective dimension of the action space and, therefore, improving exploration. The term relies on a similarity matrix that is meta-learned jointly with learning the desired policy. We empirically validate our strategy looking at macro-actions in Atari games, and the StreetFighter II environment. Our results show significant improvements over the Rainbow-DQN baseline in all environments. Additionally, we show that the macro-action similarity is transferable to related environments. We believe this work is a small but important step towards understanding how the similarity-imposed geometry on the action space can be exploited to improve credit assignment and exploration, therefore making learning more effective.
MultiMatch: Multihead Consistency Regularization Matching for Semi-Supervised Text Classification
Jun 09, 2025



We introduce MultiMatch, a novel semi-supervised learning (SSL) algorithm combining the paradigms of co-training and consistency regularization with pseudo-labeling. At its core, MultiMatch features a three-fold pseudo-label weighting module designed for three key purposes: selecting and filtering pseudo-labels based on head agreement and model confidence, and weighting them according to the perceived classification difficulty. This novel module enhances and unifies three existing techniques -- heads agreement from Multihead Co-training, self-adaptive thresholds from FreeMatch, and Average Pseudo-Margins from MarginMatch -- resulting in a holistic approach that improves robustness and performance in SSL settings. Experimental results on benchmark datasets highlight the superior performance of MultiMatch, achieving state-of-the-art results on 9 out of 10 setups from 5 natural language processing datasets and ranking first according to the Friedman test among 19 methods. Furthermore, MultiMatch demonstrates exceptional robustness in highly imbalanced settings, outperforming the second-best approach by 3.26% -- and data imbalance is a key factor for many text classification tasks.
Safety Through Reasoning: An Empirical Study of Reasoning Guardrail Models
May 26, 2025



Reasoning-based language models have demonstrated strong performance across various domains, with the most notable gains seen in mathematical and coding tasks. Recent research has shown that reasoning also offers significant benefits for LLM safety and guardrail applications. In this work, we conduct a comprehensive analysis of training reasoning-based guardrail models for content moderation, with an emphasis on generalization to custom safety policies at inference time. Our study focuses on two key dimensions: data efficiency and inference efficiency. On the data front, we find that reasoning-based models exhibit strong sample efficiency, achieving competitive performance with significantly fewer training examples than their non-reasoning counterparts. This unlocks the potential to repurpose the remaining data for mining high-value, difficult samples that further enhance model performance. On the inference side, we evaluate practical trade-offs by introducing reasoning budgets, examining the impact of reasoning length on latency and accuracy, and exploring dual-mode training to allow runtime control over reasoning behavior. Our findings will provide practical insights for researchers and developers to effectively and efficiently train and deploy reasoning-based guardrails models in real-world systems.
Aegis2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Jan 15, 2025



As Large Language Models (LLMs) and generative AI become increasingly widespread, concerns about content safety have grown in parallel. Currently, there is a clear lack of high-quality, human-annotated datasets that address the full spectrum of LLM-related safety risks and are usable for commercial applications. To bridge this gap, we propose a comprehensive and adaptable taxonomy for categorizing safety risks, structured into 12 top-level hazard categories with an extension to 9 fine-grained subcategories. This taxonomy is designed to meet the diverse requirements of downstream users, offering more granular and flexible tools for managing various risk types. Using a hybrid data generation pipeline that combines human annotations with a multi-LLM "jury" system to assess the safety of responses, we obtain Aegis 2.0, a carefully curated collection of 34,248 samples of human-LLM interactions, annotated according to our proposed taxonomy. To validate its effectiveness, we demonstrate that several lightweight models, trained using parameter-efficient techniques on Aegis 2.0, achieve performance competitive with leading safety models fully fine-tuned on much larger, non-commercial datasets. In addition, we introduce a novel training blend that combines safety with topic following data.This approach enhances the adaptability of guard models, enabling them to generalize to new risk categories defined during inference. We plan to open-source Aegis 2.0 data and models to the research community to aid in the safety guardrailing of LLMs.
GIT-CXR: End-to-End Transformer for Chest X-Ray Report Generation
Jan 05, 2025



Medical imaging is crucial for diagnosing, monitoring, and treating medical conditions. The medical reports of radiology images are the primary medium through which medical professionals attest their findings, but their writing is time consuming and requires specialized clinical expertise. The automated generation of radiography reports has thus the potential to improve and standardize patient care and significantly reduce clinicians workload. Through our work, we have designed and evaluated an end-to-end transformer-based method to generate accurate and factually complete radiology reports for X-ray images. Additionally, we are the first to introduce curriculum learning for end-to-end transformers in medical imaging and demonstrate its impact in obtaining improved performance. The experiments have been conducted using the MIMIC-CXR-JPG database, the largest available chest X-ray dataset. The results obtained are comparable with the current state-of-the-art on the natural language generation (NLG) metrics BLEU and ROUGE-L, while setting new state-of-the-art results on F1 examples-averaged, F1-macro and F1-micro metrics for clinical accuracy and on the METEOR metric widely used for NLG.
Towards Inference-time Category-wise Safety Steering for Large Language Models
Oct 02, 2024


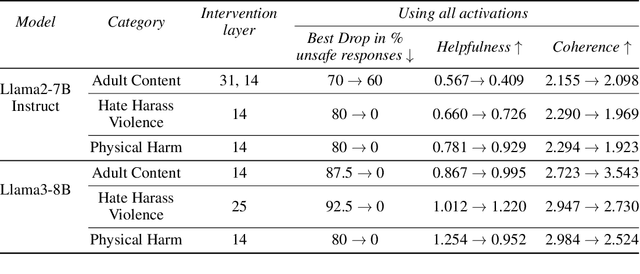
While large language models (LLMs) have seen unprecedented advancements in capabilities and applications across a variety of use-cases, safety alignment of these models is still an area of active research. The fragile nature of LLMs, even models that have undergone extensive alignment and safety training regimes, warrants additional safety steering steps via training-free, inference-time methods. While recent work in the area of mechanistic interpretability has investigated how activations in latent representation spaces may encode concepts, and thereafter performed representation engineering to induce such concepts in LLM outputs, the applicability of such for safety is relatively under-explored. Unlike recent inference-time safety steering works, in this paper we explore safety steering of LLM outputs using: (i) category-specific steering vectors, thereby enabling fine-grained control over the steering, and (ii) sophisticated methods for extracting informative steering vectors for more effective safety steering while retaining quality of the generated text. We demonstrate our exploration on multiple LLMs and datasets, and showcase the effectiveness of the proposed steering method, along with a discussion on the implications and best practices.
"Vorbeşti Româneşte?" A Recipe to Train Powerful Romanian LLMs with English Instructions
Jun 26, 2024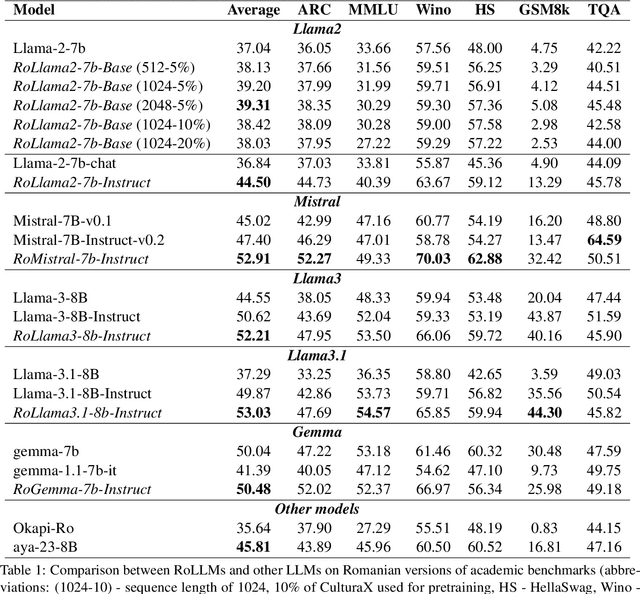
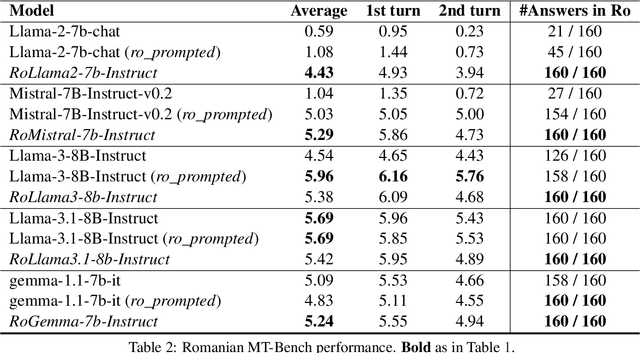
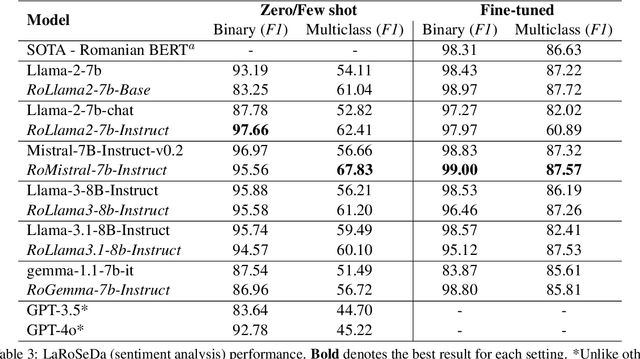
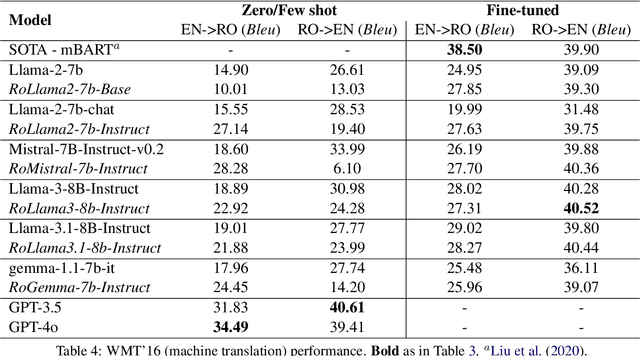
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English; hence, their performance in English greatly exceeds other languages. To our knowledge, we are the first to collect and translate a large collection of texts, instructions, and benchmarks and train, evaluate, and release open-source LLMs tailored for Romanian. We evaluate our methods on four different categories, including academic benchmarks, MT-Bench (manually translated), and a professionally built historical, cultural, and social benchmark adapted to Romanian. We argue for the usefulness and high performance of RoLLMs by obtaining state-of-the-art results across the board. We publicly release all resources (i.e., data, training and evaluation code, models) to support and encourage research on Romanian LLMs while concurrently creating a generalizable recipe, adequate for other low or less-resourced languages.