 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAegis2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Jan 15, 2025



As Large Language Models (LLMs) and generative AI become increasingly widespread, concerns about content safety have grown in parallel. Currently, there is a clear lack of high-quality, human-annotated datasets that address the full spectrum of LLM-related safety risks and are usable for commercial applications. To bridge this gap, we propose a comprehensive and adaptable taxonomy for categorizing safety risks, structured into 12 top-level hazard categories with an extension to 9 fine-grained subcategories. This taxonomy is designed to meet the diverse requirements of downstream users, offering more granular and flexible tools for managing various risk types. Using a hybrid data generation pipeline that combines human annotations with a multi-LLM "jury" system to assess the safety of responses, we obtain Aegis 2.0, a carefully curated collection of 34,248 samples of human-LLM interactions, annotated according to our proposed taxonomy. To validate its effectiveness, we demonstrate that several lightweight models, trained using parameter-efficient techniques on Aegis 2.0, achieve performance competitive with leading safety models fully fine-tuned on much larger, non-commercial datasets. In addition, we introduce a novel training blend that combines safety with topic following data.This approach enhances the adaptability of guard models, enabling them to generalize to new risk categories defined during inference. We plan to open-source Aegis 2.0 data and models to the research community to aid in the safety guardrailing of LLMs.
VLN-Video: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation
Feb 07, 2024



Outdoor Vision-and-Language Navigation (VLN) requires an agent to navigate through realistic 3D outdoor environments based on natural language instructions. The performance of existing VLN methods is limited by insufficient diversity in navigation environments and limited training data. To address these issues, we propose VLN-Video, which utilizes the diverse outdoor environments present in driving videos in multiple cities in the U.S. augmented with automatically generated navigation instructions and actions to improve outdoor VLN performance. VLN-Video combines the best of intuitive classical approaches and modern deep learning techniques, using template infilling to generate grounded navigation instructions, combined with an image rotation similarity-based navigation action predictor to obtain VLN style data from driving videos for pretraining deep learning VLN models. We pre-train the model on the Touchdown dataset and our video-augmented dataset created from driving videos with three proxy tasks: Masked Language Modeling, Instruction and Trajectory Matching, and Next Action Prediction, so as to learn temporally-aware and visually-aligned instruction representations. The learned instruction representation is adapted to the state-of-the-art navigator when fine-tuning on the Touchdown dataset. Empirical results demonstrate that VLN-Video significantly outperforms previous state-of-the-art models by 2.1% in task completion rate, achieving a new state-of-the-art on the Touchdown dataset.
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Nov 24, 2023



Learning from human feedback is a prominent technique to align the output of large language models (LLMs) with human expectations. Reinforcement learning from human feedback (RLHF) leverages human preference signals that are in the form of ranking of response pairs to perform this alignment. However, human preference on LLM outputs can come in much richer forms including natural language, which may provide detailed feedback on strengths and weaknesses of a given response. In this work we investigate data efficiency of modeling human feedback that is in natural language. Specifically, we fine-tune an open-source LLM, e.g., Falcon-40B-Instruct, on a relatively small amount (1000 records or even less) of human feedback in natural language in the form of critiques and revisions of responses. We show that this model is able to improve the quality of responses from even some of the strongest LLMs such as ChatGPT, BARD, and Vicuna, through critique and revision of those responses. For instance, through one iteration of revision of ChatGPT responses, the revised responses have 56.6% win rate over the original ones, and this win rate can be further improved to 65.9% after applying the revision for five iterations.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Multimodal Contextualized Plan Prediction for Embodied Task Completion
May 10, 2023Task planning is an important component of traditional robotics systems enabling robots to compose fine grained skills to perform more complex tasks. Recent work building systems for translating natural language to executable actions for task completion in simulated embodied agents is focused on directly predicting low level action sequences that would be expected to be directly executable by a physical robot. In this work, we instead focus on predicting a higher level plan representation for one such embodied task completion dataset - TEACh, under the assumption that techniques for high-level plan prediction from natural language are expected to be more transferable to physical robot systems. We demonstrate that better plans can be predicted using multimodal context, and that plan prediction and plan execution modules are likely dependent on each other and hence it may not be ideal to fully decouple them. Further, we benchmark execution of oracle plans to quantify the scope for improvement in plan prediction models.
KILM: Knowledge Injection into Encoder-Decoder Language Models
Feb 17, 2023



Large pre-trained language models (PLMs) have been shown to retain implicit knowledge within their parameters. To enhance this implicit knowledge, we propose Knowledge Injection into Language Models (KILM), a novel approach that injects entity-related knowledge into encoder-decoder PLMs, via a generative knowledge infilling objective through continued pre-training. This is done without architectural modifications to the PLMs or adding additional parameters. Experimental results over a suite of knowledge-intensive tasks spanning numerous datasets show that KILM enables models to retain more knowledge and hallucinate less, while preserving their original performance on general NLU and NLG tasks. KILM also demonstrates improved zero-shot performances on tasks such as entity disambiguation, outperforming state-of-the-art models having 30x more parameters.
Dialog Acts for Task-Driven Embodied Agents
Sep 26, 2022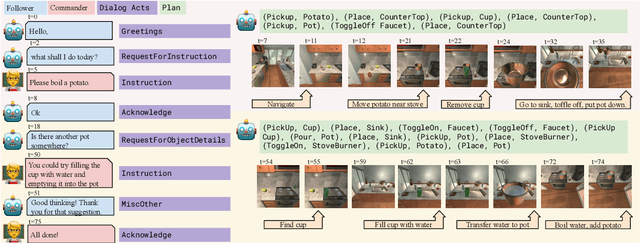
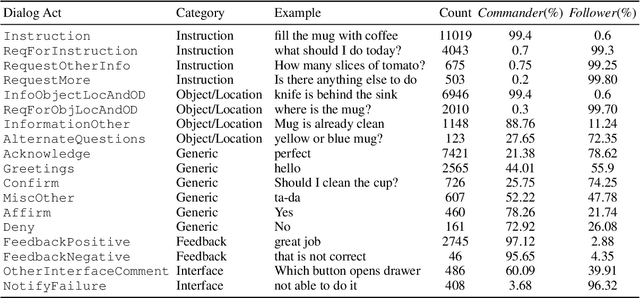

Embodied agents need to be able to interact in natural language understanding task descriptions and asking appropriate follow up questions to obtain necessary information to be effective at successfully accomplishing tasks for a wide range of users. In this work, we propose a set of dialog acts for modelling such dialogs and annotate the TEACh dataset that includes over 3,000 situated, task oriented conversations (consisting of 39.5k utterances in total) with dialog acts. TEACh-DA is one of the first large scale dataset of dialog act annotations for embodied task completion. Furthermore, we demonstrate the use of this annotated dataset in training models for tagging the dialog acts of a given utterance, predicting the dialog act of the next response given a dialog history, and use the dialog acts to guide agent's non-dialog behaviour. In particular, our experiments on the TEACh Execution from Dialog History task where the model predicts the sequence of low level actions to be executed in the environment for embodied task completion, demonstrate that dialog acts can improve end task success rate by up to 2 points compared to the system without dialog acts.
On the Limits of Evaluating Embodied Agent Model Generalization Using Validation Sets
May 18, 2022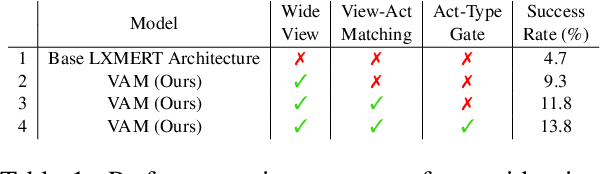
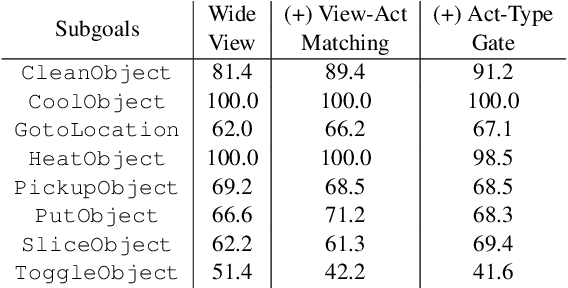
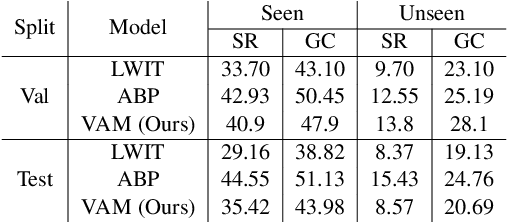
Natural language guided embodied task completion is a challenging problem since it requires understanding natural language instructions, aligning them with egocentric visual observations, and choosing appropriate actions to execute in the environment to produce desired changes. We experiment with augmenting a transformer model for this task with modules that effectively utilize a wider field of view and learn to choose whether the next step requires a navigation or manipulation action. We observed that the proposed modules resulted in improved, and in fact state-of-the-art performance on an unseen validation set of a popular benchmark dataset, ALFRED. However, our best model selected using the unseen validation set underperforms on the unseen test split of ALFRED, indicating that performance on the unseen validation set may not in itself be a sufficient indicator of whether model improvements generalize to unseen test sets. We highlight this result as we believe it may be a wider phenomenon in machine learning tasks but primarily noticeable only in benchmarks that limit evaluations on test splits, and highlights the need to modify benchmark design to better account for variance in model performance.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021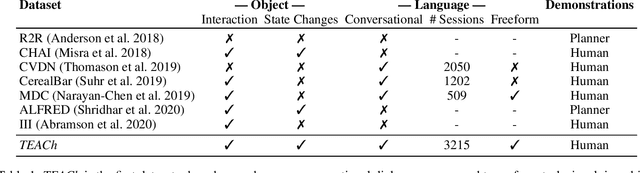
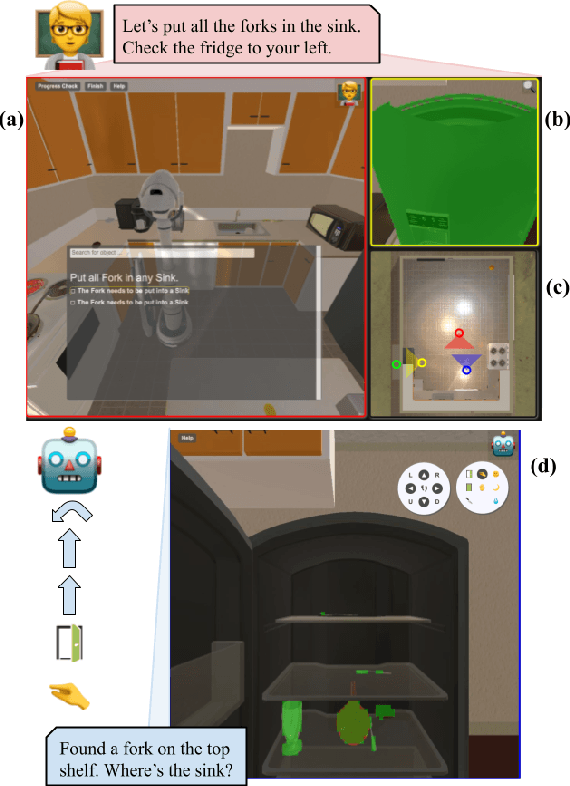
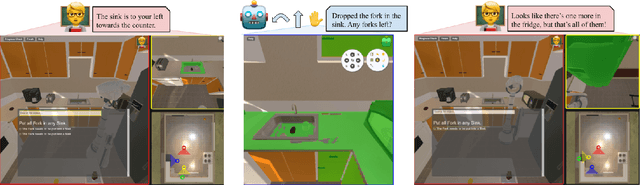
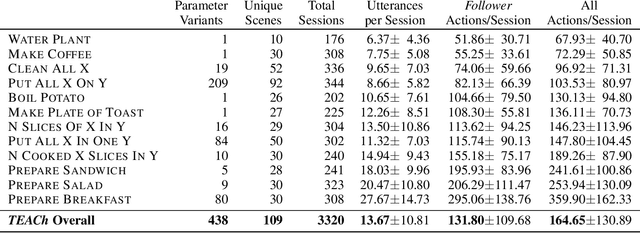
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
Rome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation
Oct 11, 2021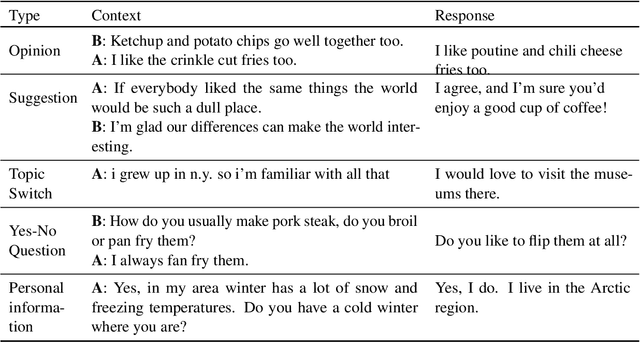
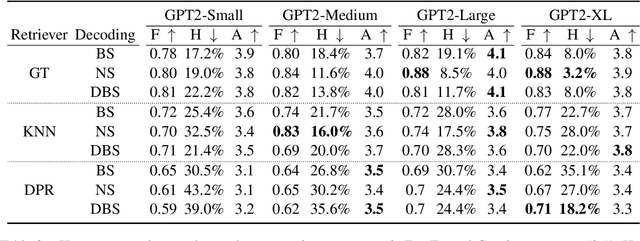


Recently neural response generation models have leveraged large pre-trained transformer models and knowledge snippets to generate relevant and informative responses. However, this does not guarantee that generated responses are factually correct. In this paper, we examine factual correctness in knowledge-grounded neural response generation models. We present a human annotation setup to identify three different response types: responses that are factually consistent with respect to the input knowledge, responses that contain hallucinated knowledge, and non-verifiable chitchat style responses. We use this setup to annotate responses generated using different stateof-the-art models, knowledge snippets, and decoding strategies. In addition, to facilitate the development of a factual consistency detector, we automatically create a new corpus called Conv-FEVER that is adapted from the Wizard of Wikipedia dataset and includes factually consistent and inconsistent responses. We demonstrate the benefit of our Conv-FEVER dataset by showing that the models trained on this data perform reasonably well to detect factually inconsistent responses with respect to the provided knowledge through evaluation on our human annotated data. We will release the Conv-FEVER dataset and the human annotated responses.