 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermEval: A Structured Benchmark for Evaluation of Vision-Language Models on Thermal Imagery
Feb 16, 2026Vision language models (VLMs) achieve strong performance on RGB imagery, but they do not generalize to thermal images. Thermal sensing plays a critical role in settings where visible light fails, including nighttime surveillance, search and rescue, autonomous driving, and medical screening. Unlike RGB imagery, thermal images encode physical temperature rather than color or texture, requiring perceptual and reasoning capabilities that existing RGB-centric benchmarks do not evaluate. We introduce ThermEval-B, a structured benchmark of approximately 55,000 thermal visual question answering pairs designed to assess the foundational primitives required for thermal vision language understanding. ThermEval-B integrates public datasets with our newly collected ThermEval-D, the first dataset to provide dense per-pixel temperature maps with semantic body-part annotations across diverse indoor and outdoor environments. Evaluating 25 open-source and closed-source VLMs, we find that models consistently fail at temperature-grounded reasoning, degrade under colormap transformations, and default to language priors or fixed responses, with only marginal gains from prompting or supervised fine-tuning. These results demonstrate that thermal understanding requires dedicated evaluation beyond RGB-centric assumptions, positioning ThermEval as a benchmark to drive progress in thermal vision language modeling.
Self-Supervised Any-Point Tracking by Contrastive Random Walks
Sep 24, 2024We present a simple, self-supervised approach to the Tracking Any Point (TAP) problem. We train a global matching transformer to find cycle consistent tracks through video via contrastive random walks, using the transformer's attention-based global matching to define the transition matrices for a random walk on a space-time graph. The ability to perform "all pairs" comparisons between points allows the model to obtain high spatial precision and to obtain a strong contrastive learning signal, while avoiding many of the complexities of recent approaches (such as coarse-to-fine matching). To do this, we propose a number of design decisions that allow global matching architectures to be trained through self-supervision using cycle consistency. For example, we identify that transformer-based methods are sensitive to shortcut solutions, and propose a data augmentation scheme to address them. Our method achieves strong performance on the TapVid benchmarks, outperforming previous self-supervised tracking methods, such as DIFT, and is competitive with several supervised methods.
EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata
Jan 11, 2023



We learn a visual representation that captures information about the camera that recorded a given photo. To do this, we train a multimodal embedding between image patches and the EXIF metadata that cameras automatically insert into image files. Our model represents this metadata by simply converting it to text and then processing it with a transformer. The features that we learn significantly outperform other self-supervised and supervised features on downstream image forensics and calibration tasks. In particular, we successfully localize spliced image regions "zero shot" by clustering the visual embeddings for all of the patches within an image.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021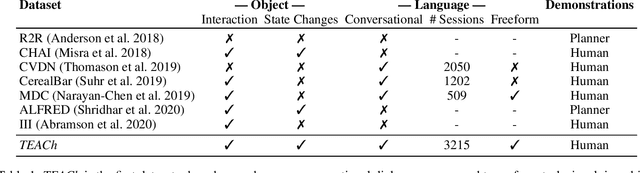
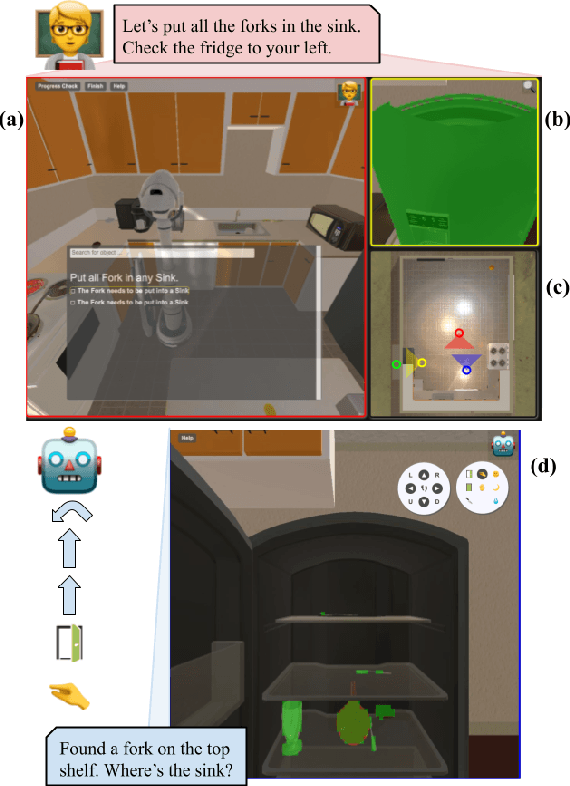
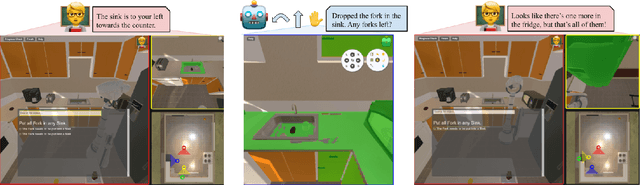
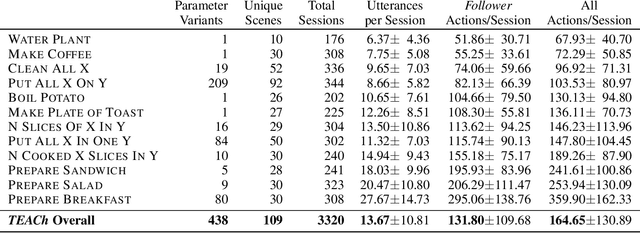
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
May 25, 2021



Interactive robots navigating photo-realistic environments face challenges underlying vision-and-language navigation (VLN), but in addition, they need to be trained to handle the dynamic nature of dialogue. However, research in Cooperative Vision-and-Dialog Navigation (CVDN), where a navigator interacts with a guide in natural language in order to reach a goal, treats the dialogue history as a VLN-style static instruction. In this paper, we present VISITRON, a navigator better suited to the interactive regime inherent to CVDN by being trained to: i) identify and associate object-level concepts and semantics between the environment and dialogue history, ii) identify when to interact vs. navigate via imitation learning of a binary classification head. We perform extensive ablations with VISITRON to gain empirical insights and improve performance on CVDN. VISITRON is competitive with models on the static CVDN leaderboard. We also propose a generalized interactive regime to fine-tune and evaluate VISITRON and future such models with pre-trained guides for adaptability.
Seismic Facies Analysis: A Deep Domain Adaptation Approach
Nov 20, 2020



Deep neural networks (DNNs) can learn accurately from large quantities of labeled input data, but DNNs sometimes fail to generalize to test data sampled from different input distributions. Unsupervised Deep Domain Adaptation (DDA) proves useful when no input labels are available, and distribution shifts are observed in the target domain (TD). Experiments are performed on seismic images of the F3 block 3D dataset from offshore Netherlands (source domain; SD) and Penobscot 3D survey data from Canada (target domain; TD). Three geological classes from SD and TD that have similar reflection patterns are considered. In the present study, an improved deep neural network architecture named EarthAdaptNet (EAN) is proposed to semantically segment the seismic images. We specifically use a transposed residual unit to replace the traditional dilated convolution in the decoder block. The EAN achieved a pixel-level accuracy >84% and an accuracy of ~70% for the minority classes, showing improved performance compared to existing architectures. In addition, we introduced the CORAL (Correlation Alignment) method to the EAN to create an unsupervised deep domain adaptation network (EAN-DDA) for the classification of seismic reflections fromF3 and Penobscot. Maximum class accuracy achieved was ~99% for class 2 of Penobscot with >50% overall accuracy. Taken together, EAN-DDA has the potential to classify target domain seismic facies classes with high accuracy.
Sim-to-Real Transfer for Vision-and-Language Navigation
Nov 07, 2020



We study the challenging problem of releasing a robot in a previously unseen environment, and having it follow unconstrained natural language navigation instructions. Recent work on the task of Vision-and-Language Navigation (VLN) has achieved significant progress in simulation. To assess the implications of this work for robotics, we transfer a VLN agent trained in simulation to a physical robot. To bridge the gap between the high-level discrete action space learned by the VLN agent, and the robot's low-level continuous action space, we propose a subgoal model to identify nearby waypoints, and use domain randomization to mitigate visual domain differences. For accurate sim and real comparisons in parallel environments, we annotate a 325m2 office space with 1.3km of navigation instructions, and create a digitized replica in simulation. We find that sim-to-real transfer to an environment not seen in training is successful if an occupancy map and navigation graph can be collected and annotated in advance (success rate of 46.8% vs. 55.9% in sim), but much more challenging in the hardest setting with no prior mapping at all (success rate of 22.5%).
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
May 01, 2020



Following a navigation instruction such as 'Walk down the stairs and stop at the brown sofa' requires embodied AI agents to ground scene elements referenced via language (e.g. 'stairs') to visual content in the environment (pixels corresponding to 'stairs'). We ask the following question -- can we leverage abundant 'disembodied' web-scraped vision-and-language corpora (e.g. Conceptual Captions) to learn visual groundings (what do 'stairs' look like?) that improve performance on a relatively data-starved embodied perception task (Vision-and-Language Navigation)? Specifically, we develop VLN-BERT, a visiolinguistic transformer-based model for scoring the compatibility between an instruction ('...stop at the brown sofa') and a sequence of panoramic RGB images captured by the agent. We demonstrate that pretraining VLN-BERT on image-text pairs from the web before fine-tuning on embodied path-instruction data significantly improves performance on VLN -- outperforming the prior state-of-the-art in the fully-observed setting by 4 absolute percentage points on success rate. Ablations of our pretraining curriculum show each stage to be impactful -- with their combination resulting in further positive synergistic effects.
Chasing Ghosts: Instruction Following as Bayesian State Tracking
Jul 03, 2019



A visually-grounded navigation instruction can be interpreted as a sequence of expected observations and actions an agent following the correct trajectory would encounter and perform. Based on this intuition, we formulate the problem of finding the goal location in Vision-And-Language Navigation (VLN) within the framework of Bayesian state tracking - learning observation and motion models conditioned on these expectable events. Together with a mapper that constructs a semantic spatial map on-the-fly during navigation, we formulate an end-to-end differentiable Bayes filter and train it to identify the goal by predicting the most likely trajectory through the map according to the instructions. The resulting navigation policy constitutes a new approach to instruction following that explicitly models a probability distribution over states, encoding strong geometric and algorithmic priors while enabling greater explainability. Our experiments show that our approach outperforms strong baselines when predicting the goal location in VLN.